Administrator by China Associction for Science and Technology
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Automotive Engineering ›› 2022, Vol. 44 ›› Issue (5): 691-700.doi: 10.19562/j.chinasae.qcgc.2022.05.006
Special Issue: 智能网联汽车技术专题-规划&控制2022年
Previous Articles Next Articles
He Huang1,2( ),Wenlong Li1,2,Lan Yang1,Huifeng Wang1,Biao Wang1,Feng Ru1,2
),Wenlong Li1,2,Lan Yang1,Huifeng Wang1,Biao Wang1,Feng Ru1,2
Received:2021-11-22
Revised:2021-12-19
Online:2022-05-25
Published:2022-05-27
Contact:
He Huang
E-mail:huanghe@chd.edu.cn
He Huang,Wenlong Li,Lan Yang,Huifeng Wang,Biao Wang,Feng Ru. K-means Complementary Iterative Vehicle Information Data Clustering Based on DHSSA Optimization[J].Automotive Engineering, 2022, 44(5): 691-700.
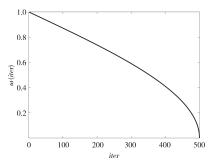
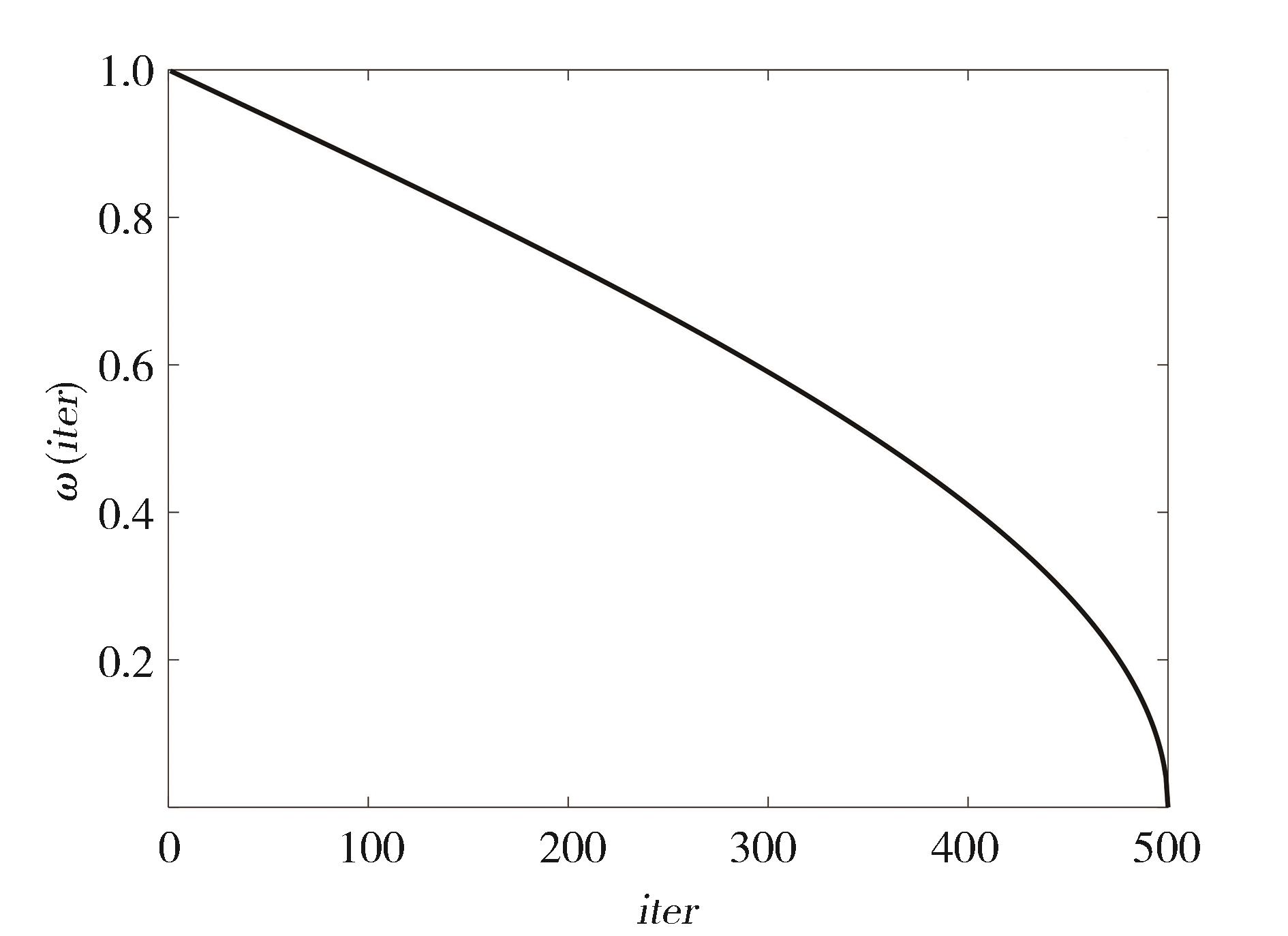
"
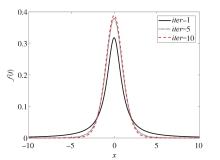
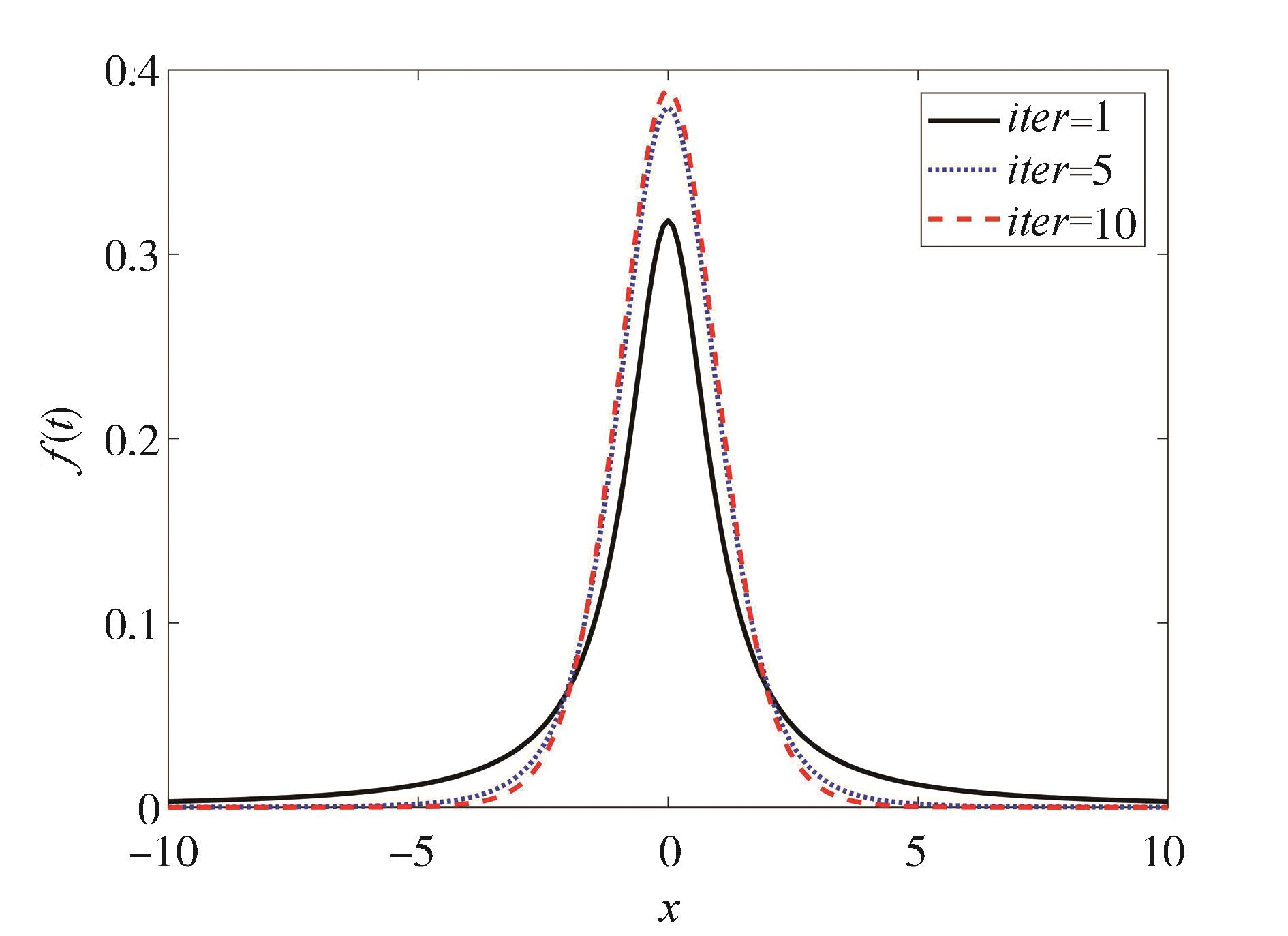
"
"
| ID | 函数 | 维度 | 定义域 | 极小值 | 类型 |
|---|---|---|---|---|---|
| F1 | 30 | [-100,100] | 0 | 单峰 | |
| F2 | 30 | [-100,100] | 0 | 单峰 | |
| F3 | 30 | [-30,30] | 0 | 单峰 | |
| F4 | 30 | [-100,100] | 0 | 单峰 | |
| F5 | 30 | [-500,500] | -418.98d | 多峰 | |
| F6 | 30 | [-32,32] | 0 | 多峰 |
