汽车工程 ›› 2025, Vol. 47 ›› Issue (8): 1513-1521.doi: 10.19562/j.chinasae.qcgc.2025.08.008
• • 上一篇
吴坚,石裕康,朱冰,赵健,陈志成( )
)
Jian Wu,Yukang Shi,Bing Zhu,Jian Zhao,Zhicheng Chen()
摘要:
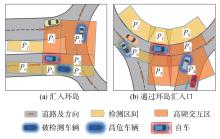
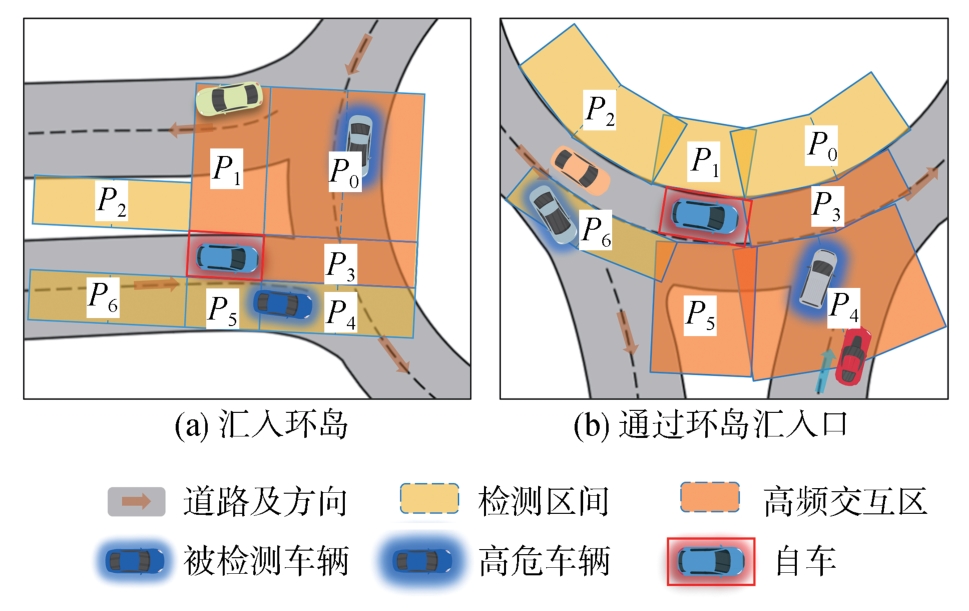
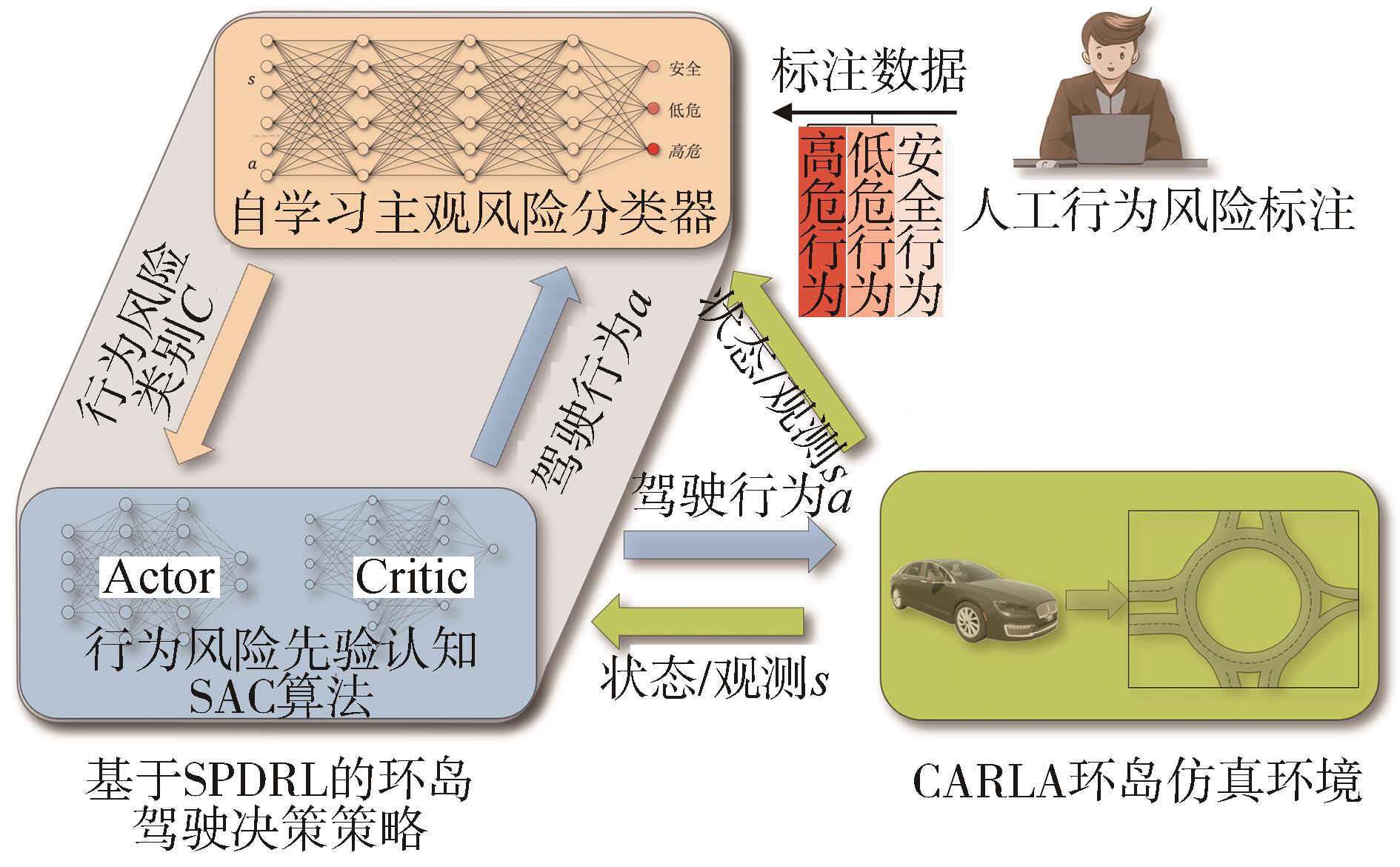
