汽车工程 ›› 2024, Vol. 46 ›› Issue (1): 1-8.doi: 10.19562/j.chinasae.qcgc.2024.01.001
• 专题:智能座舱与人机交互技术 • 下一篇
胡宏宇,黎烨宸,张争光,曲优,何磊( ),高镇海
),高镇海
Hongyu Hu,Yechen Li,Zhengguang Zhang,You Qu,Lei He(),Zhenhai Gao
摘要:
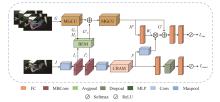
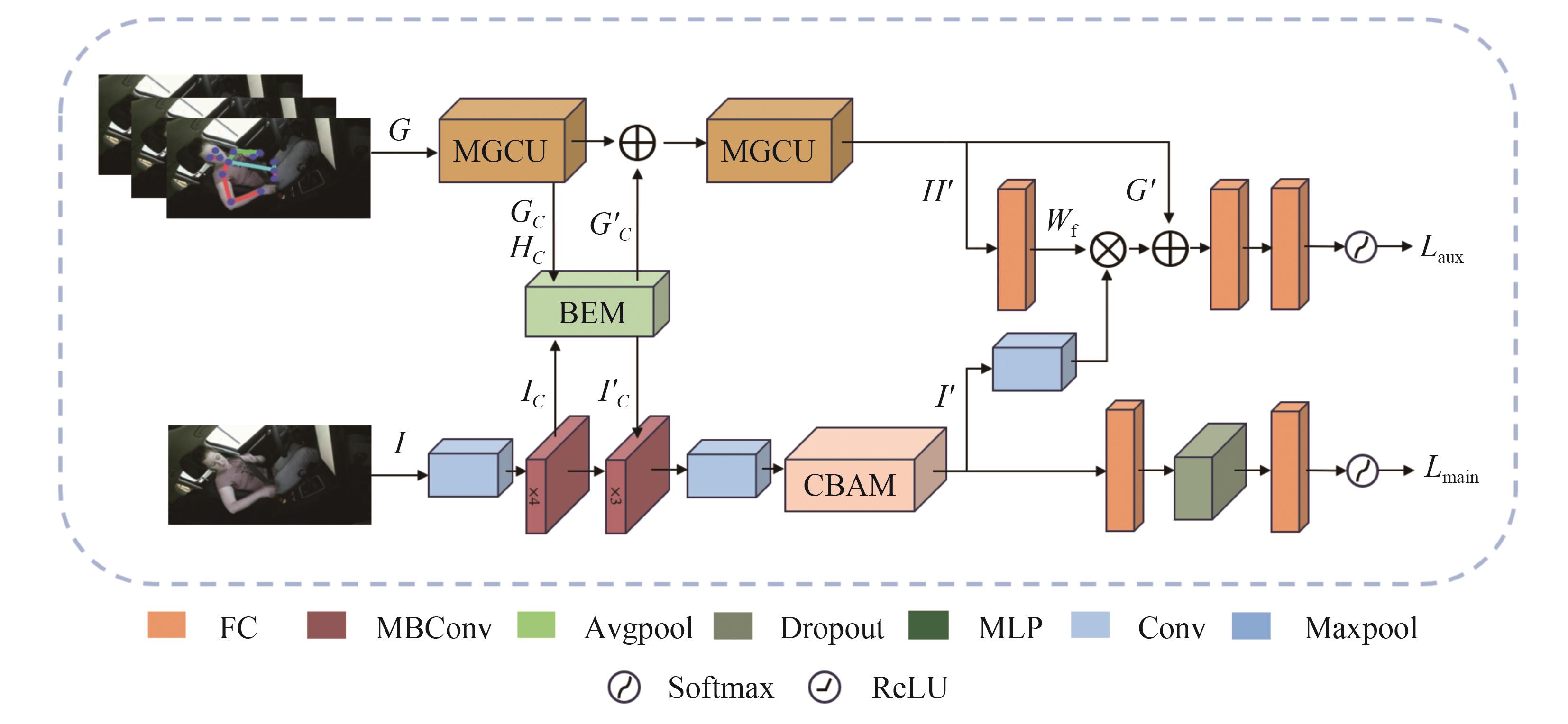
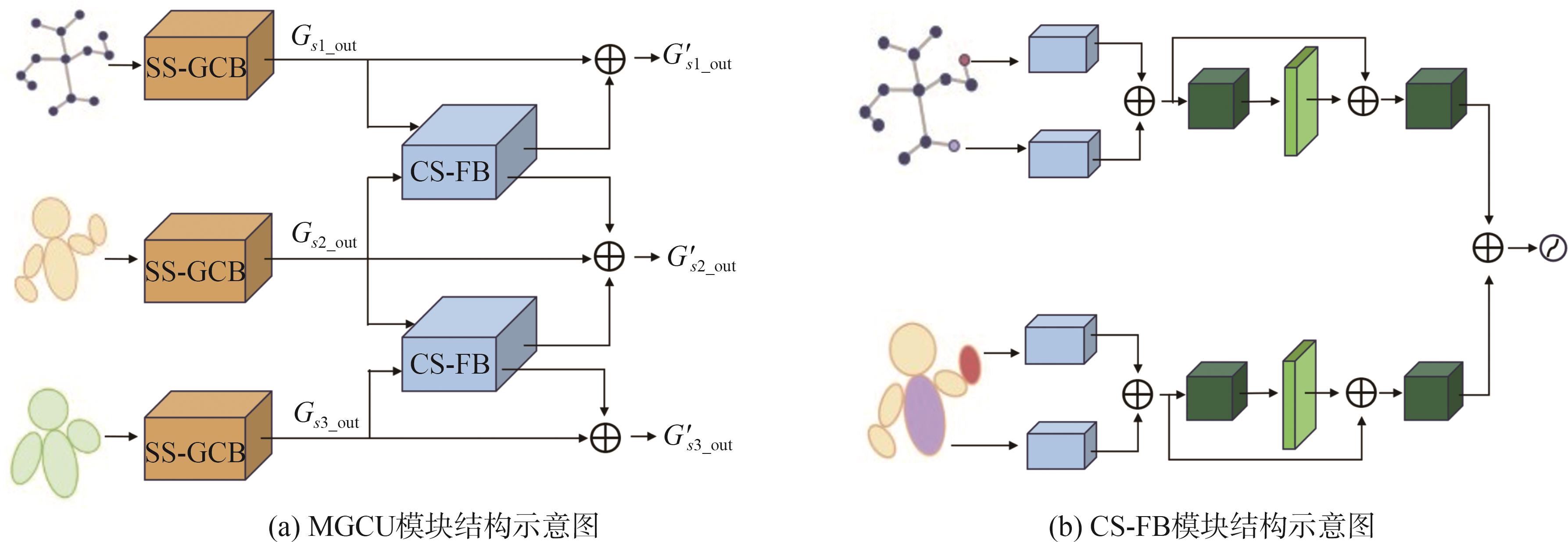