"
| 本文算法 | SSA | SOA | HHO | |||||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
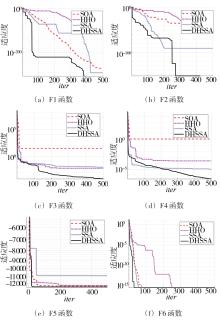
| F1 | 0.00E+00 | 0.00E+00 | 3.71E-102 | 0.00E+00 | 3.75E-232 | 3.86E-07 | 6.11E-106 | 2.45E-05 |
| F2 | 6.75E-127 | 2.03E-08 | 1.37E-124 | 3.21E-07 | 7.62E-26 | 8.41E-07 | 8.27E-56 | 6.32E-05 |
| F3 | 1.44E-04 | 7.21E-10 | 1.30E-03 | 3.09E-11 | 2.88E+01 | 9.03E-09 | 4.30E-03 | 5.69E-12 |
| F4 | 7.54E-06 | 2.81E-08 | 1.36E-06 | 7.86E-15 | 2.14E+00 | 3.75E-07 | 7.83E-04 | 2.05E-07 |
| F5 | -1.25E+04 | 7.16E-08 | -1.15E+04 | 6.82E-07 | -1.25E+04 | 4.25E-07 | -1.24E+04 | 3.57E-05 |
| F6 | 8.88E-16 | 8.21E-10 | 8.88E-16 | 7.58E-05 | 8.88E-16 | 7.25E-09 | 8.88E-16 | 5.95E-06 |
"
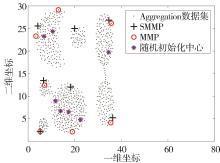
"

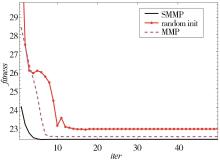
"
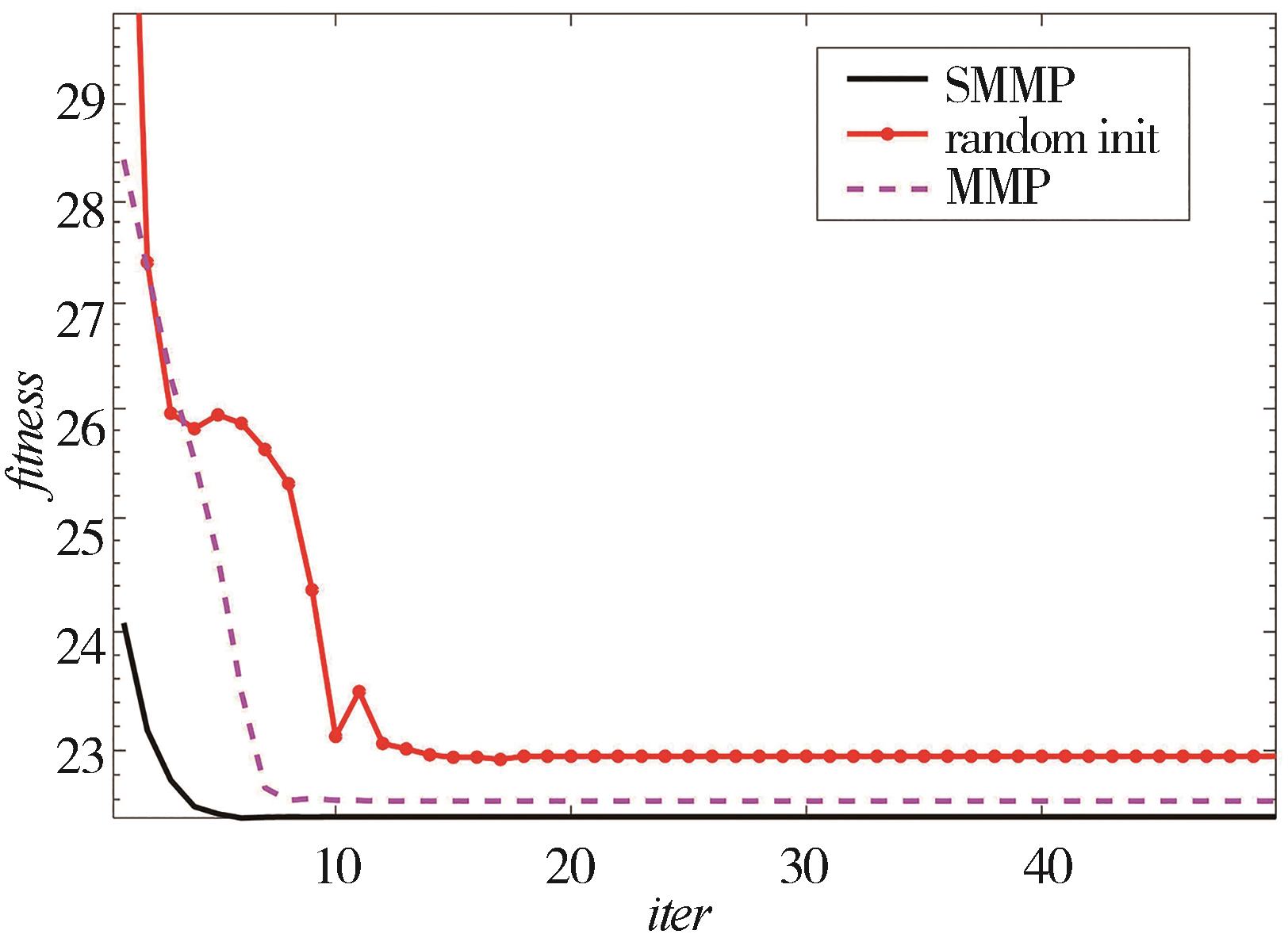
"
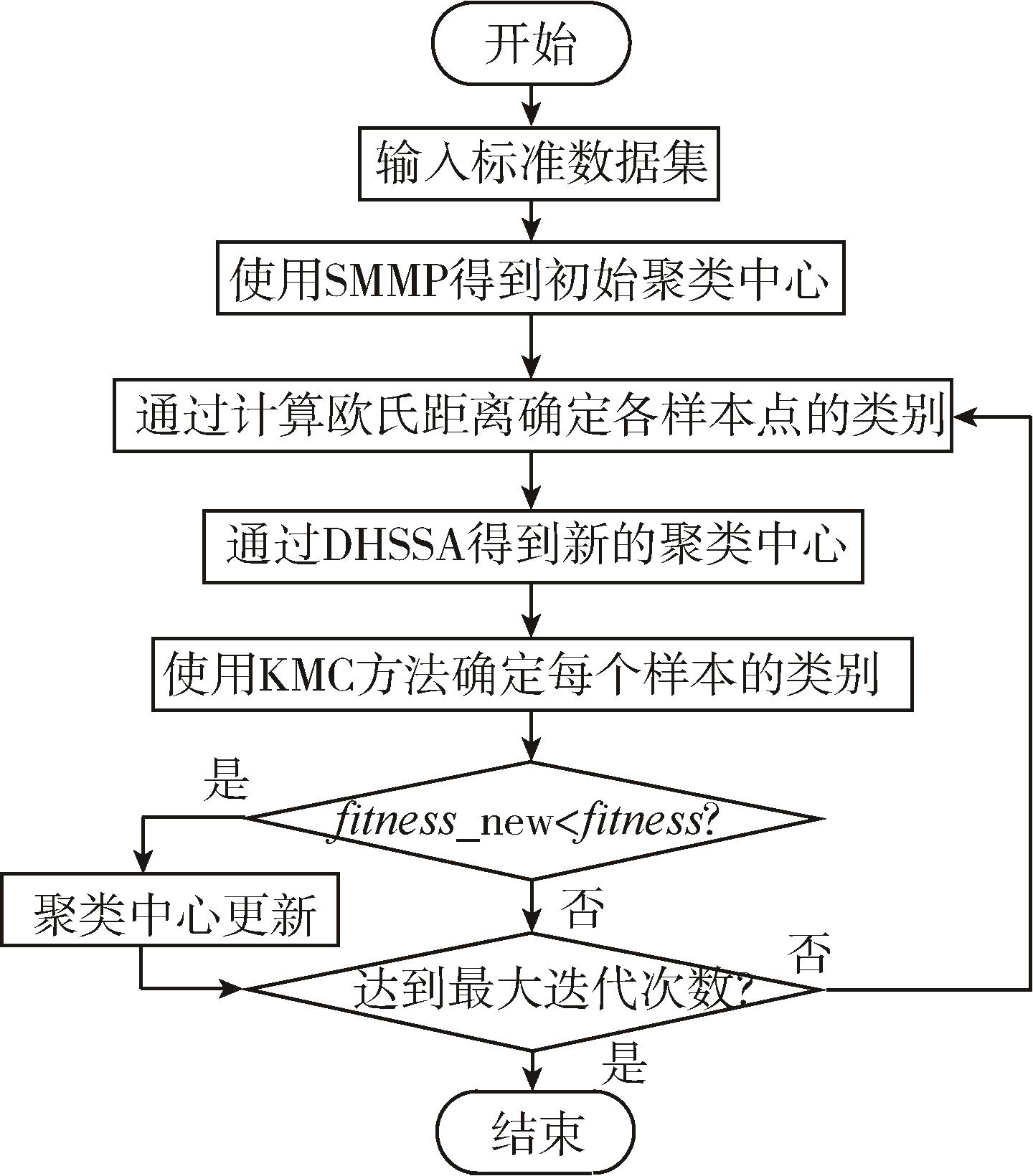
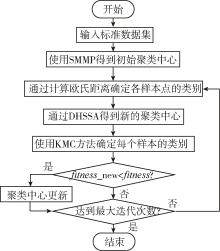
"
| 数据集名称 | 样本数目 | 属性维数 | 类别个数 |
|---|---|---|---|
| Wine | 178 | 13 | 3 |
| Ionosphere | 351 | 34 | 2 |
| Aggregation | 788 | 2 | 7 |
| Vowel | 871 | 3 | 6 |
| Glass | 214 | 9 | 6 |
| Ecoli | 336 | 8 | 8 |
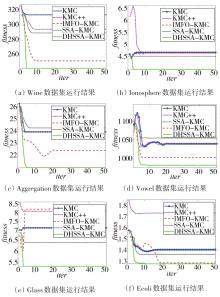
"
