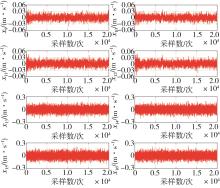
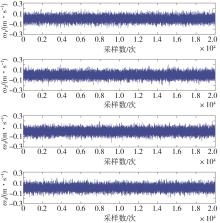
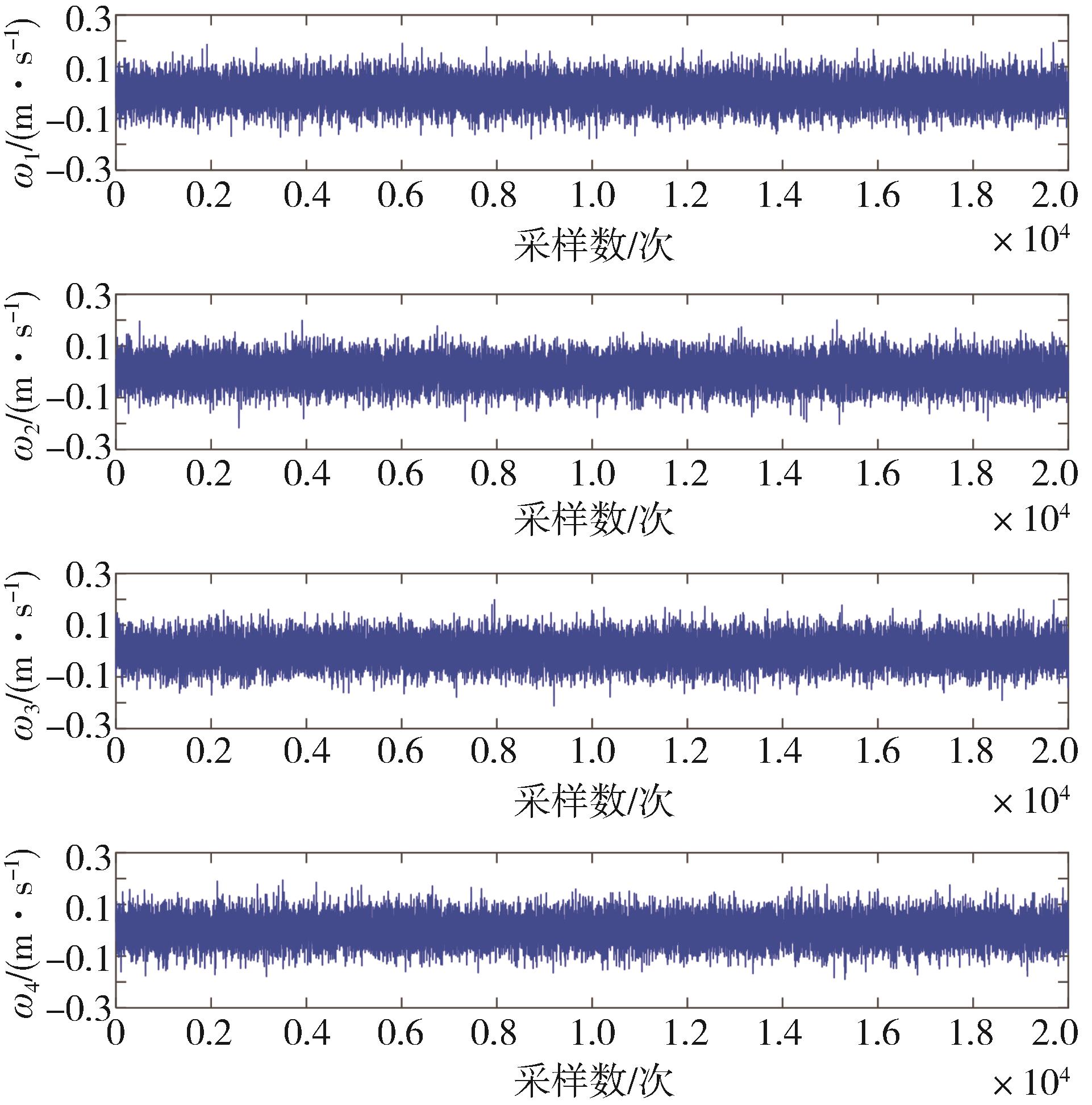
