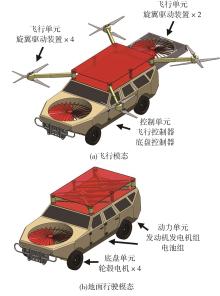
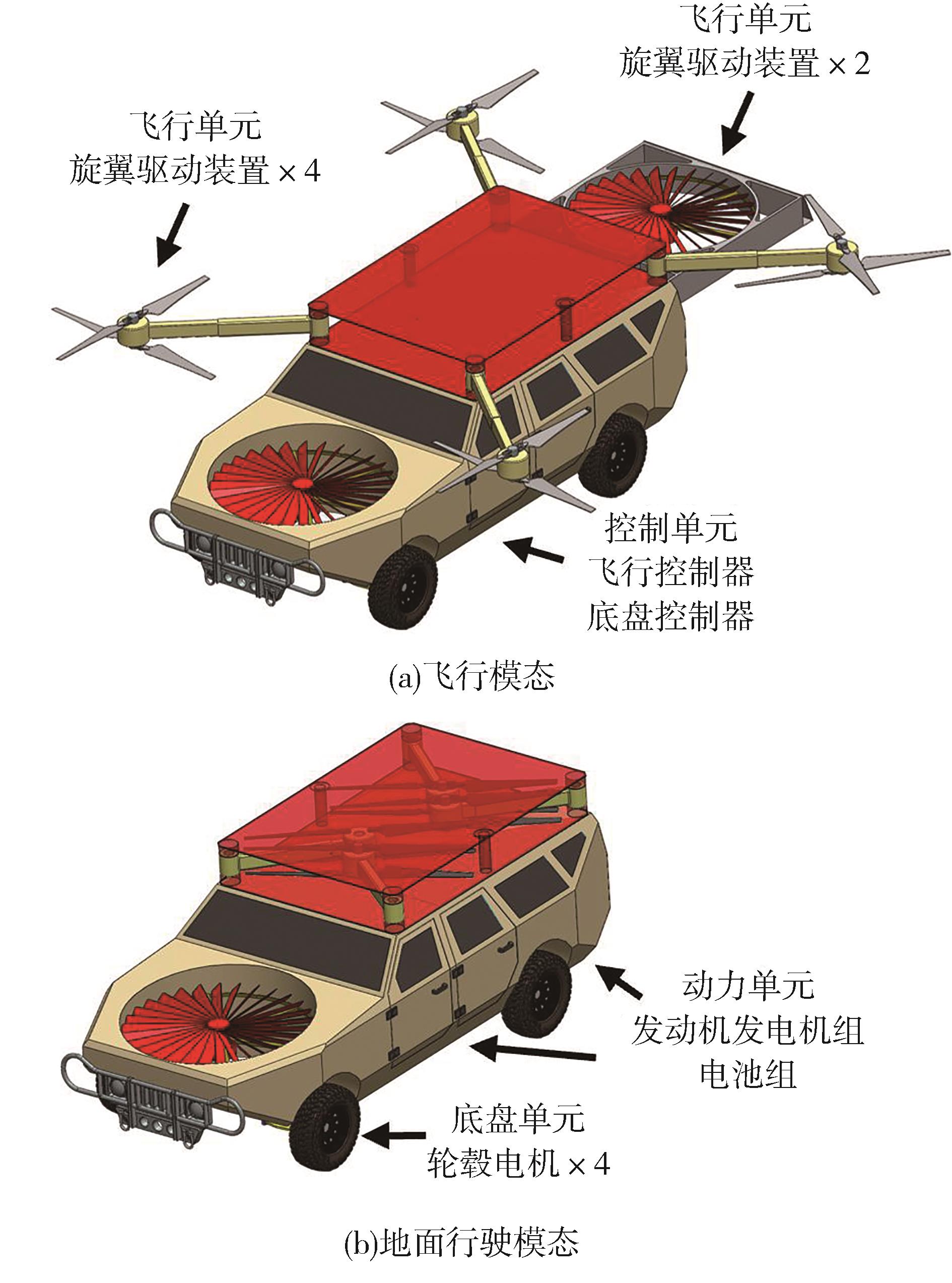
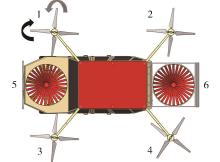