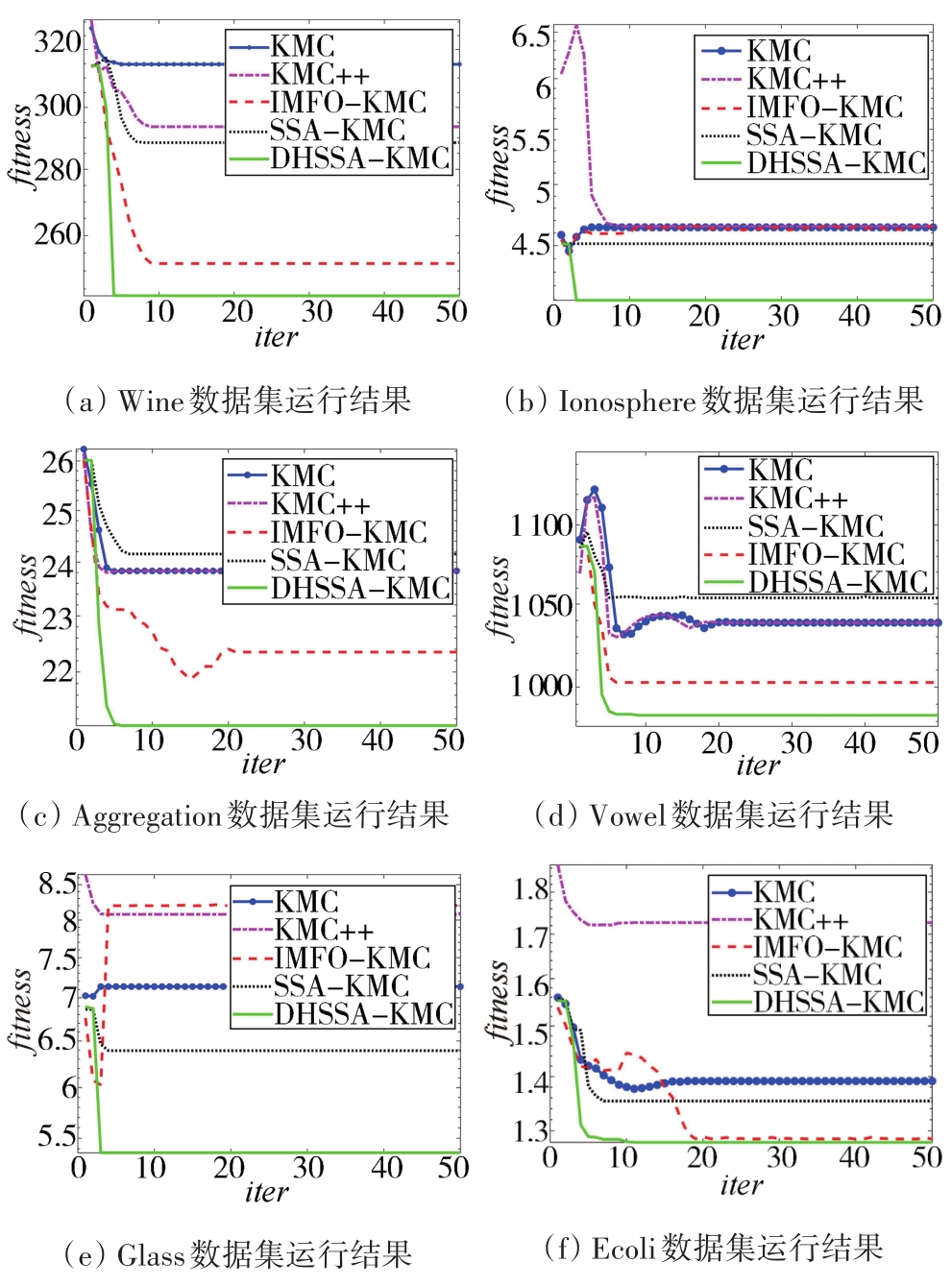
"
| 数据集 | 算法 | Acc | ARI | NMI |
|---|---|---|---|---|
| Wine | KMC | 0.674 2 | 0.338 9 | 0.414 0 |
| Kmeans++ | 0.685 4 | 0.351 8 | 0.424 1 | |
| IMFO-KMC | 0.704 9 | 0.371 5 | 0.419 3 | |
| SSA-KMC | 0.680 1 | 0.352 8 | 0.388 3 | |
| DHSSA-KMC | 0.710 2 | 0.383 9 | 0.426 4 | |
| Aggregation | KMC | 0.895 9 | 0.736 5 | 0.836 9 |
| K-means++ | 0.895 9 | 0.736 5 | 0.836 9 | |
| IMFO-KMC | 0.913 7 | 0.764 2 | 0.877 1 | |
| SSA-KMC | 0.892 4 | 0.756 7 | 0.817 1 | |
| DHSSA-KMC | 0.949 2 | 0.825 2 | 0.864 8 | |
| Ecoli | KMC | 0.779 8 | 0.464 7 | 0.620 7 |
| K-means++ | 0.743 2 | 0.426 1 | 0.604 9 | |
| IMFO-KMC | 0.794 6 | 0.476 1 | 0.624 8 | |
| SSA-KMC | 0.761 9 | 0.436 6 | 0.599 7 | |
| DHSSA-KMC | 0.804 1 | 0.506 0 | 0.640 9 |
"
| 数据集 | 算法 | Sav |
|---|---|---|
| Wine | KMC | 0.442 3 |
| Kmeans++ | 0.452 9 | |
| IMFO-KMC | 0.564 7 | |
| SSA-KMC | 0.483 6 | |
| DHSSA-KMC | 0.592 4 | |
| Aggregation | KMC | 0.475 2 |
| K-means++ | 0.475 2 | |
| IMFO-KMC | 0.556 7 | |
| SSA-KMC | 0.459 6 | |
| DHSSA-KMC | 0.589 2 | |
| Ecoli | KMC | 0.359 4 |
| K-means++ | 0.323 4 | |
| IMFO-KMC | 0.422 1 | |
| SSA-KMC | 0.366 7 | |
| DHSSA-KMC | 0.433 1 |
"
