Administrator by China Associction for Science and Technology
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Automotive Engineering ›› 2023, Vol. 45 ›› Issue (5): 759-767.doi: 10.19562/j.chinasae.qcgc.2023.05.005
Special Issue: 智能网联汽车技术专题-感知&HMI&测评2023年
Previous Articles Next Articles
Lisheng Jin,Bingdong Ji,Baicang Guo( )
)
Received:2022-10-16
Revised:2022-11-25
Online:2023-05-25
Published:2023-05-26
Contact:
Baicang Guo
E-mail:guobaicang@ysu.edu.cn
Lisheng Jin,Bingdong Ji,Baicang Guo. Driver’s Attention Prediction Based on Multi-Level Temporal-Spatial Fusion Network[J].Automotive Engineering, 2023, 45(5): 759-767.
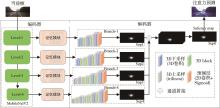
"

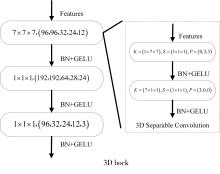
"
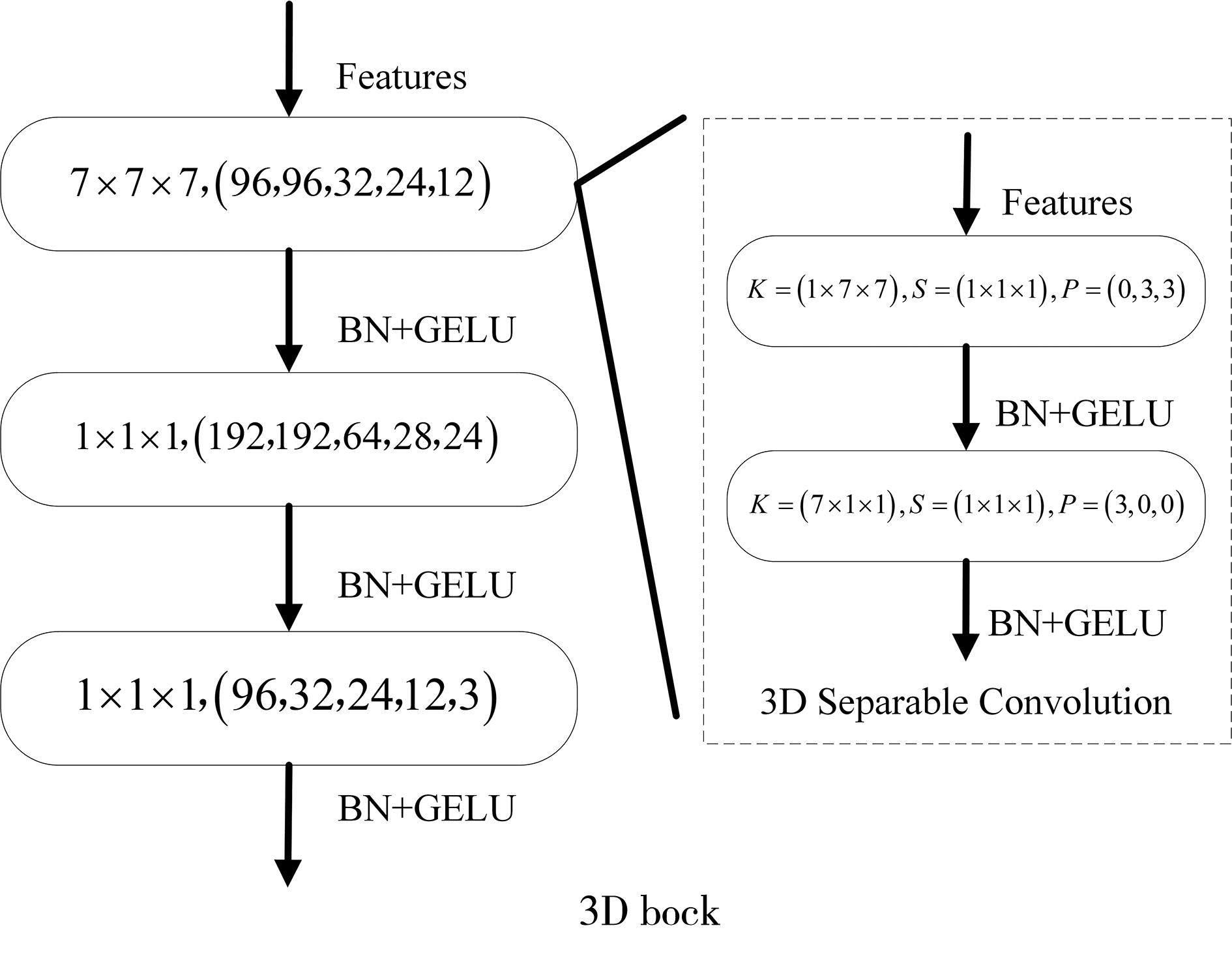

"

"
| 模型 | 注视图 | 显著图 | ||||
|---|---|---|---|---|---|---|
| NSS↑ | AUC-J↑ | s-AUC↑ | SIM↑ | CC ↑ | KL ↓ | |
| SALICON[ | 2.71 | 0.91 | 0.65 | 0.30 | 0.43 | 2.17 |
| Two-Stream[ | 1.48 | 0.84 | 0.64 | 0.14 | 0.23 | 2.85 |
| MLNet[ | 0.30 | 0.59 | 0.54 | 0.07 | 0.04 | 11.78 |
| BDD-A[ | 2.15 | 0.86 | 0.63 | 0.25 | 0.33 | 3.32 |
| DR(eye)VE[ | 2.92 | 0.91 | 0.64 | 0.32 | 0.45 | 2.27 |
| ACLNet[ | 3.15 | 0.91 | 0.64 | 0.35 | 0.48 | 2.51 |
| SCAFNet[ | 3.34 | 0.92 | 0.66 | 0.37 | 0.50 | 2.19 |
| ASIAF-Net[ | 3.39 | 0.93 | 0.78 | 0.36 | 0.49 | 1.66 |
| 本文 | 3.34 | 0.93 | 0.79 | 0.36 | 0.50 | 1.64 |
"
| 模型 | 注视图 | 显著图 | ||||
|---|---|---|---|---|---|---|
| NSS↑ | AUC-J↑ | AUC-B↑ | SIM↑ | CC↑ | KL↓ | |
| Human | 6.482 7 | 0.986 3 | 0.957 8 | 1.0 | 1.0 | 0 |
| ITTI[ | 0.862 7 | 0.725 6 | 0.702 3 | 0.173 6 | 0.166 8 | 2.141 8 |
| GBVS[ | 1.836 3 | 0.907 6 | 0.894 2 | 0.522 3 | 0.366 5 | 1.748 4 |
| HFT[ | 0.972 9 | 0.732 9 | 0.701 5 | 0.168 7 | 0.175 0 | 2.557 9 |
| MLNet[ | 5.694 2 | 0.895 7 | 0.873 4 | 0.451 6 | 0.866 6 | 0.870 9 |
| CDNN[ | 5.828 8 | 0.974 5 | 0.926 1 | 0.777 9 | 0.945 1 | 0.289 7 |
| SCAFNet[ | 6.10 | 0.98 | 0.77 | 0.94 | 0.66 | |
| ASIAF-Net[ | 6.013 4 | 0.971 2 | 0.920 0 | 0.816 6 | 0.956 2 | 0.244 8 |
| 本文 | 5.711 6 | 0.973 2 | 0.931 8 | 0.796 3 | 0.947 0 | 0.281 9 |
"
| 模型 | 模型尺寸/MB | 运行时间/s |
|---|---|---|
| SALICON[ | 117 | 0.5 |
| Two-Stream[ | 315 | 20 |
| ITTI[ | 0.9 | |
| GBVS[ | 2.7 | |
| ACLNet[ | 250 | 0.02 |
| DR(eye)VE[ | 155 | 0.03 |
| 本文 | 19 | 0.02 |

"

"
| 时间长度 | 注视图 | 显著图 | ||||
|---|---|---|---|---|---|---|
| NSS↑ | AUC-J↑ | AUC-B↑ | SIM↑ | CC↑ | KL↓ | |
| 3.305 | 0.929 | 0.830 | 0.350 | 0.496 | 1.653 | |
| 3.305 | 0.930 | 0.834 | 0.354 | 0.496 | 1.649 | |
| 3.339 | 0.932 | 0.825 | 0.357 | 0.499 | 1.639 | |
"
| 监督层级 | 注视图 | 显著图 | ||||