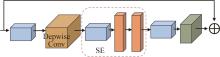
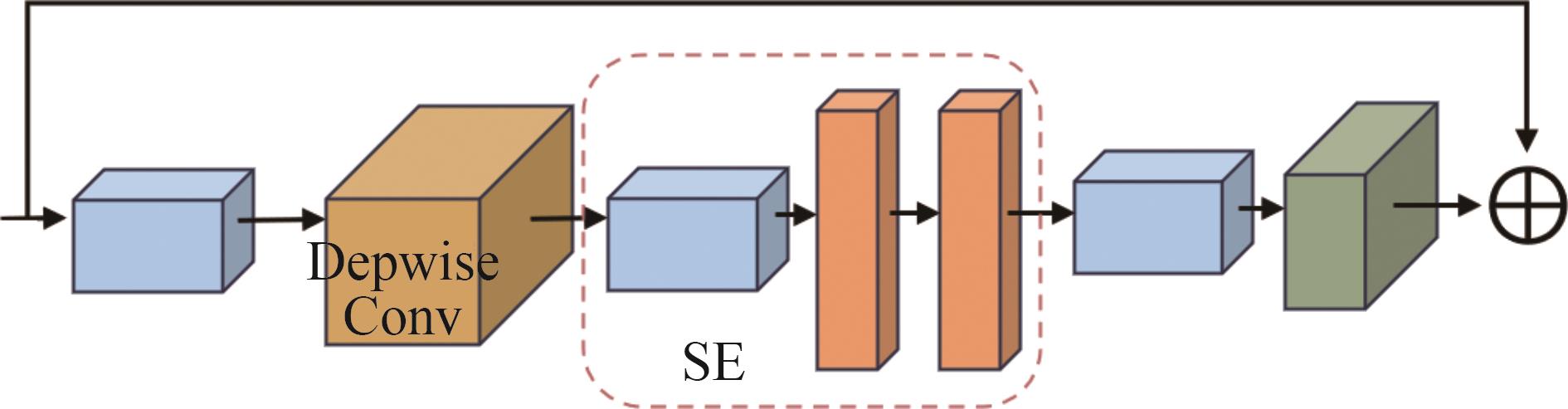
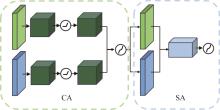
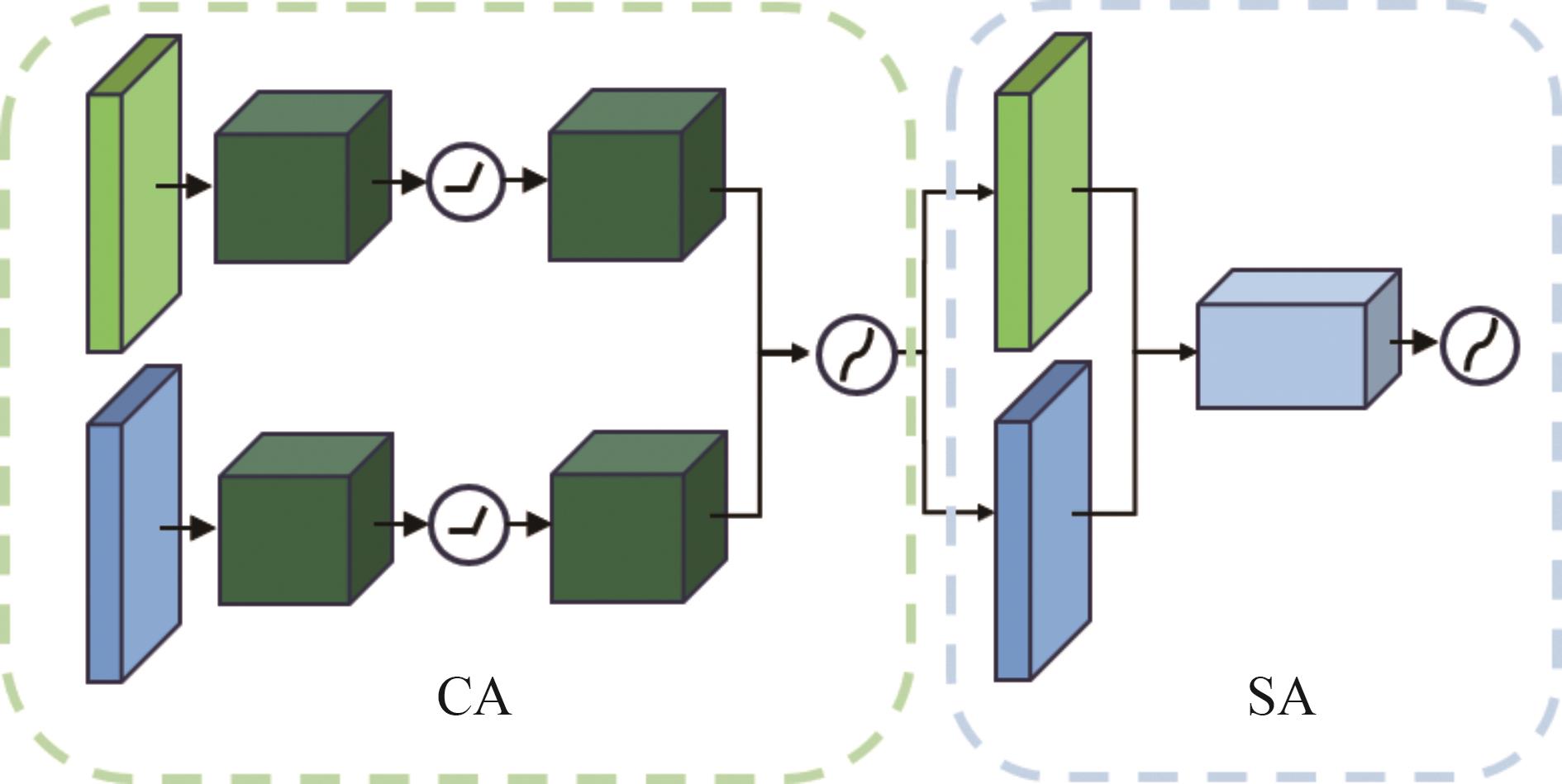