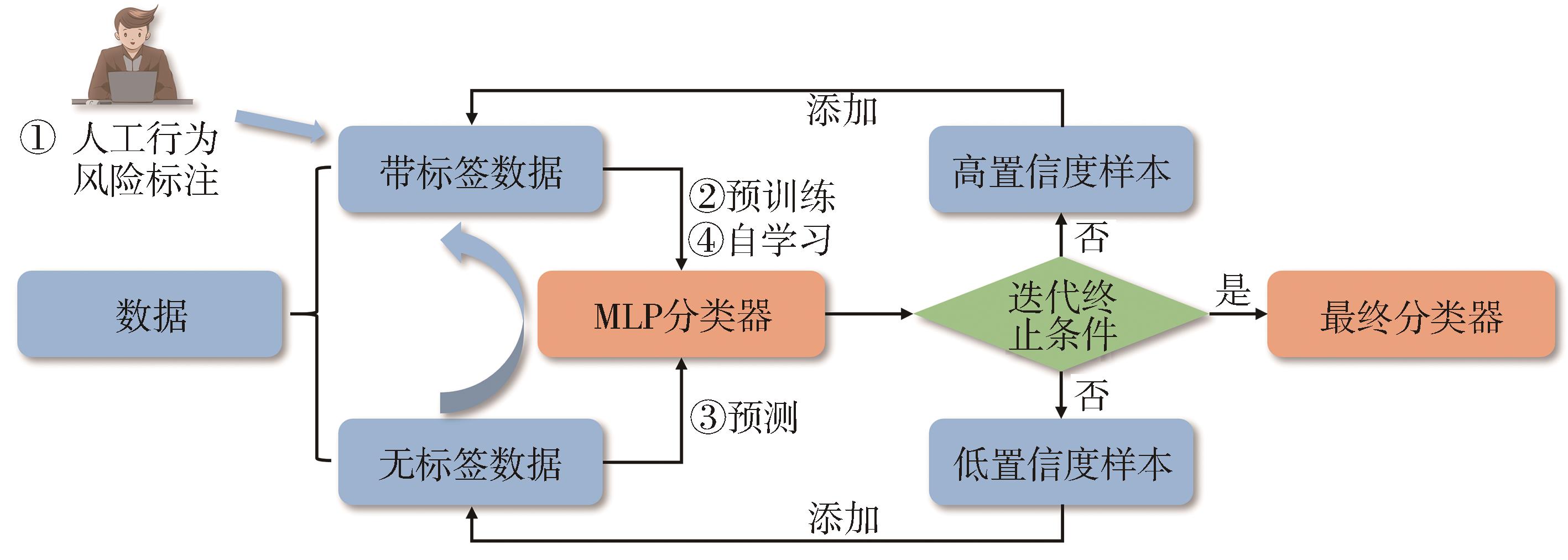
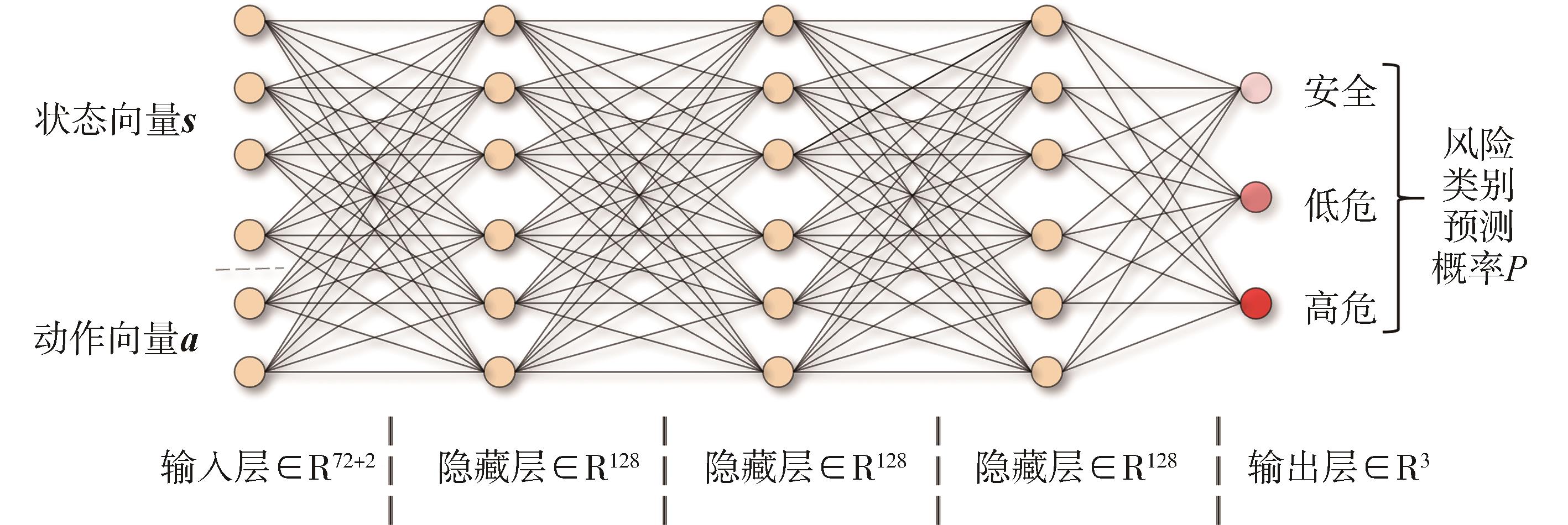
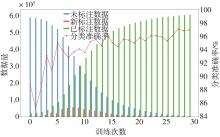
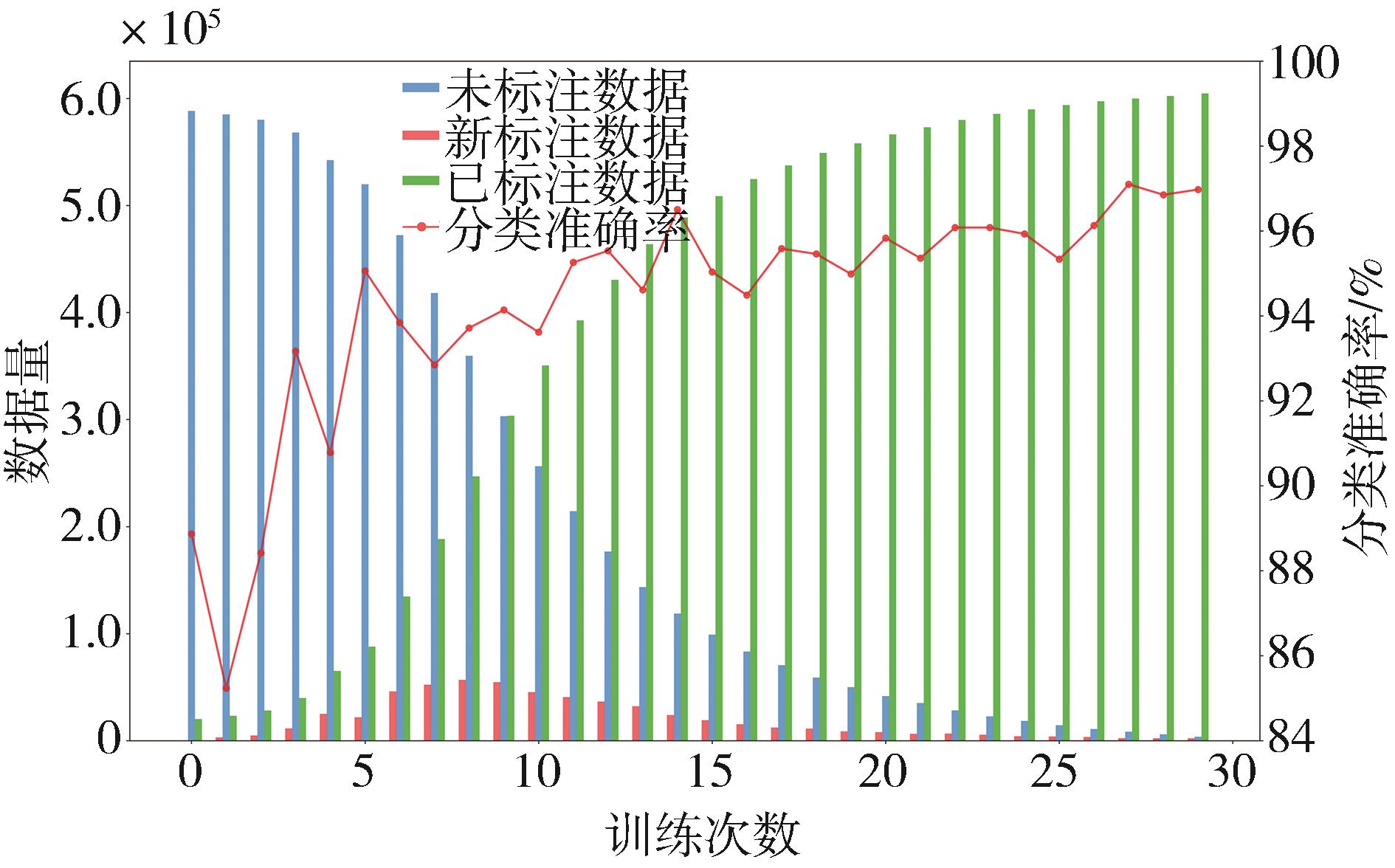