| 数据集 | KMC | IMFO-KMC | SSA-KMC | 本文算法 |
|---|---|---|---|---|
| Wine | 0.048 | 0.652 | 0.343 | 0.225 |
| Aggregation | 0.188 | 1.321 | 0.746 | 0.686 |
| Ecoli | 0.264 | 1.623 | 0.965 | 0.852 |
"
| car_ID | |||||
|---|---|---|---|---|---|
| symboling | 3.0 | ||||
| CarName | |||||
| fueltype | |||||
| aspiration | |||||
| doornumber | |||||
| carbody | |||||
| drivewheel | |||||
| Engine-locate | |||||
| wheelbase | |||||
| carlegth | |||||
| carwidth | |||||
| carheight | |||||
| Curb weight | |||||
| Engine type | 0.0 | ||||
| Cylin number | |||||
| Engine size | |||||
| Fuel system | |||||
| Bore ratio | |||||
| stroke | |||||
Compression ratio | |||||
| Horse power | |||||
| Peak rpm | |||||
| City mpg | |||||
| Highway mpg | |||||
| price |
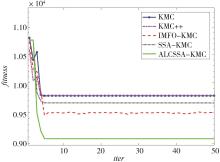
"

"
| 数据集 | KMC | IMFO-KMC | SSA-KMC | 本文算法 |
|---|---|---|---|---|
| 车型信息 | 0.406 5 | 0.437 8 | 0.358 9 | 0.554 1 |
"
| Car_ID | CarName | label |
|---|---|---|
| 3 | audi 100ls | 1 |
| 4 | audi 100ls | 1 |
| 5 | audi fox | 2 |
| 6 | audi 100ls | 5 |
| 7 | audi 5000 | 5 |
| 8 | audi 4000 | 5 |
| 9 | audi 5000s (diesel) | 2 |
"
| Car_ID | CarName | price | label |
|---|---|---|---|