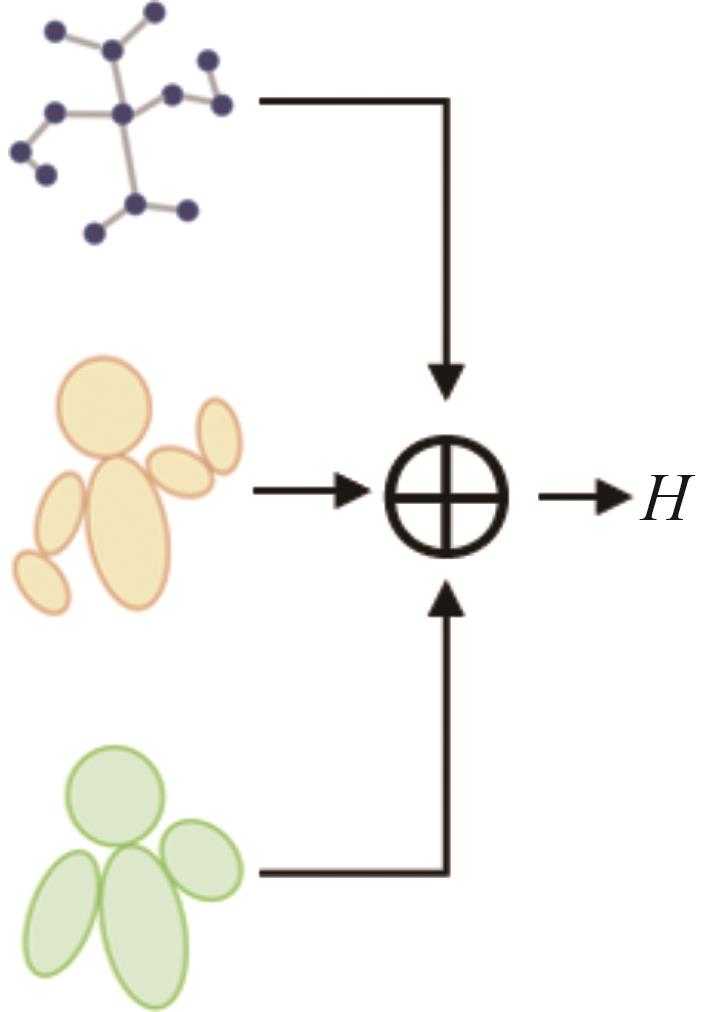
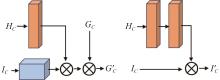
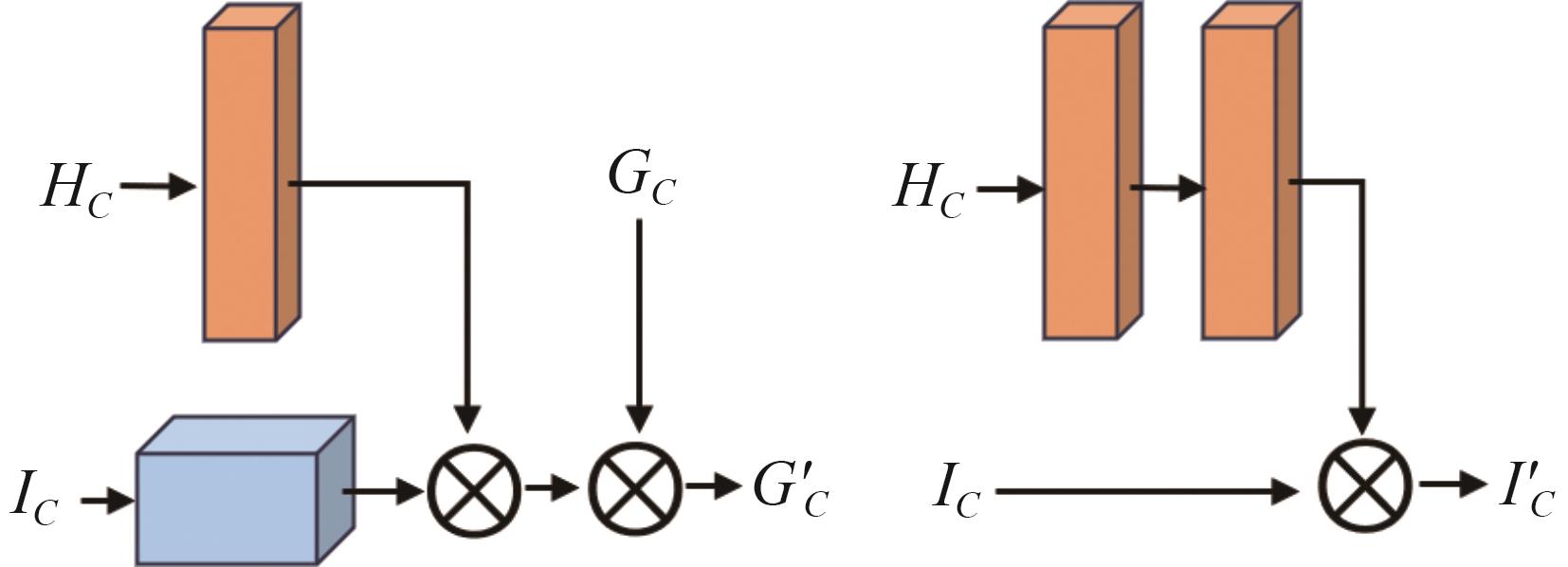
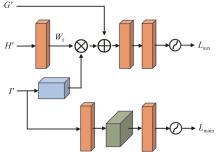
