汽车工程 ›› 2023, Vol. 45 ›› Issue (8): 1373-1382.doi: 10.19562/j.chinasae.qcgc.2023.08.008
所属专题: 智能网联汽车技术专题-规划&决策2023年
冉巍1,陈慧1( ),杨佳鑫1,西村要介2,国朝鵬2,尹又雨3
),杨佳鑫1,西村要介2,国朝鵬2,尹又雨3
收稿日期:2023-04-11
出版日期:2023-08-25
发布日期:2023-08-17
通讯作者:
陈慧
E-mail:hui-chen@tongji. edu. cn
Wei Ran1,Hui Chen1(),Jiaxin Yang1,Nishimura Yosuke2,Chaopeng Guo2,Youyu Yin3
Received:2023-04-11
Online:2023-08-25
Published:2023-08-17
Contact:
Hui Chen
E-mail:hui-chen@tongji. edu. cn
摘要:
实现个性化且符合驾驶员偏好的运动规划对提高驾驶员对自动驾驶系统接受度具有重要意义。本文提出了一种考虑驾驶员偏好的运动规划奖励函数设计方法。首先,基于效用理论提出了一个量化驾驶员轨迹偏好的双层结构模型,上层效用评估模型量化驾驶员在安全、舒适性和效率之间的权衡过程;下层的驾驶员感知模型量化了驾驶员对安全、舒适性和效率方面的主观感受与轨迹特征指标之间的关系。