| 200 | volvo diesel | 18 950 | 5 |
| 8 | audi 5000 | 18 920 | 5 |
| 114 | peugeot 504 | 16 695 | 5 |
| 198 | volvo 245 | 16 515 | 5 |
| 182 | toyouta tercel | 15 750 | 5 |
| 103 | nissan fuga | 14 399 | 5 |
| 196 | volvo 144ea | 13 415 | 5 |
| 110 | peugeot 504 (sw) | 12 440 | 5 |
| 1 | SAXENA A, PRASAD M, GUPTA A, et al. A review of clustering techniques and developments[J]. Neurocomputing, 2017, 267: 664-681. |
| 2 | TANG T, CHEN S, ZHAO M, et al. Very large-scale data classification based on K-means clustering and multi-kernel SVM[J]. Soft Computing, 2019, 23(11): 3793-3801. |
| 3 | HARIKRISHNAN P M, THOMAS A, GOPI V P, et al. Inception single shot multi-box detector with affinity propagation clustering and their application in multi-class vehicle counting[J]. Applied Intelligence, 2021: 1-16. |
| 4 | BESSE P C, GUILLOUET B, LOUBES J M, et al. Review and perspective for distance-based clustering of vehicle trajectories[J]. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(11): 3306-3317. |
| 5 | ZHONG Z, LEE E E, NEJAD M, et al. Influence of CAV clustering strategies on mixed traffic flow characteristics: an analysis of vehicle trajectory data[J]. Transportation Research Part C: Emerging Technologies, 2020, 115: 102611. |