|---|---|---|---|---|---|---|
| NSS↑ | AUC-J↑ | AUC-B↑ | SIM↑ | CC↑ | KL↓ | |
| Sup4 | 3.128 | 0.925 | 0.858 | 0.314 | 0.478 | 1.728 |
| Sup3 | 3.184 | 0.925 | 0.824 | 0.342 | 0.478 | 1.731 |
| Sup2 | 2.885 | 0.921 | 0.876 | 0.263 | 0.446 | 1.820 |
| Sup1 | 2.582 | 0.901 | 0.844 | 0.239 | 0.397 | 2.010 |
| Sup0 | 3.339 | 0.932 | 0.825 | 0.357 | 0.499 | 1.639 |
"
| 算法设置 | 注视图 | 显著图 | ||||
|---|---|---|---|---|---|---|
| NSS↑ | AUC-J↑ | AUC-B↑ | SIM↑ | CC↑ | KL↓ | |
| 基线 | 3.316 | 0.929 | 0.831 | 0.349 | 0.497 | 1.654 |
| 基线+大卷积核 | 3.322 | 0.930 | 0.850 | 0.336 | 0.498 | 1.640 |
| 本文 | 3.339 | 0.932 | 0.825 | 0.357 | 0.499 | 1.639 |
| 1 | GUO B, JIN L, SUN D, et al. Establishment of the characteristic evaluation index system of secondary task driving and analyzing its importance[J]. Transportation Research Part F: Traffic Psychology and Behaviour, 2019, 64: 308-317. |
| 2 | 刘军, 陈岚磊, 李汉冰. 基于类人视觉的多任务交通目标实时检测模型[J]. 汽车工程, 2021, 43(1):50-58. |
| LIU J, CHEN L L, LI H B. A real⁃time detection model for multi⁃task traffic objects based on humanoid vision[J]. Automotive Engineering, 2021, 43(1): 50-58. | |
| 3 | FRIDMAN L. Human-centered autonomous vehicle systems: Principles of effective shared autonomy[J]. arXiv Preprint arXiv:,2018. |
| 4 | WOLFE J M, HOROWITZ T S. Five factors that guide attention in visual search[J]. Nature Human Behaviour, 2017, 1(3): 1-8. |
| 5 | WANG W, SHEN J, GUO F, et al. Revisiting video saliency: a large-scale benchmark and a new model[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4894-4903. |
| 6 | HUO D, MA J, CHANG R. Lane-changing-decision characteristics and the allocation of visual attention of drivers with an angry driving style[J]. Transportation Research Part F: Traffic Psychology and Behaviour, 2020, 71: 62-75. |
| 7 | KIRCHER K, AHLSTROM C. Minimum required attention: a human-centered approach to driver inattention[J]. Human Factors, 2017, 59(3): 471-484. |
| 8 | CAVANAGH P, ALVAREZ G A. Tracking multiple targets with multifocal attention[J]. Trends in Cognitive Sciences, 2005, 9(7): 349-354. |
| 9 | 陈骥驰, 王宏, 王翘秀, 等. 基于脑电信号的疲劳驾驶状态研究[J]. 汽车工程, 2018, 40(5): 515-520. |
| CHEN J C, WANG H, WANG Q X, et al. A study on drowsy driving state based on EEG signals[J]. Automotive Engineering, 2018, 40(5): 515-520. | |
| 10 | 华强, 金立生, 郭柏苍, 等. 一种混行环境下驾驶人认知分心识别方法[J]. 吉林大学学报(工学版), 2022, 52(8): 1800-1807. |
| HUA Q, JIN L S, GUO B C, et al. A recognition method for driver’s cognitive distraction in simulated mixed traffic environment[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(8): 1800-1807. | |