接着,分别基于评分和配对比较两种评价方法提出了轨迹偏好模型的估计方法。最后,通过驾驶员模拟器评价试验对模型估计方法进行验证,每个试验者分别采用评分和配对比较的方式对多条轨迹进行了主观评价。基于获取的两种评价结果及计算得到的轨迹特征,分别用两种方法对驾驶员轨迹偏好模型进行了估计。结果表明,提出的模型能够较为准确地描述驾驶员的偏好评价过程,而基于配对比较的模型估计结果则更准确。
冉巍,陈慧,杨佳鑫,西村要介,国朝鵬,尹又雨. 基于效用理论的运动规划奖励函数设计方法[J]. 汽车工程, 2023, 45(8): 1373-1382.
Wei Ran,Hui Chen,Jiaxin Yang,Nishimura Yosuke,Chaopeng Guo,Youyu Yin. Design Method of Motion Planning Reward Function Based on Utility Theory[J]. Automotive Engineering, 2023, 45(8): 1373-1382.
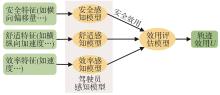
图1
基于效用理论的轨迹偏好模型"
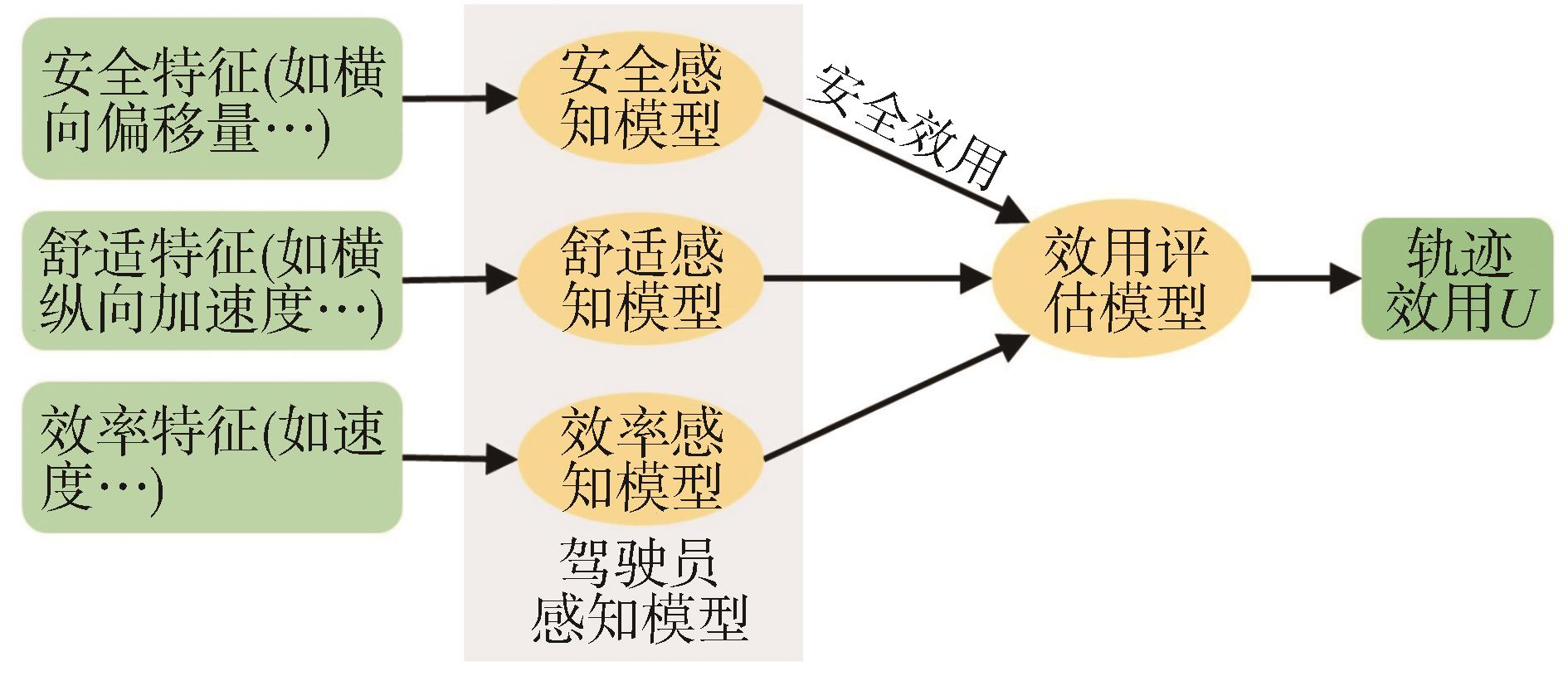
表1
计算轨迹特征总结"
| 类别 | 变量 | 特征个数:特征 |
|---|---|---|
| 安全 | 横向偏移量 | 6:左/右偏移最大/平均值,左右偏移范围大小,最大偏移量 |
跨道时间 (STLC & CTLC,2种) | 8:左侧/右侧车道线跨道时间最小值/均值及其倒数 | |
| TAD | 2:最小值,平均值 | |
| 舒适 | 横向加速度, 纵向加、减速度 | 2:最大值,平均值 |
| 加加速度 | 2:最大值,平均值 | |
| 横摆角速度 | 2:最大值,平均值 | |
| 横摆角加速度 | 2:最大值,平均值 | |
| WARMS | 1 | |
| 效率 | 速度 | 3:最大值,最小值,平均值 |

图2
驾驶模拟器构造(上)及实物图(下)"
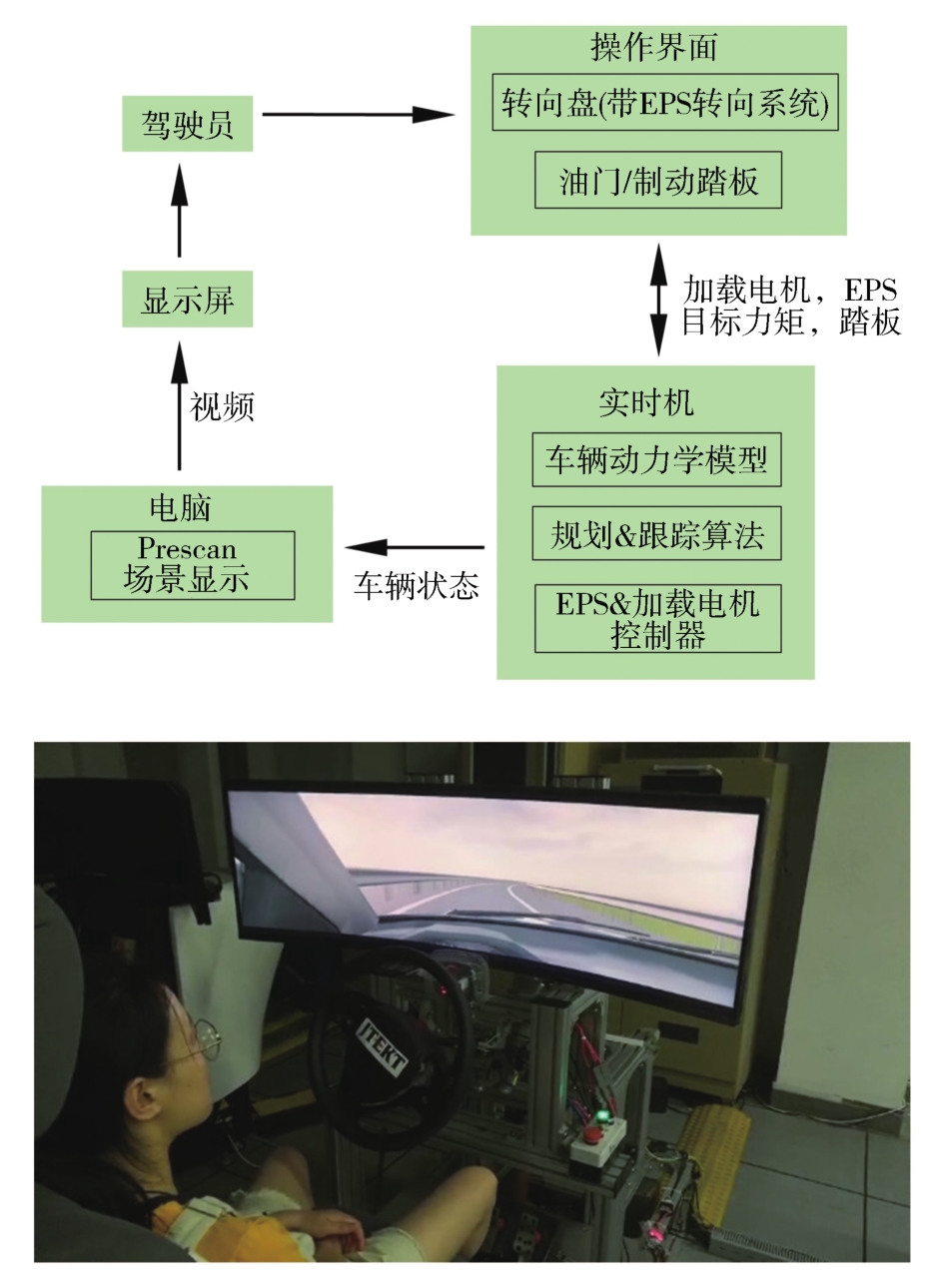
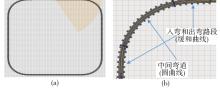
图3
封闭试验场景(左)及每个弯道形状(右)"

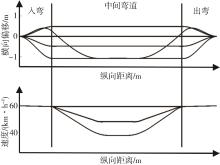
图4
通过设置不同规划参数得到的不同弯道路径(上)和速度曲线(下)"
表2
参与试验驾驶员信息统计"