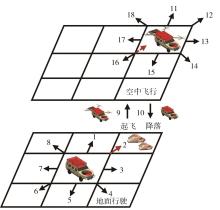
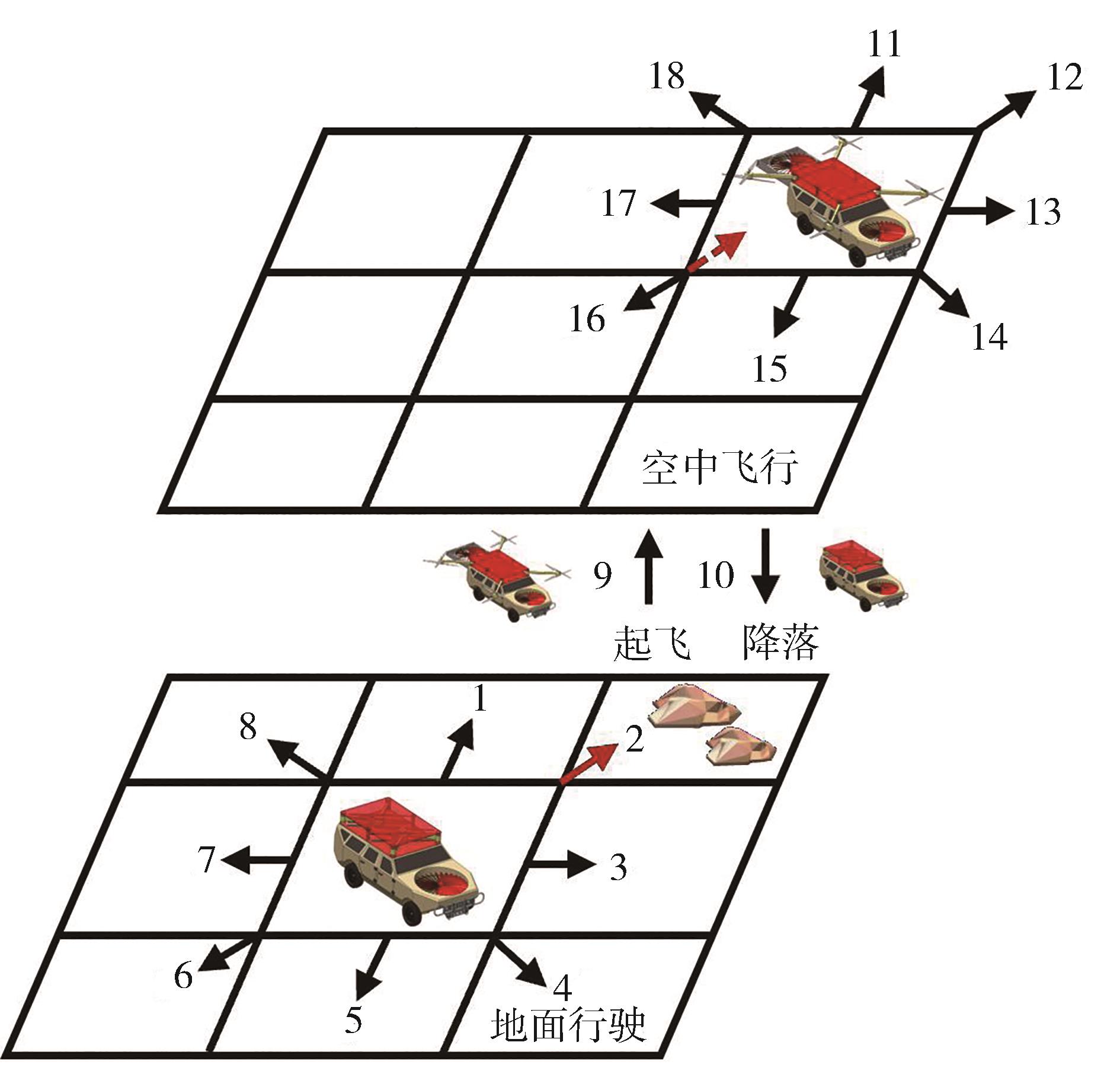
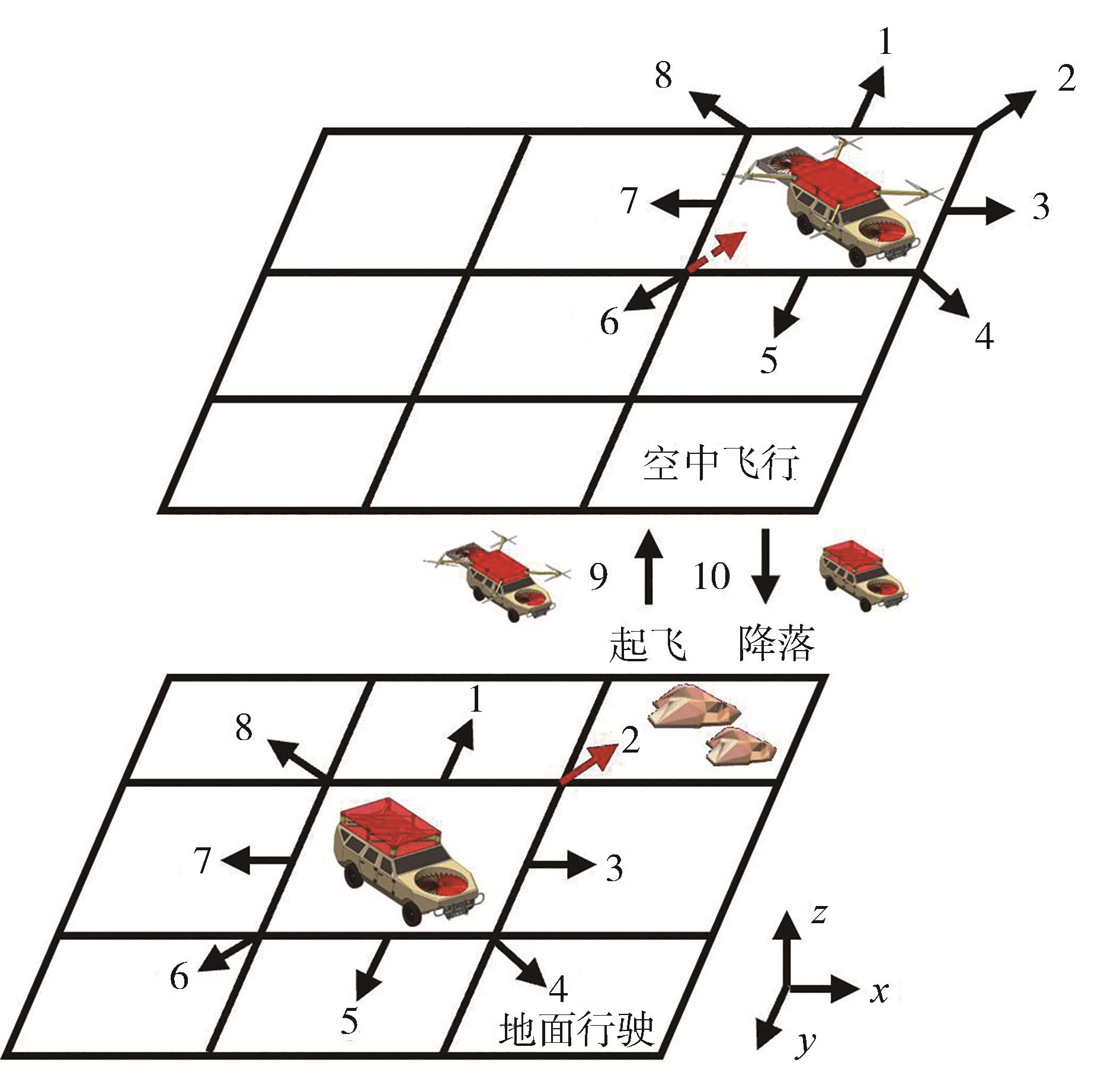