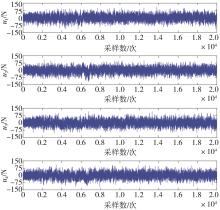
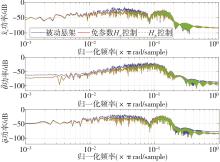
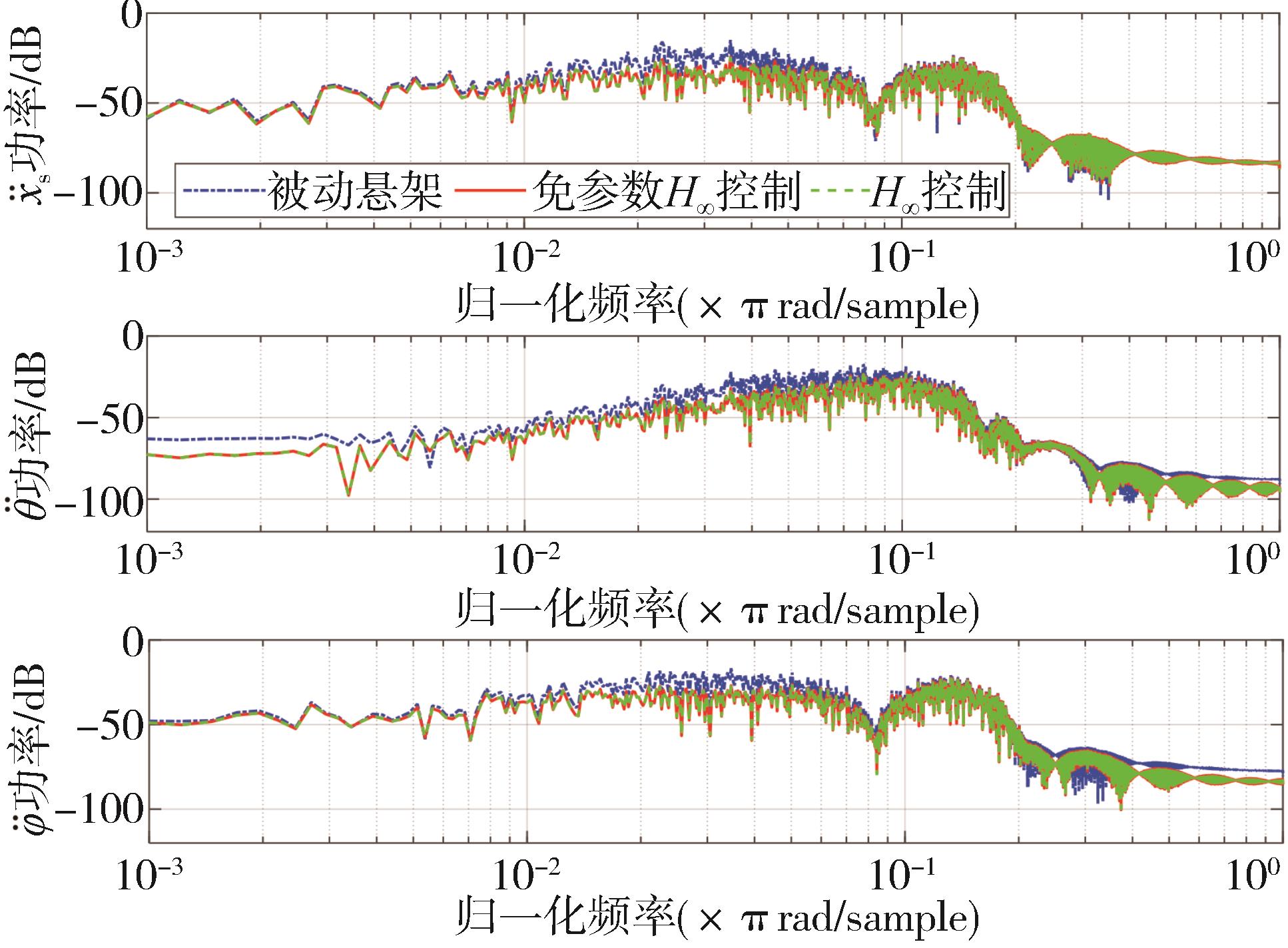
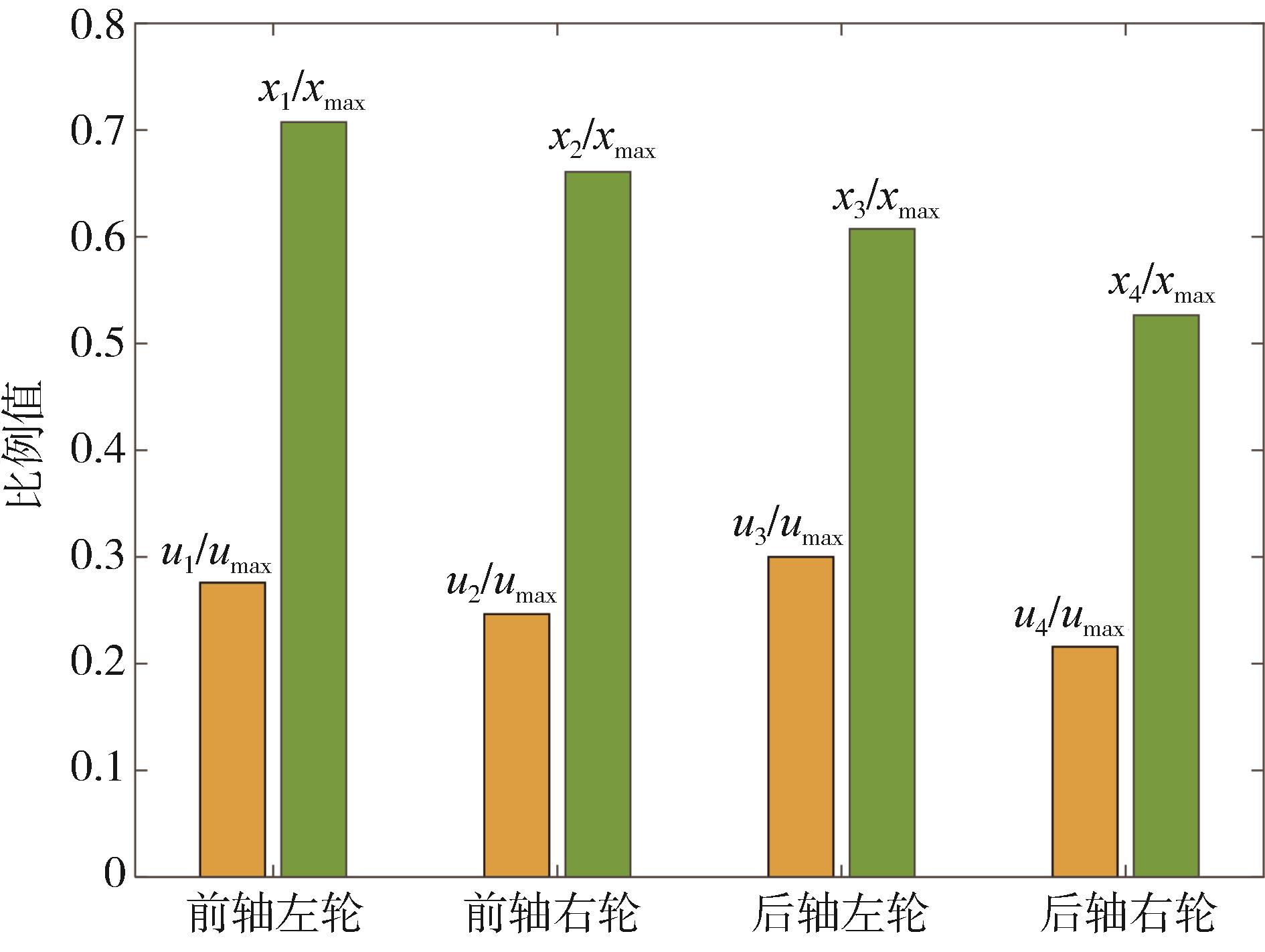
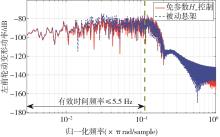