| 11 | 马勇, 付锐.驾驶人视觉特性与行车安全研究进展[J].中国公路学报,2015,28(6):82-94. |
| MA Y, FU R. Research and development of drivers visual behavior and driving safety[J]. China Journal of Highway and Transport, 2015, 28(6): 82-94. | |
| 12 | ALLETTO S, PALAZZI A, SOLERA F, et al. DR (eye) VE: a dataset for attention-based tasks with applications to autonomous and assisted driving[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2016: 54-60. |
| 13 | PALAZZI A, SOLERA F, CALDERARA S, et al. Learning where to attend like a human driver[C]. 2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017: 920-925. |
| 14 | PALAZZI A, ABATI D, SOLERA F, et al. Predicting the driver's focus of attention: the DR (eye) VE project[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(7): 1720-1733. |
| 15 | XU H, GAO Y, YU F, et al. End-to-end learning of driving models from large-scale video datasets[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2174-2182. |
| 16 | XIA Y, ZHANG D, KIM J, et al. Predicting driver attention in critical situations[C]. Asian Conference on Computer Vision. Springer, Cham, 2018: 658-674. |
| 17 | DENG T, YAN H, QIN L, et al. How do drivers allocate their potential attention? driving fixation prediction via convolutional neural networks[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(5): 2146-2154. |
| 18 | FANG J, YAN D, QIAO J, et al. Dada-2000: can driving accident be predicted by driver attentionƒ analyzed by a benchmark[C]. 2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE, 2019: 4303-4309. |
| 19 | FANG J, YAN D, QIAO J, et al. DADA: driver attention prediction in driving accident scenarios[J]. IEEE Transactions on Intelligent Transportation Systems, 2021. |
| 20 | LI Q, LIU C, CHANG F, et al. Adaptive short-temporal induced aware fusion network for predicting attention regions like a driver[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(10): 18695-18706. |
| 21 | CHANG Q, ZHU S. Temporal-spatial feature pyramid for video saliency detection[J]. arXiv Preprint arXiv:, 2021. |
| 22 | WANG Z, LIU Z, LI G, et al. Spatio-temporal self-attention network for video saliency prediction[J]. IEEE Transactions on Multimedia, 2021. |
| 23 | BELLITTO G, PROIETTO SALANITRI F, PALAZZO S, et al. Hierarchical domain-adapted feature learning for video saliency prediction[J]. International Journal of Computer Vision, 2021, 129(12): 3216-3232. |
| 24 | SANDLER M, HOWARD A, ZHU M, et al. Mobilenetv2: inverted residuals and linear bottlenecks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520. |