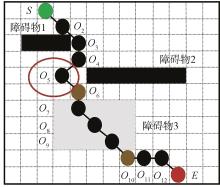
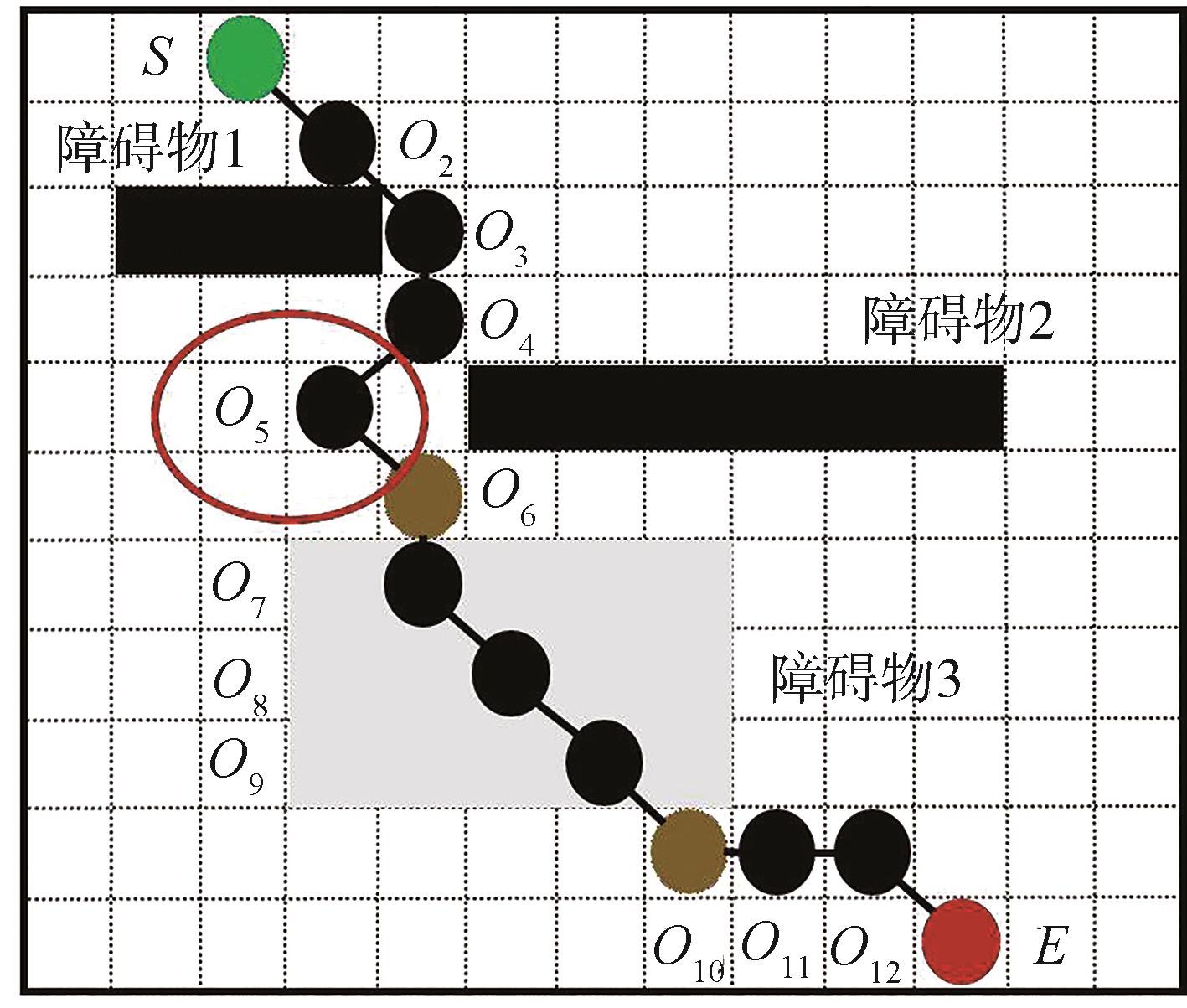
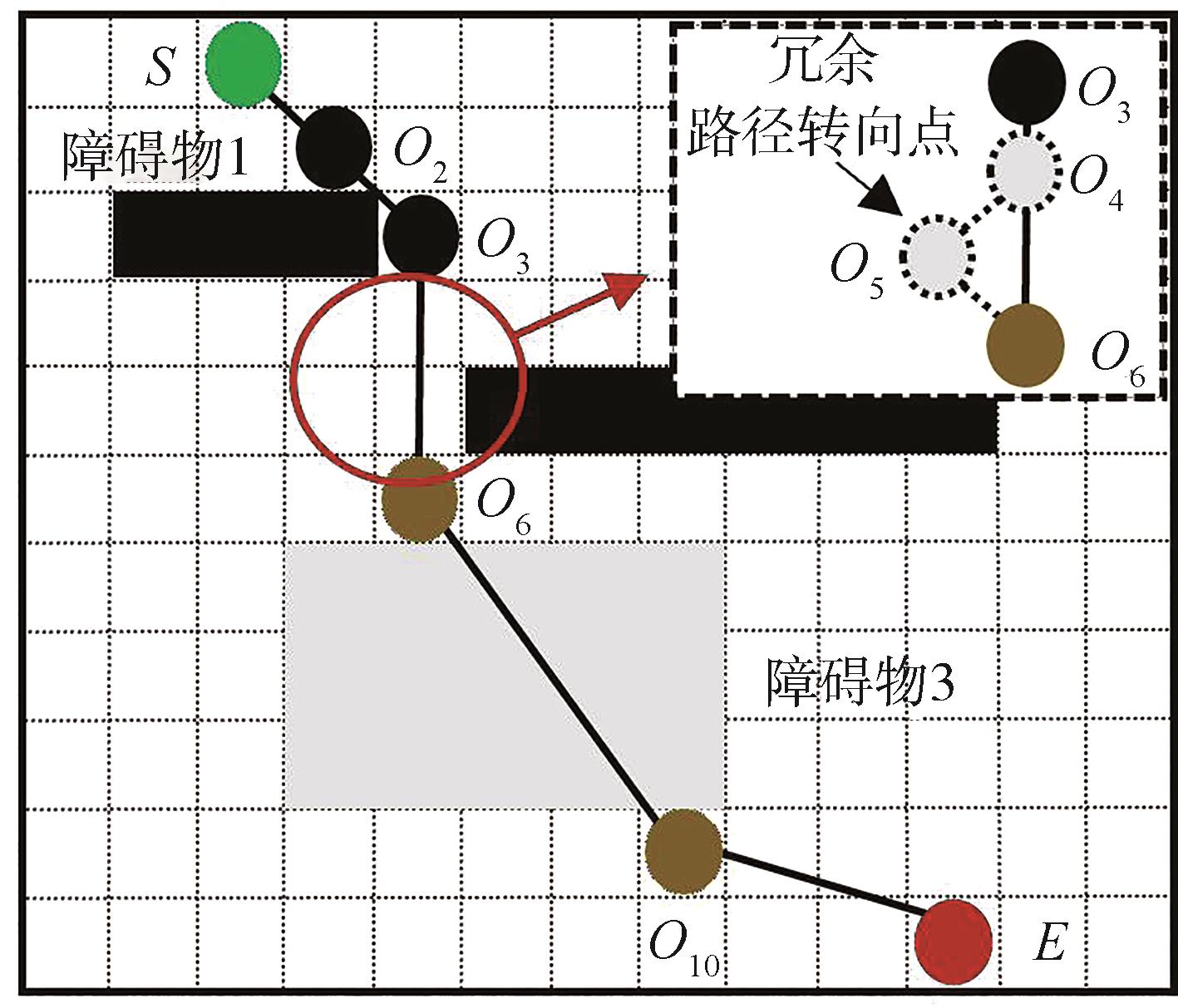