| 6 | SINAGA K P, YANG M S. Unsupervised K-means clustering algorithm[J]. IEEE Access, 2020, 8: 80716-80727. |
| 7 | SARI P K, PURWADINATA A. Analysis characteristics of car sales in E-commerce data using clustering model[J]. Journal of Data Science and Its Applications, 2019, 2(1): 19-28. |
| 8 | 邓旭冉,超木日力格,郭静.聚类中心初始值选择方法综述[J].中国电子科学研究院学报,2019,14(4):354-359,372. |
| DENG X, CHAOMU R, GUO J. Summary of methods for selecting initial values of cluster centers [ J ]. Journal of China Academy of Electronic Sciences, 2019,14 ( 4 ) : 354-359,372. | |
| 9 | 华佳林,朱杰,于剑.一种分割-合并聚类算法[J].南京大学学报(自然科学版),2016,52(4):724-734. |
| HUA J, ZHU J, YU J. A partition-merge clustering algorithm [J]. Journal of Nanjing University ( Natural Science ), 2016,52 (4 ) : 724-734. | |
| 10 | 杨俊闯,赵超.K-Means聚类算法研究综述[J].计算机工程与应用,2019,55(23):7-14,63. |
| YANG J, ZHAO C. Review of K-means clustering algorithm [J].Computer Engineering and Application,2019,55 (23): 7-14,63. | |
| 11 | DAS P, DAS D K, DEY S. A modified bee colony optimization (MBCO) and its hybridization with k-means for an application to data clustering[J]. Applied Soft Computing, 2018, 70: 590-603. |