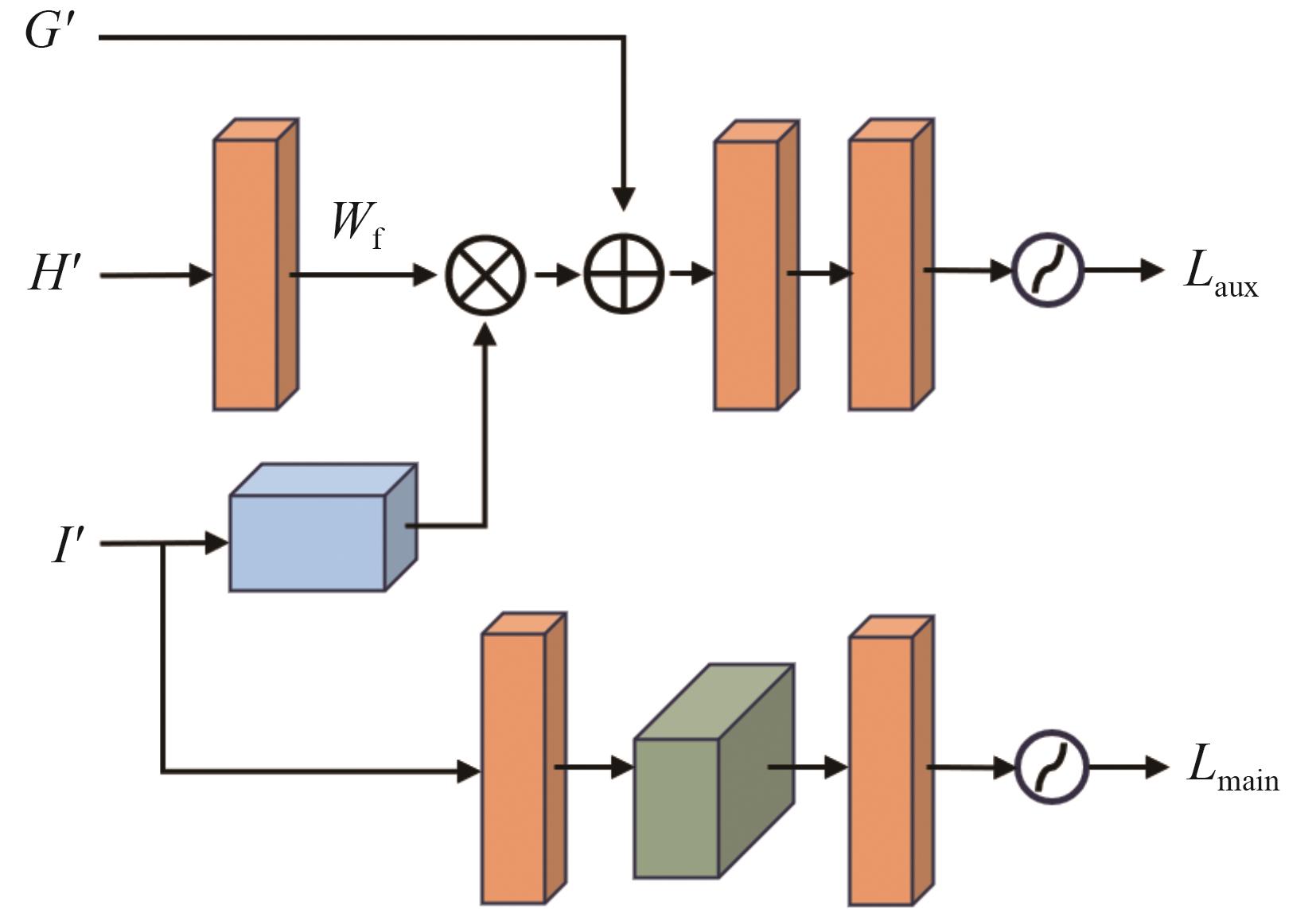
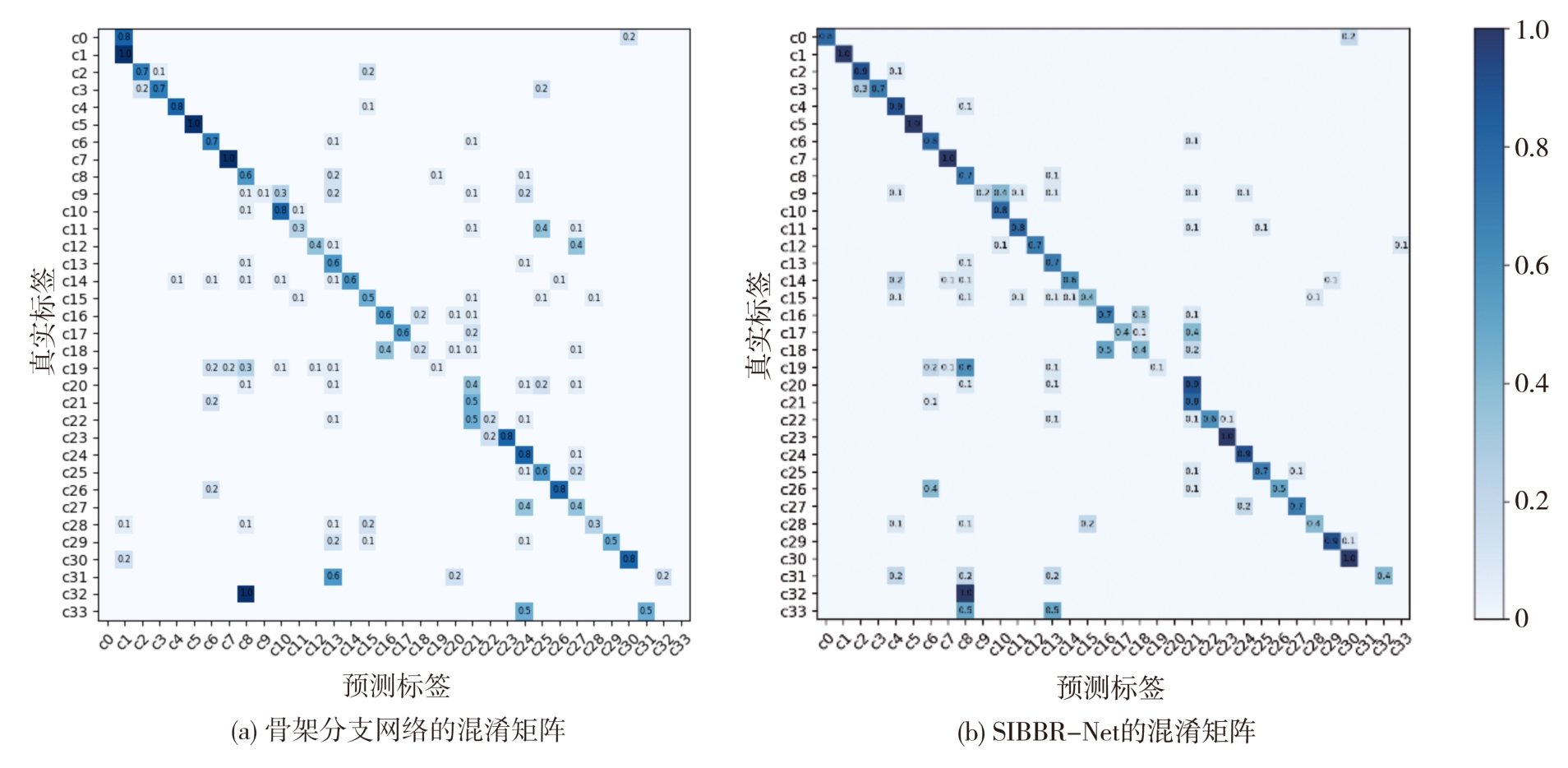
识别非驾驶行为是提高驾驶安全性的重要手段之一。目前基于骨架序列和图像的融合识别方法具有计算量大和特征融合困难的问题。针对上述问题,本文提出一种基于多尺度骨架图和局部视觉上下文融合的驾驶员行为识别模型(skeleton-image based behavior recognition network,SIBBR-Net)。SIBBR-Net通过基于多尺度图的图卷积网络和基于局部视觉及注意力机制的卷积神经网络,充分提取运动和外观特征,较好地平衡了模型表征能力和计算量间的关系。基于手部运动的特征双向引导学习策略、自适应特征融合模块和静态特征空间上的辅助损失,使运动和外观特征间互相引导更新并实现自适应融合。最终在 Drive&Act 数据集进行算法测试,SIBBR-Net在动态标签和静态标签条件下的平均正确率分别为 61.78%和 80.42%,每秒浮点运算次数为 25.92G,较最优方法降低了76.96%。