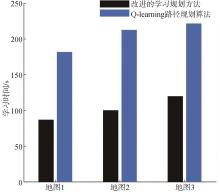
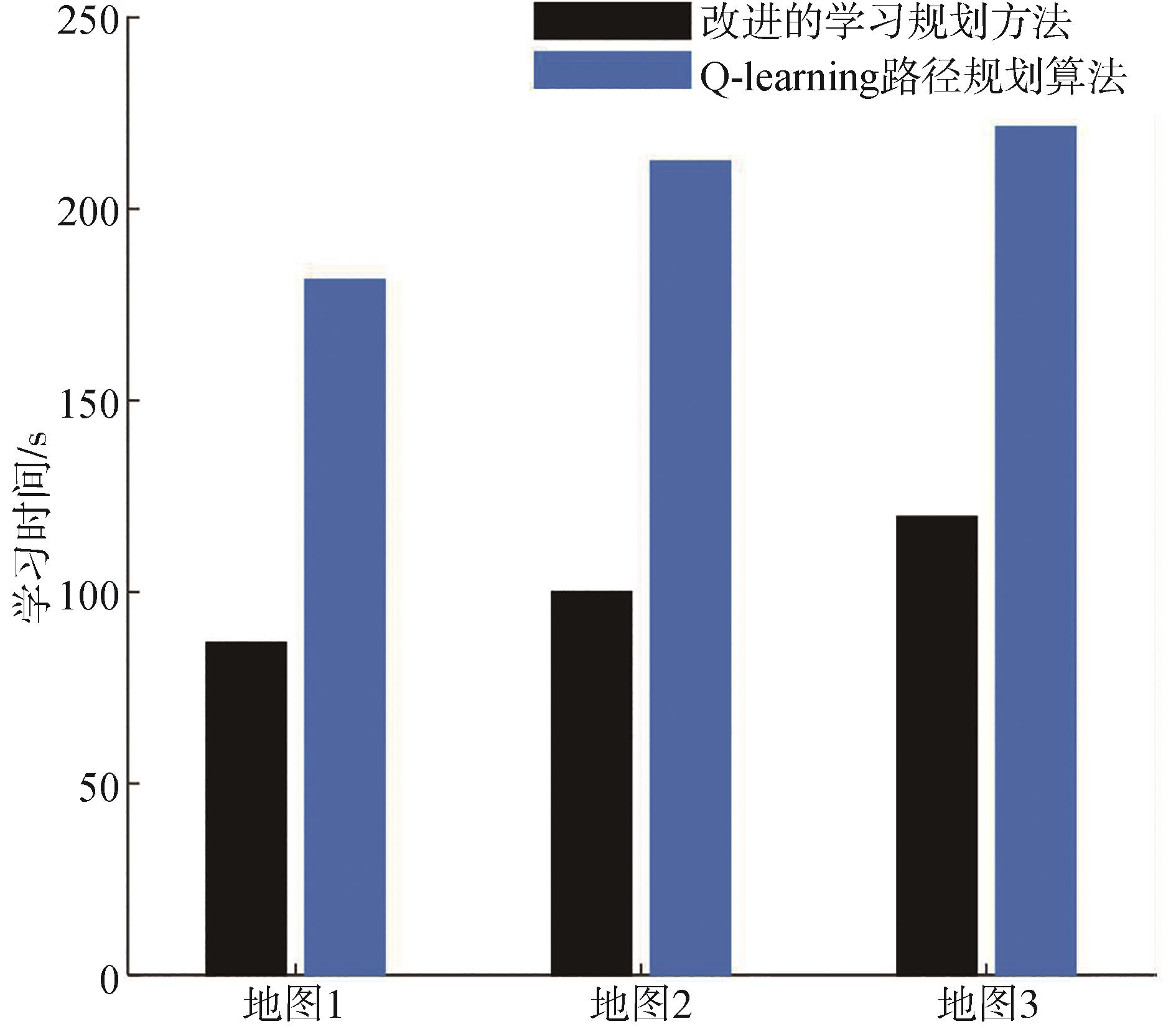
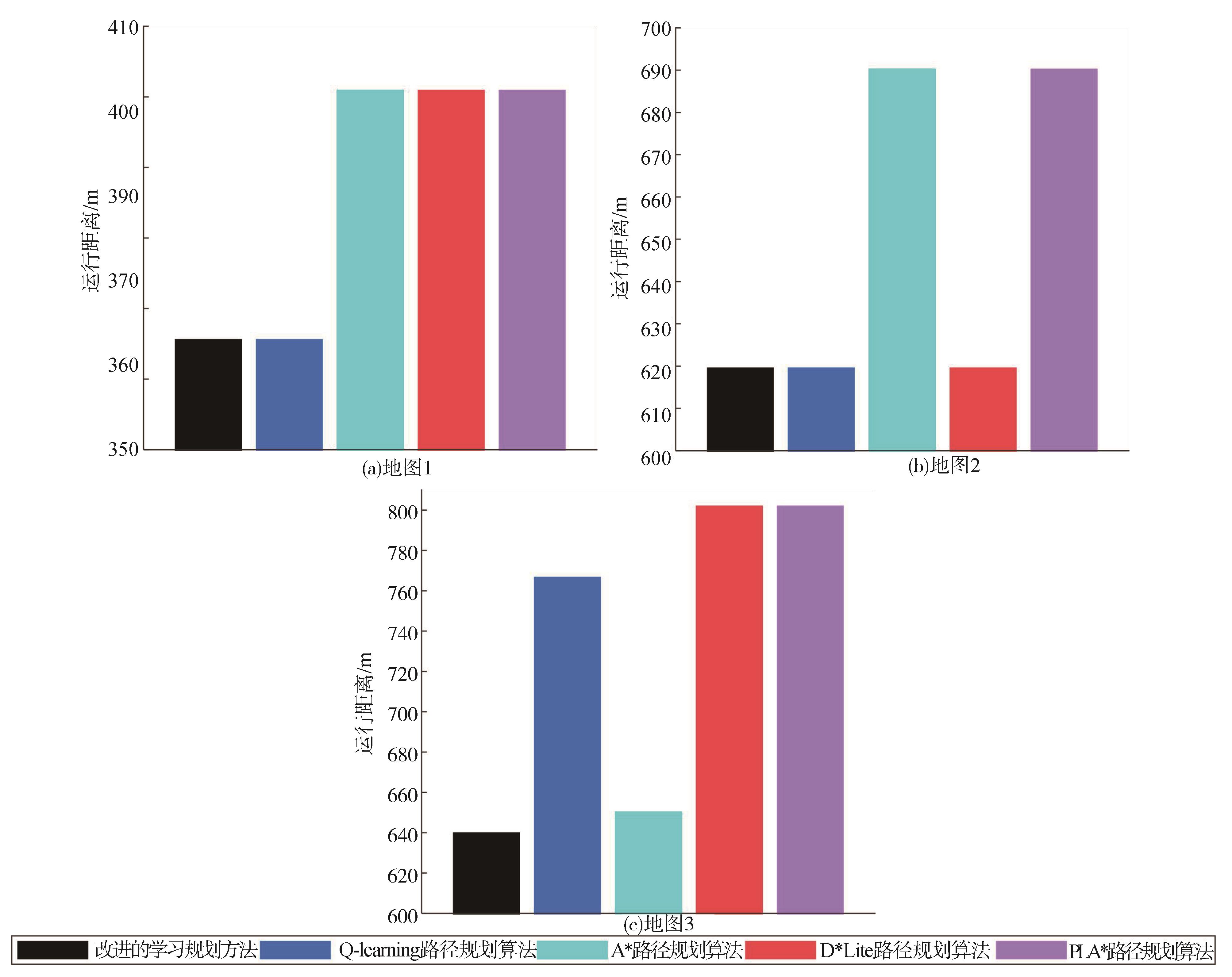