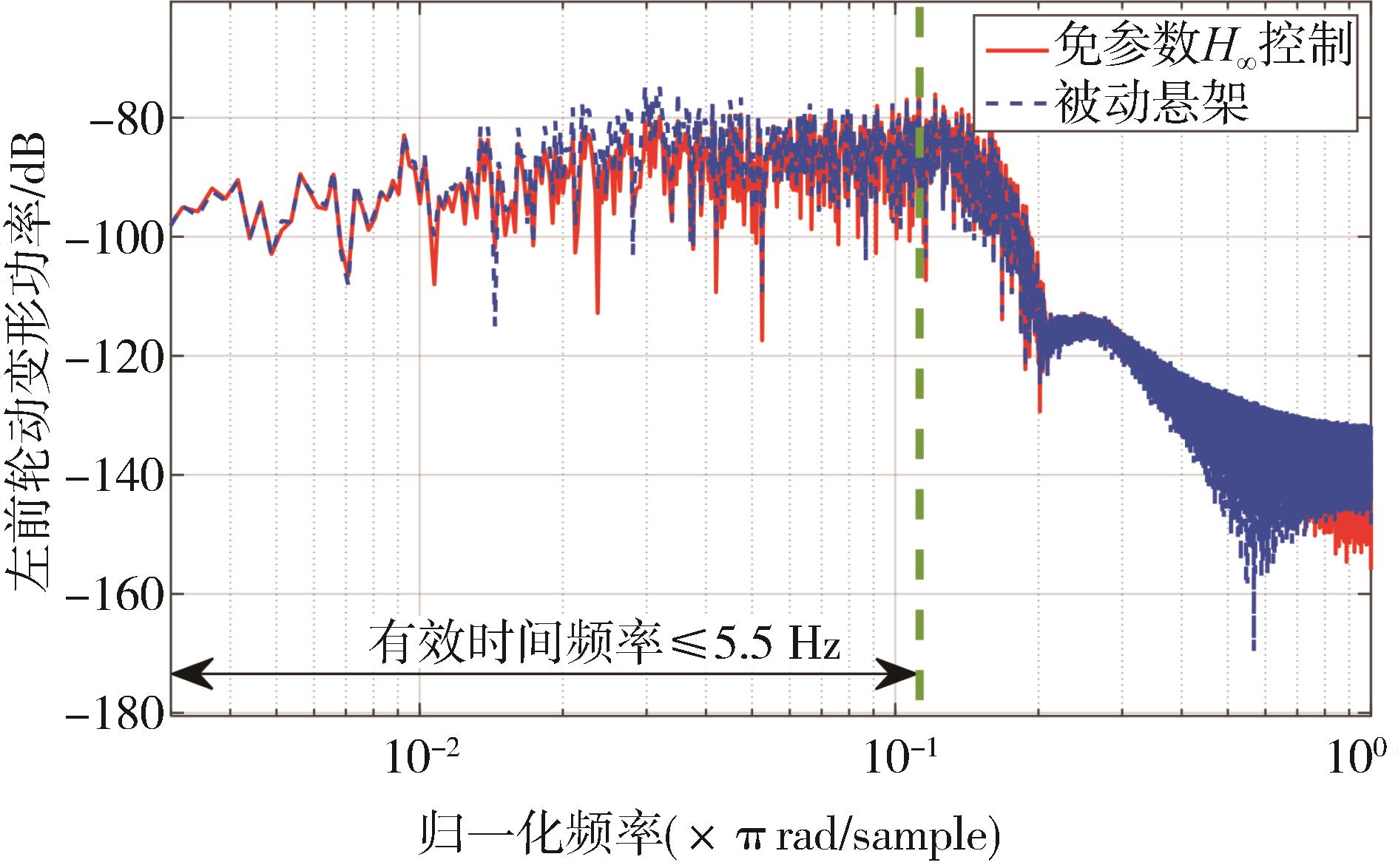
| 1 |
孙晓东, 蔡峰, 蔡英凤,等. 主动悬架用直线电机模型预测推力控制[J]. 中国公路学报, 2021, 34(9): 85-100.