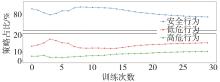
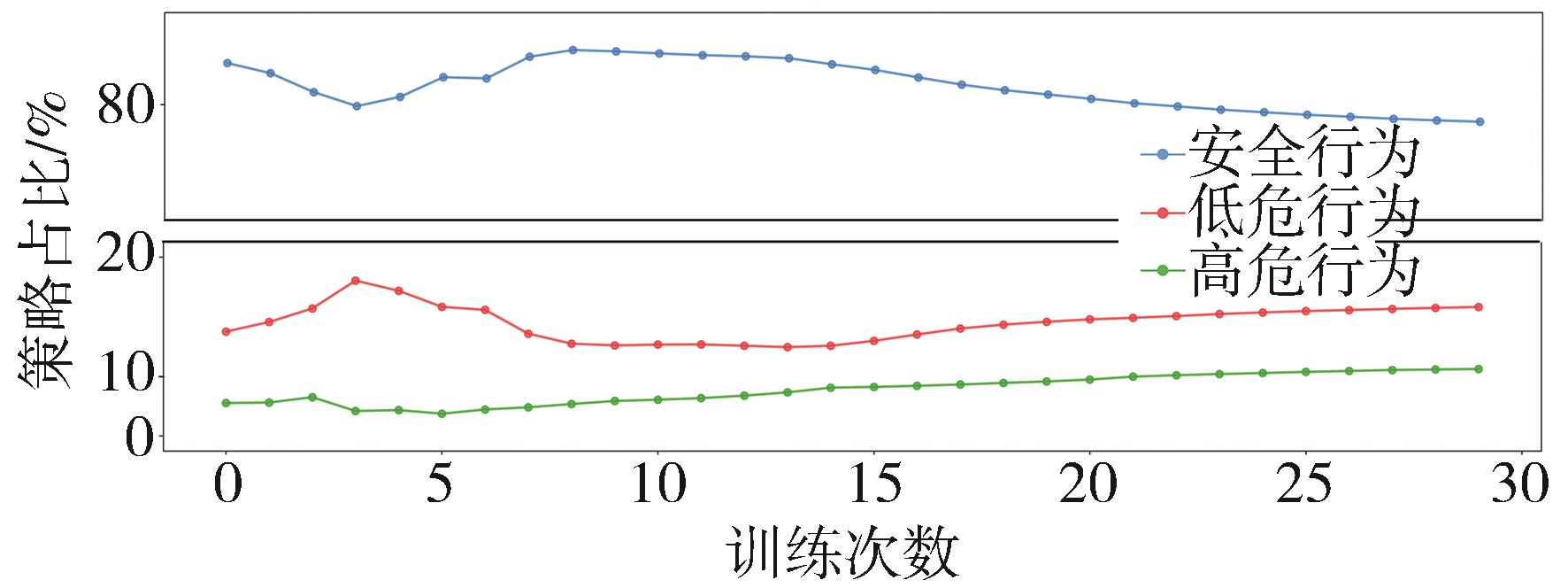
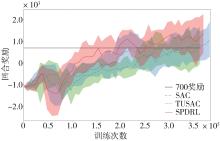
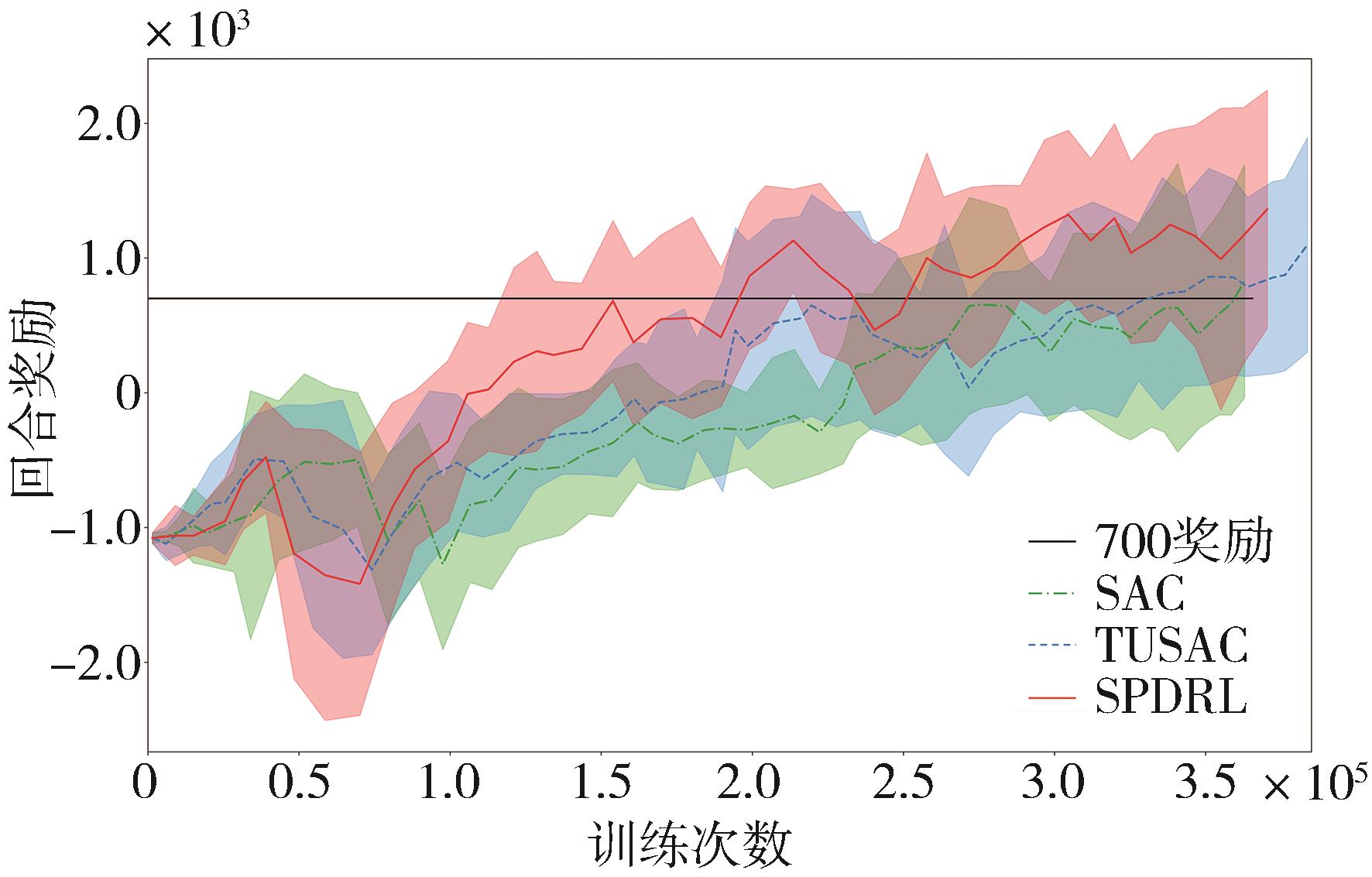
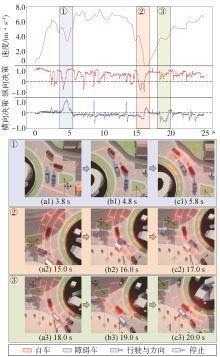
针对汽车在复杂强交互环岛场景下面临的安全性问题,提出一种基于主观先验强化学习的驾驶决策策略。首先,构建包含汽车横纵向耦合动作空间、多尺度信息状态空间、多目标奖励函数的环岛场景模型。其次,采用人类偏好强化学习理论优化的Soft Actor-Critic算法,设计考虑智能体行为风险先验认知的汽车驾驶决策策略。基于多层感知机的自学习主观风险分类器,对智能体行为风险进行先验认知评定,引导汽车驾驶决策朝向更安全方向收敛。最后,搭建CARLA仿真环境开展测试验证。结果表明,相比于SAC算法,本文设计的策略能够帮助汽车在环岛场景中提升约8.73%的驾驶决策安全性能。