| 12 | 陈小雪,尉永清,任敏,等.基于萤火虫优化的加权K-means算法[J].计算机应用研究,2018,35(2):466-470. |
| CHEN X, YU Y, REN M, et al. The weighted K-means algorithm based on firefly optimization [J]. Computer Application Research, 2018,35(2): 466-470. | |
| 13 | 黄小莉,陈静娴,胡思宇.基于自适应果蝇优化算法的K-means聚类[J].国外电子测量技术,2021,40(6):14-20. |
| HUANG X, CHEN J, HU S. K-means clustering based on adaptive fruit fly optimization algorithm [J].Foreign Electronic Measurement Technology, 2021,40(6): 14-20. | |
| 14 | 黄鹤,李昕芮,吴琨,等.引入改进飞蛾扑火的K均值交叉迭代聚类算法[J]. 西安交通大学学报,2020,54(9):32-39.HUANG H, LI X, WU K, et al. Improved K-means cross-iterative clustering algorithm for moth-fire [J]. Journal of Xi 'an Jiaotong University, 2020, 54 ( 9 ) : 32-39. |
| 15 | XUE J, SHEN B. A novel swarm intelligence optimization approach: sparrow search algorithm[J]. Systems Science & Control Engineering,2020,8(1):22-34. |
| 16 | GAURAV DHIMAN,VIJAY Kumar. Seagull optimization algorithm: theory and its applications for large-scale industrial engineering problems[J]. Knowledge-Based Systems,2018. |
| 17 | HEIDARI A A, MIRJALILI S, FARIS H, et al. Harris hawks optimization: algorithm and applications[J]. Future Generation Computer Systems, 2019, 97: 849-872. |