|
|
SUN X D, CAI F, CAI Y F, et al. Improved model predictive thrust-force control of linear motors for active suspensions[J]. China Journal of Highway and Transport, 2021, 34(9): 85-100.
|
| 2 |
汪若尘, 谢健, 叶青, 等. 直线电机式主动悬架建模与试验研究[J]. 汽车工程, 2016, 38(4): 495-499.
|
|
WANG R C, XIE J, YE Q, et al. Modeling and experimental study of active suspension with linear motor[J]. Automotive Engineering, 2016, 38(4): 495-499.
|
| 3 |
寇发荣, 张海亮, 许家楠, 等. 电动静液压主动悬架自适应Smith反馈时滞控制[J]. 振动、测试与诊断,2022,42(5):864-870,1030.
|
|
KOU F R, ZHANG H L, XU J N, et al. Electrostatic active suspension adapts to smith feedback delay control[J]. Journal of Vibration, Measurement & Diagnosis, 2022, 42(5): 864-870,1030.
|
| 4 |
黄英博, 吕永峰, 赵刚, 等. 非线性主动悬架系统自适应最优控制[J]. 控制与决策, 2022, 37(12): 3197-3206.
|
|
HUANG Y B, LV Y F, ZHAO G, et al. Adaptive optimal control for nonlinear active suspension systems[J]. Control and Decision, 2022, 37(12): 3197-3206.
|
| 5 |
郝梦俊. 基于路面信息识别的汽车主动悬架模型预测控制[D].重庆: 重庆大学, 2021.
|
|
HAO M J. Model predictive control of active suspension based on road information recognition[D]. Chongqing: Chongqing University, 2021.
|
| 6 |
李仲兴, 李忠远, 刘晨来. 基于显式模型预测控制的轮毂驱动电动车垂向振动研究[J]. 振动与冲击, 2022, 41(11): 259-265.
|
|
LI Z X, LI Z Y, LIU C L. Vertical vibration of hub motor driven electric vehicle based on EMPC[J]. Journal of Vibration and Shock, 2022, 41(11): 259-265.
|
| 7 |
李韶华, 张培强, 杨建森. 轮毂电机驱动电动汽车主动悬架T-S变论域模糊控制研究[J]. 振动与冲击, 2022, 41(24): 201-209.
|
|
LI S H, ZHAO P Q, YANG J S. Research on T-S variable domain fuzzy control of active suspension on the electric vehicle driven by an in-wheel motor[J]. Journal of Vibration and Shock, 2022, 41(24): 201-209.
|
| 8 |
李杰, 贾长旺, 成林海, 等. 脉冲路面下电动汽车主动悬架状态反馈 H∞ 控制[J]. 湖南大学学报 (自然科学版), 2022, 49(8): 12-20.
|
|
LI J, JIA C W, CHENG L H, et al. State feedback H∞ control for active suspension of electric vehicles on pulse road[J]. Journal of Hunan University (Natural Sciences), 2022, 49(8): 12-20.