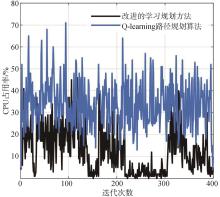
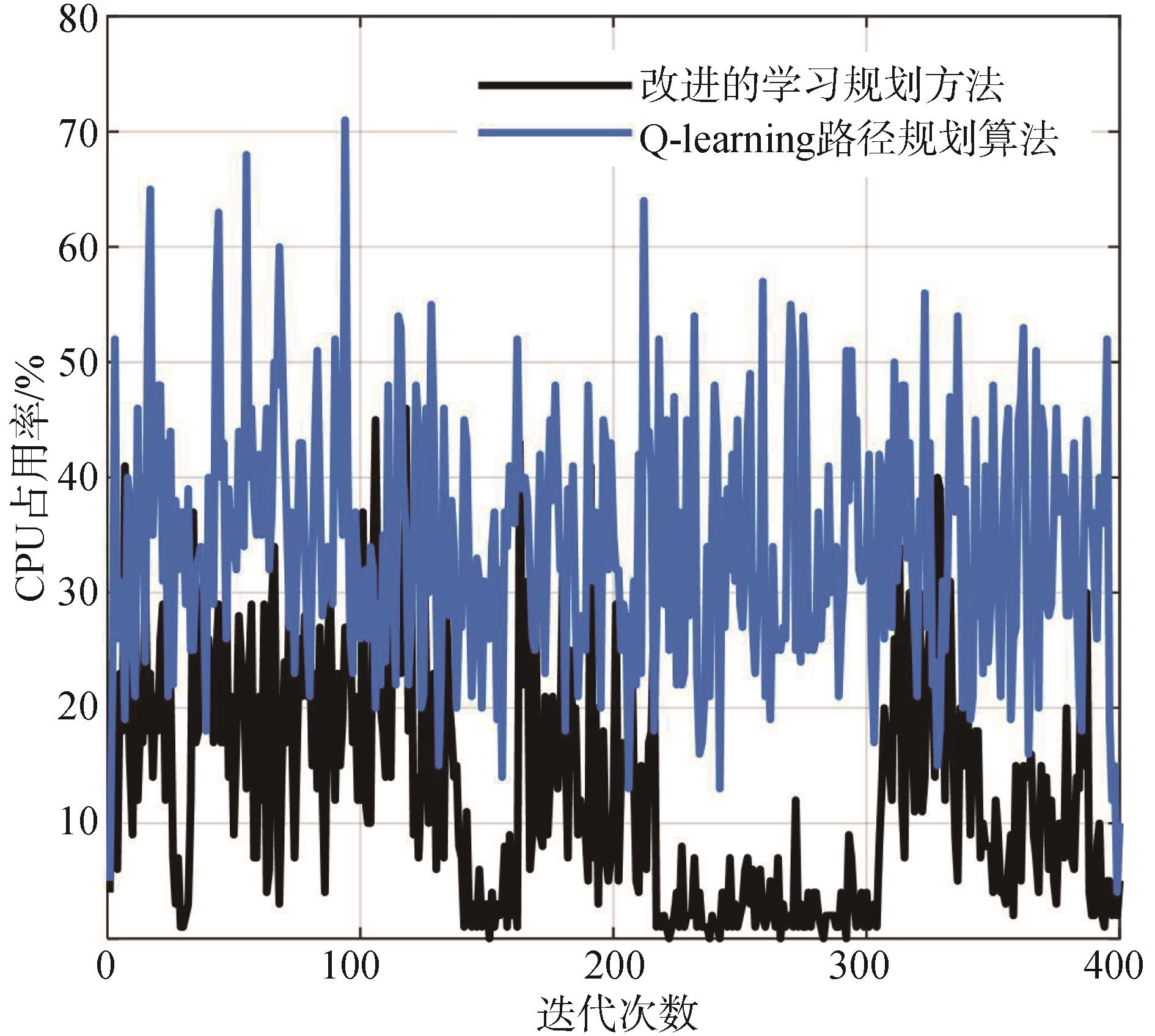
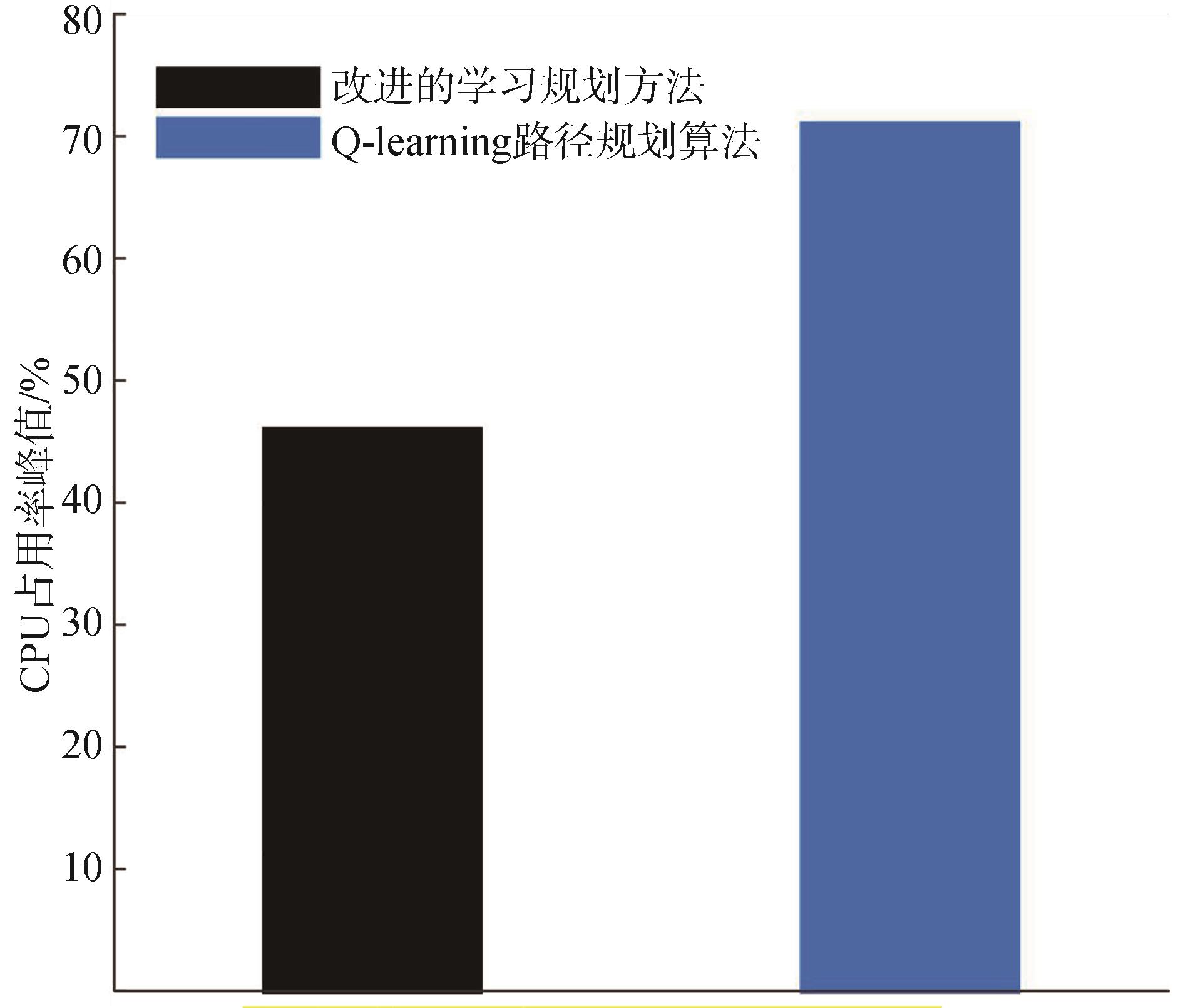