| 18 | GAN G J,NG M K P.K-means clustering with outlier removal[J].Pattern Recognition Letters,2017,90:8-14. |
| 19 | Cystanford. 汽车产品聚类分析[EB/OL].https://tianchi.aliyun.com/dataset/dataDetail?dataId=97654,2021-04-14/2021-10-23. |
| 20 | 杨晓伟,黄滢婷.基于多特征融合的实时单目标追踪算法[J].华南理工大学学报(自然科学版),2019,47(6):1-9. |
| YANG X, HUANG Y. Real-time single target tracking algorithm based on multi-feature fusion [ J ].Journal of South China University of Technology ( Natural Science Edition ), 2019,47 ( 6 ) : 1-9. | |
| 21 | 王建仁,马鑫,段刚龙.改进的 K-means 聚类k值选择算法[J].计算机工程与应用,2019,55(8):27-33. |
| WANG J, MA X, DUAN G. Improved K-means clustering k-value selection algorithm [J].Computer Engineering and Application, 2019,55 (8) : 27-33. |
| [1] | Zhang Wei, Wang Yingxiao, Peng Yiyuan, Chen Zhaohui, Jiang Qianyu. Steady Flow Test and Combustion Analysis of Different Spiral/ Tangential Air-Passage Valves [J]. Automotive Engineering, 2020, 42(11): 1537-1544. |
| [2] | Zhang Wei, Zhao Luofeng, Chen Zhaohui, Jiang Qianyu & Zou Chao. Steady Airflow Test and In-cylinder Flow Motion Analysis of Double Inlet-channel Diesel Engine Based on Tuft Flow Visualization [J]. Automotive Engineering, 2019, 41(10): 1130-1137. |