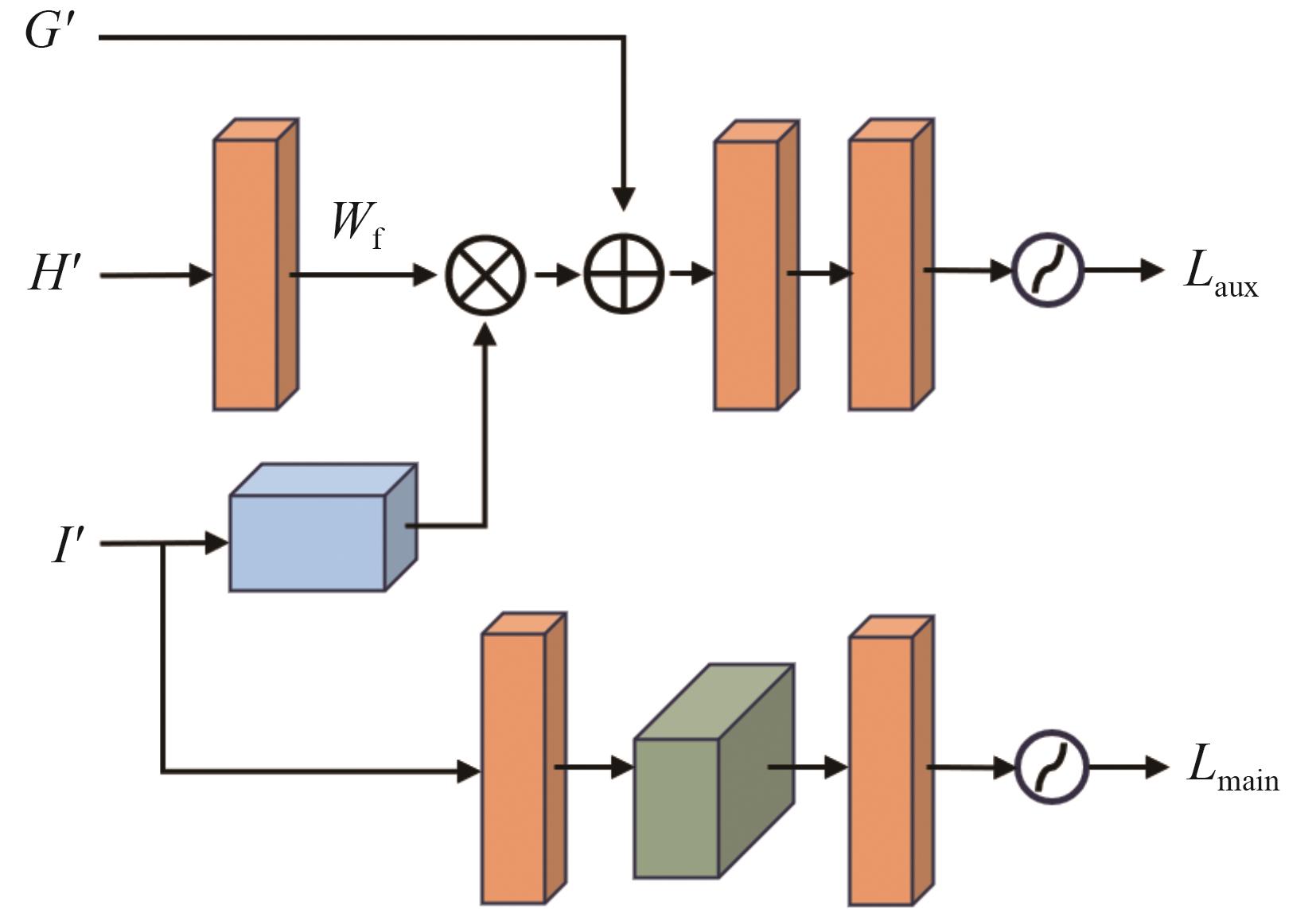
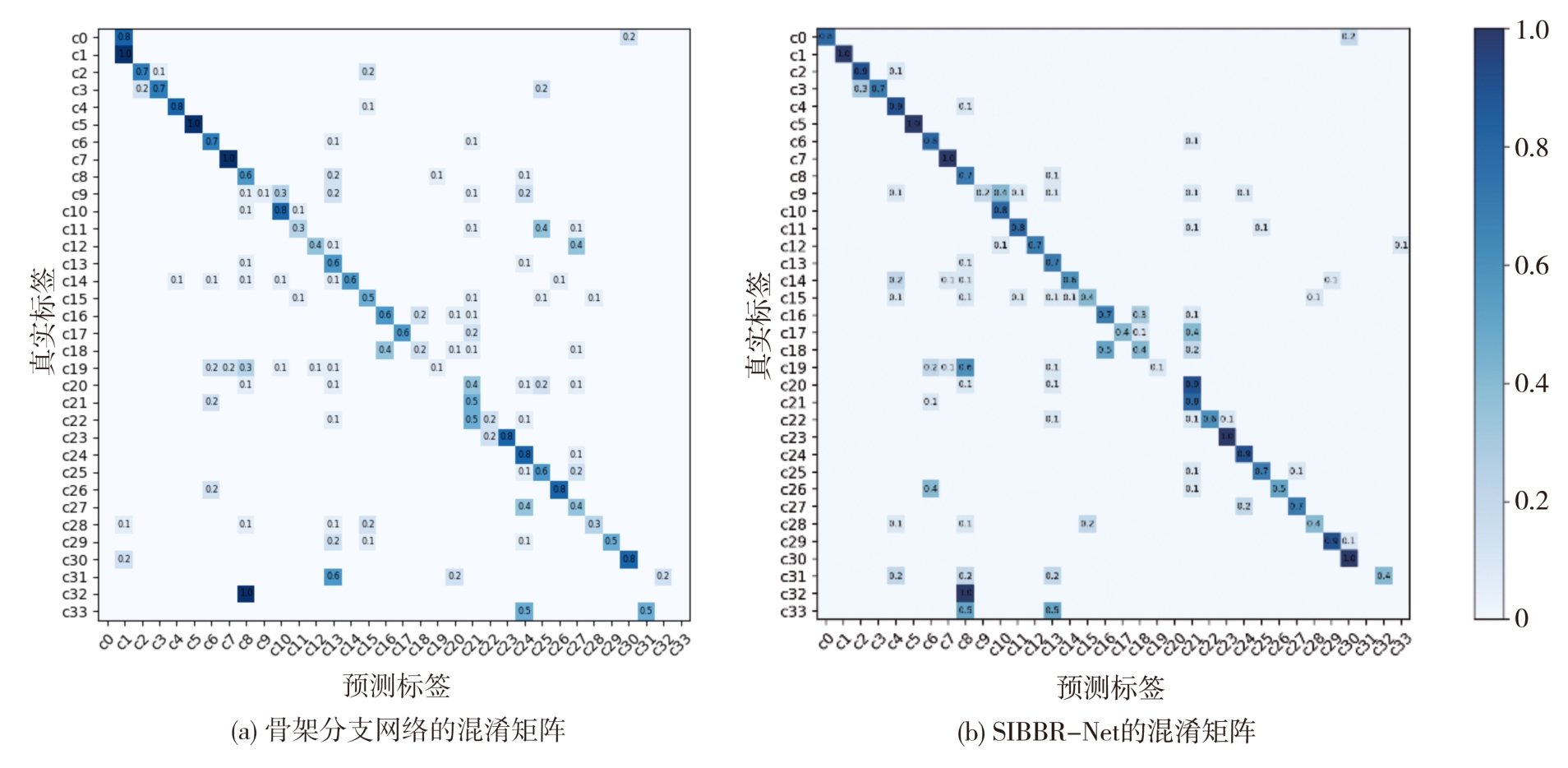
| [1] |
ZHOU Wei, ZHANG Cheng-Ning, LI Jun-Qiu. [J]. , 2016, 38(12): 1407
-1414
. |
| [2] |
LI Huan, HUANG Ying, ZHANG Fu-Jun, ZHAO Yu, GE Yan-Wu. [J]. , 2016, 38(12): 1420
-1426
. |
| [3] |
HAO Han, WANG Si-南, LI Xiao, LIU Zong-Wei, ZHAO Fu-Quan. [J]. , 2017, 39(1): 1
-8
. |
| [4] |
ZONG Yi-Qi, GU Zheng-Qi, LUO Ze-Min, JIANG Cai-Mao, ZHANG Qi-Dong, YANG Zhen-Dong. [J]. , 2016, 38(12): 1427
-1433
. |
| [5] |
ZHANG Ying-Chao, ZHAN Da-Peng, ZHAO Jing, ZHANG Zhe, LI Jie. [J]. , 2016, 38(12): 1434
-1439
. |
| [6] |
XU Cheng-Shan, JIANG Fa-Chao, SONG Sen-Nan, TIAN Guang-Yu. [J]. , 2017, 39(1): 9
-14
. |
| [7] |
SHEN Zhe, WANG Yi-Gang, YANG Zhi-Gang, LI Fang-Xu. [J]. , 2016, 38(12): 1440
-1445
. |
| [8] |
ZENG Bi-Qiang, GAO Ji-Dong, PENG Wei, SUN Zhen-Dong. [J]. , 2016, 38(12): 1446
-1451
. |
| [9] |
ZHANG Yi-Bing, 吕Jian-Jun , YUAN Guang-Hui. [J]. , 2016, 38(12): 1467
-1470
. |
| [10] |
LIU Hui, WANG Xiao-Jie, XIANG Chang-Le. [J]. , 2016, 38(12): 1483
-1487
. |
|
 ),Zhenhai Gao
),Zhenhai Gao