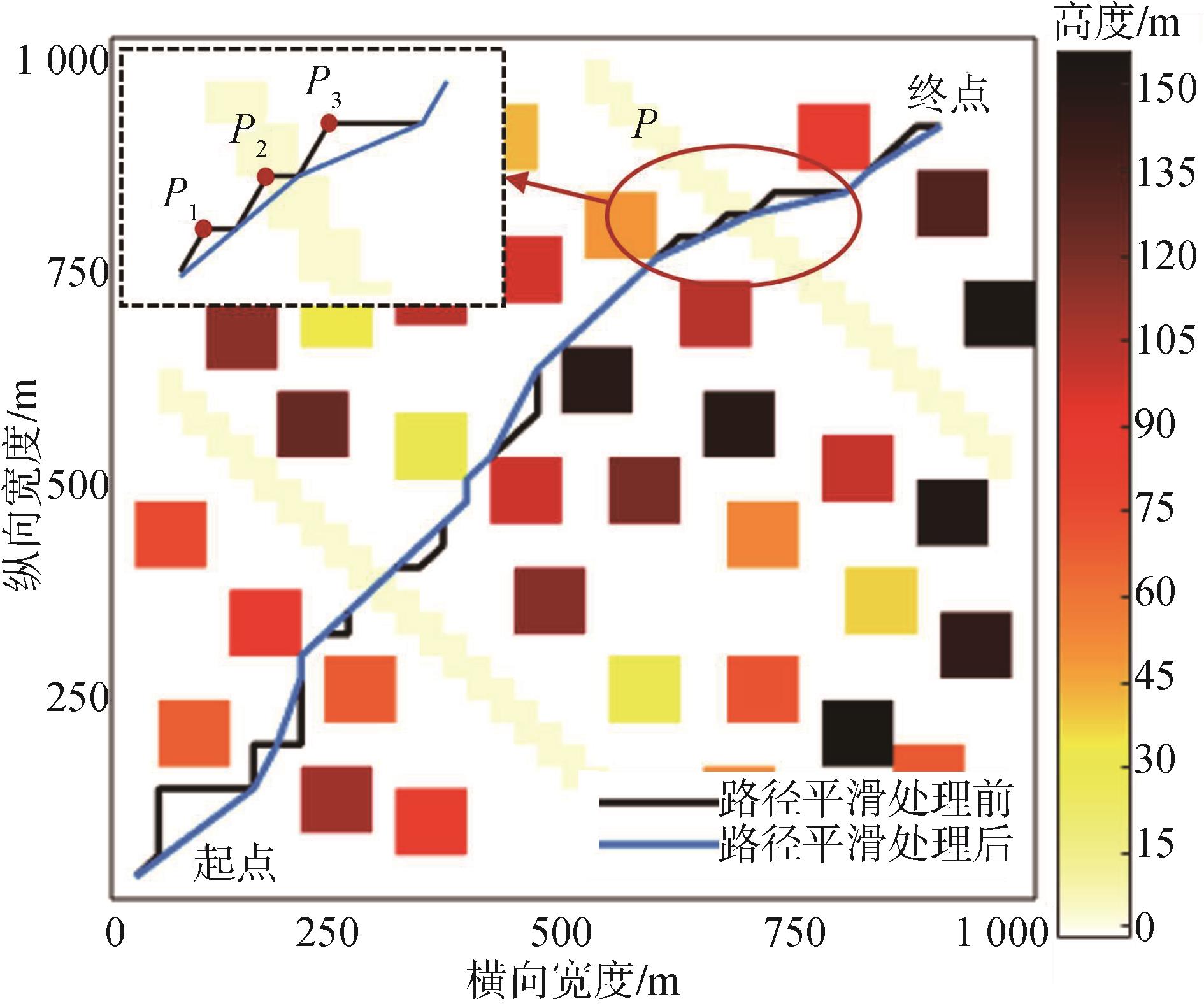
| [1] |
ZHAO J, YANG C, LIU G, et al. A flight-fault-aware path planning strategy for VTOL intelligent air-ground vehicle using game learning approach[J]. IEEE Transactions on Intelligent Vehicles, 2024.