|
| 9 |
汪洪波, 林澍, 孙晓文, 等. 基于可拓理论的汽车主动悬架系统H∞控制与优化[J]. 汽车工程, 2016, 38(11): 1382-1390.
|
|
WANG H B, LIN S, SUN X W, et al. H∞ control and optimization for vehicle active suspension system based on extension theory[J]. Automotive Engineering, 2016, 38(11): 1382-1390.
|
| 10 |
纪仁杰, 方明霞, 李佩琳, 等. 含时滞悬架系统 H∞ 控制的理论与实验研究[J]. 汽车工程, 2020, 42(3): 339-344.
|
|
JI R J, FANG M X, LI P L, et al. Theoretical and experimental research on H∞ control suspension system with time delay[J]. Automotive Engineering, 2020, 42(3): 339-344.
|
| 11 |
庞辉, 王延, 刘凡. 考虑参数不确定性的主动悬架H2/H∞ 保性能控制[J]. 控制与决策, 2019, 34(3): 470-478.
|
|
PANG H, WANG Y, LIU F. H2/H∞ guaranteed cost control for active suspensions considering parameter uncertainty[J]. Control and Decision, 2019, 34(3): 470-478.
|
| 12 |
周兵, 吴晓建, 文桂林, 等. 基于μ综合的整车主动悬架鲁棒控制研究[J]. 振动工程学报, 2017, 30(6): 1029-1037.
|
|
ZHOU B, WU X J, WEN G L, et al. Research on robust control of active suspension of the whole vehicle based on μ synthesis[J]. Journal of Vibration Engineering,2017, 30(6): 1029-1037.
|
| 13 |
JING H, WANG R, LI C, et al. Robust finite-frequency H∞ control of full-car active suspension[J]. Journal of Sound and Vibration, 2019, 441: 221-239.
|
| 14 |
荣吉利, 邓增琨, 何丽, 等. 整车主动悬架平顺性时域仿真与优化[J]. 北京理工大学学报, 2022, 42(1): 46-52.
|
|
RONG J L, DENG Z K, HE L, et al. Time domain simulation and optimization of ride comfort for vehicle active suspension[J]. Transactions of Beijing Institute of Technology, 2022, 42(1): 46-52.
|
| 15 |
LUO B, LIU D, HUANG T, et al. Model-free optimal tracking control via critic-only Q-learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(10): 2134-2144.
|
| 16 |
JIANG Y, KIUMARSI B, FAN J, et al. Optimal output regulation of linear discrete-time systems with unknown dynamics using reinforcement learning[J]. IEEE Transactions on Cybernetics, 2019, 50(7): 3147-3156.
|
| 17 |
PENG Y, CHEN Q, SUN W. Reinforcement Q-learning algorithm for H∞ tracking control of unknown discrete-time linear systems[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 50(11): 4109-4122.
|
| 18 |
LUO B, YANG Y, LIU D. Policy iteration Q-learning for data-based two-player zero-sum game of linear discrete-time systems[J]. IEEE Transactions on Cybernetics, 2020, 51(7): 3630-3640.
|
| 19 |
LI P, LAM J, CHEUNG K C. Velocity-dependent multi-objective control of vehicle suspension with preview measurements[J]. Mechatronics, 2014, 24(5): 464-475.
|
| 20 |
汽车平顺性试验方法: GB/T 4970—2009[S]. 2009.
|
|
Test method for smoothness of automobiles: GB/T 4970—2009[S]. 2009.
|
| 21 |
陈杰平, 陈无畏, 祝辉, 等. 基于Matlab/Simulink的随机路面建模与不平度仿真[J]. 农业机械学报, 2010, 41(3): 11-15.
|
|
CHEN J P, CHEN W W, ZHU H, et al. Modeling and simulation on stochastic road surface irregularity based on Matlab/Simulink[J]. Transactions of the Chinese Society for Agricultural Machinery, 2010, 41(3): 11-15.
|
 ),刘溯奇
),刘溯奇