| 25 | LIU Z, MAO H, WU C Y, et al. A convnet for the 2020s[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 11976-11986. |
| 26 | XIE S, SUN C, HUANG J, et al. Rethinking spatiotemporal feature learning: speed-accuracy trade-offs in video classification[C]. Proceedings of the European Conference on Computer Vision (ECCV), 2018: 305-321. |
| 27 | BYLINSKII Z, JUDD T, OLIVA A, et al. What do different evaluation metrics tell us about saliency models?[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(3): 740-757. |
| 28 | ITTI L, KOCH C. Computational modelling of visual attention[J]. Nature Reviews Neuroscience, 2001, 2(3): 194-203. |
| 29 | HUANG X, SHEN C, BOIX X, et al. Salicon: reducing the semantic gap in saliency prediction by adapting deep neural networks[C]. Proceedings of the IEEE International Conference on Computer Vision, 2015: 262-270. |
| 30 | HAREL J, KOCH C, PERONA P. Graph-based visual saliency[J]. Advances in Neural Information Processing Systems, 2006, 19. |
| 31 | LI J, LEVINE M D, AN X, et al. Visual saliency based on scale-space analysis in the frequency domain[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 35(4): 996-1010. |
| 32 | CORNIA M, BARALDI L, SERRA G, et al. A deep multi-level network for saliency prediction[C]. 2016 23rd International Conference on Pattern Recognition (ICPR). IEEE, 2016: 3488-3493. |
| 33 | ZHANG K, CHEN Z. Video saliency prediction based on spatial-temporal two-stream network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 29(12): 3544-3557. |
| 34 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778. |
| [1] | Yaoyu Fu, Erzhen Zhou, Ruiyang Ding, Yunbo Zhou, Tiaoqi Fu, Ming Zhang. Dynamic Response of Occupant's Neck During Rolling of a Vehicle [J]. Automotive Engineering, 2023, 45(7): 1276-1285. |
| [2] | Xia Zhao,Zhao Li,Rui Fu,Zhenzhen Ge,Chang Wang. Real-Time Detection of Distracted Driving Behavior Based on Deep Convolution-Tokens Dimensionality Reduction Optimized Visual Transformer Model [J]. Automotive Engineering, 2023, 45(6): 974-988. |
| [3] | Peilong Shi,Xuan Zhao,Zitong Chen,Qiang Yu. Study on Active Control of Exhaust Brake System for Heavy-duty Truck Based on Road Driving Condition Recognition [J]. Automotive Engineering, 2023, 45(1): 104-111. |
| [4] | Zou Tiefang, Wang Guan, Hu Lin, Wu Hequan. Comparative Study on the Injury Difference Between Motorcyclist and Occupant in Vehicle-motorcycle Collision Accidents [J]. Automotive Engineering, 2020, 42(5): 621-627. |
|