|
| [2] |
HU G, DU B, CHEN K, et al. Super eagle optimization algorithm based three-dimensional ball security corridor planning method for fixed-wing UAVs[J]. Advanced Engineering Informatics, 2024, 59.
|
| [3] |
胡子牛, 陈鑫鹏, 杨泽宇, 等. 具有多型避障方式的智能车辆路径规划[J]. 汽车工程, 2025, 47(3): 402-411.
|
|
HU Z N, CHEN X P, YANG Z Y, et al. Path planning with multiple obstacle-avoidance modes for intelligent vehicles[J]. Automotive Engineering, 2025, 47(3): 402-411.
|
| [4] |
张硕, 邝士奇, 赵轩, 等. 基于全局导向的智能车辆路径规划融合算法研究[J]. 汽车工程, 2024, 46(9): 1546-1555.
|
|
ZHANG S, KUANG S Q, ZHAO X, et al. Research on global oriented path planning fusion algorithm for intelligent vehicles[J]. Automotive Engineering, 2024, 46(9): 1546-1555.
|
| [5] |
ZHAO J, WANG W, YANG C, et al. A new efficient algorithm for short path planning of the vertical take-off and landing air-ground integrated vehicle[J]. Engineering Applications of Artificial Intelligence, 2024, 127.
|
| [6] |
MA D, HAO S, MA W, et al. An optimal control-based path planning method for unmanned surface vehicles in complex environments[J]. Ocean Engineering, 2022, 245.
|
| [7] |
金立生, 韩广德, 谢宪毅, 等. 基于强化学习的自动驾驶决策研究综述[J]. 汽车工程, 2023, 45(4): 527-540.
|
|
JIN L S, HAN G D, XIE X Y, et al. Review of autonomous driving decision-making research based on reinforcement learning[J]. Automotive Engineering, 2023, 45(4): 527-540.
|
| [8] |
赵靖, 王伟达, 杨超, 等. 一种兼顾运行距离与能耗的飞行车辆多模态任务路线规划方法[J]. 机械工程学报, 2025, 61(2): 222-235.
|
|
ZHAO J, WANG W D, YANG C, et al. Multi-modal mission route planning method for flying vehicles considering running distance and energy consumption[J]. Journal of Mechanical Engineering, 2025, 61(2): 222-235.
|
| [9] |
LOW E S, ONG P, LOW C Y, et al. Modified Q-learning with distance metric and virtual target on path planning of mobile robot[J]. Expert Systems with Applications, 2022, 199.
|
| [10] |
WU J, SUN Y, LI D, et al. An adaptive conversion speed Q-learning algorithm for search and rescue UAV path planning in unknown environments[J]. IEEE Transactions on Vehicular Technology, 2023, 72(12): 15391-15404.
|
| [11] |
段书用, 章霖鑫, 韩旭, 等. 具有光滑-直行功能的Q-Learning路径优化算法[J]. 机械工程学报, 2022, 58(11): 72-87.
|
|
DUAN S Y, ZHANG L X, HAN X, et al. Smoothed-shortcut Q-learning algorithm for optimal robot agent path planning[J]. Journal of Mechanical Engineering, 2022, 58(11): 72-87.
|
| [12] |
WANG X, HUANG K, ZHANG X, et al. Path planning for air-ground robot considering modal switching point optimization[C]. 2023 International Conference on Unmanned Aircraft Systems (ICUAS), 2023: 87-94.
|
| [13] |
ZHAO J, YANG C, WANG W, et al. A game-learning-based smooth path planning strategy for intelligent air-ground vehicle considering mode switching[J]. IEEE Transactions on Transportation Electrification, 2022, 8(3): 3349-3366.
|
| [14] |
WANG W, CHEN Y, YANG C, et al. An efficient optimal sizing strategy for a hybrid electric air-ground vehicle using adaptive spiral optimization algorithm[J]. Journal of Power Sources, 2022, 517.
|
| [15] |
WANG W, CHEN Y, YANG C, et al. An enhanced hypotrochoid spiral optimization algorithm based intertwined optimal sizing and control strategy of a hybrid electric air-ground vehicle[J]. Energy, 2022, 257.
|
| [16] |
张伟民, 徐森生, 张月. 基于改进A*算法的室内巡检机器人路径规划研究[J]. 机械工程学报, 2024, 60(20): 315-326.
|
|
ZHANG W M, XU S S, ZHANG Y. Research on path planning of indoor inspection robot based on improved A* algorithm[J]. Journal of Mechanical Engineering, 2024, 60(20): 315-326.
|
| [17] |
LIN Z, WU K, SHEN R, et al. An efficient and accurate A-star algorithm for autonomous vehicle path planning[J]. IEEE Transactions on Vehicular Technology, 2024, 73(6): 9003-9008.
|
| [18] |
WATKINS C J C H, DAYAN P. Q-learning[J]. Machine Learning, 1992, 8: 279-292.
|
| [19] |
HART P E, NILSSON N J, RAPHAEL B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107.
|
| [20] |
KOENIG S, LIKHACHEV M. Fast replanning for navigation in unknown terrain[J]. IEEE Transactions on Robotics, 2005, 21(3): 354-363.
|
| [21] |
KOENIG S, LIKHACHEV M, FURCY D. Lifelong planning A∗[J]. Artificial Intelligence, 2004, 155(1-2): 93-146.
|
 ),王伟达1,2,李颖1,2,项昌乐1,2
),王伟达1,2,李颖1,2,项昌乐1,2