| 项目 | 年平均驾驶里程/km | 年龄 |
|---|---|---|
| 均值 | 19 620 | 32.75 |
| 标准差 | 22 714 | 10.34 |
表3
评分用李克特量表"
| 评价项 | 打分表 | 分数 |
|---|---|---|
| 1.感到很安全 | 1(不符合)- 5(非常符合) | |
| 2.乘坐很舒适 | 1(不符合)- 5(非常符合) | |
| 3.过弯很快有效率 | 1(不符合)- 5(非常符合) | |
| 4.喜欢这种驾驶方式 | 1(不符合)- 5(非常符合) |
表4
比较评价用问卷"
| 评价项 | 备选项 | ||
|---|---|---|---|
| 1.哪一个更安全 | 第一个 | 第二个 | 差不多 |
| 2.哪一个乘坐更舒适 | 第一个 | 第二个 | 差不多 |
| 3.哪一个过弯更有效率 | 第一个 | 第二个 | 差不多 |
| 4.更喜欢哪种驾驶方式 | 第一个 | 第二个 | 差不多 |
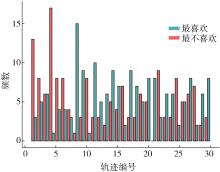
图5
驾驶员最喜欢和最不喜欢轨迹分布"
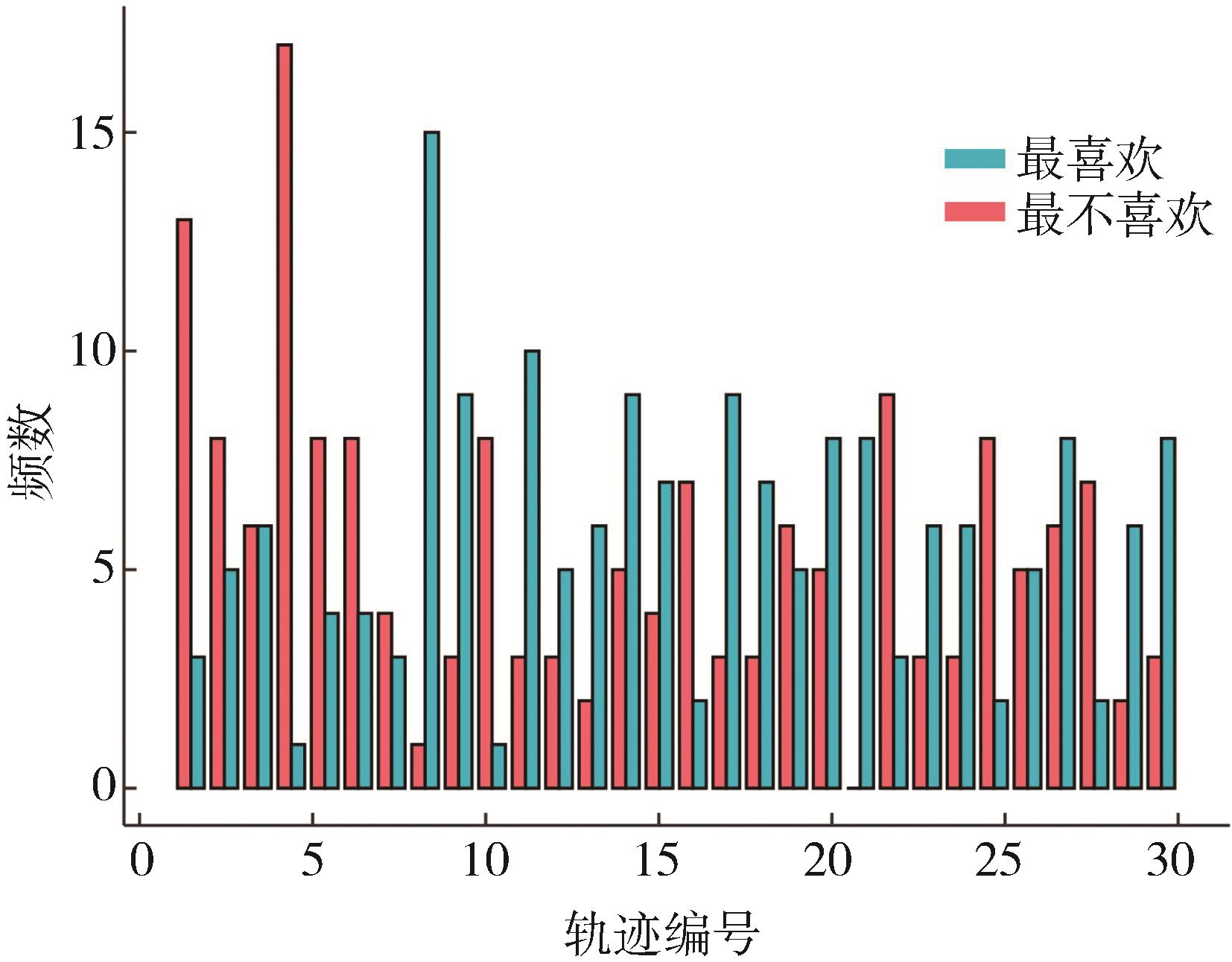

图6
驾驶员最喜欢2条轨迹和最不喜欢2条轨迹的路径(上)和速度(下)"
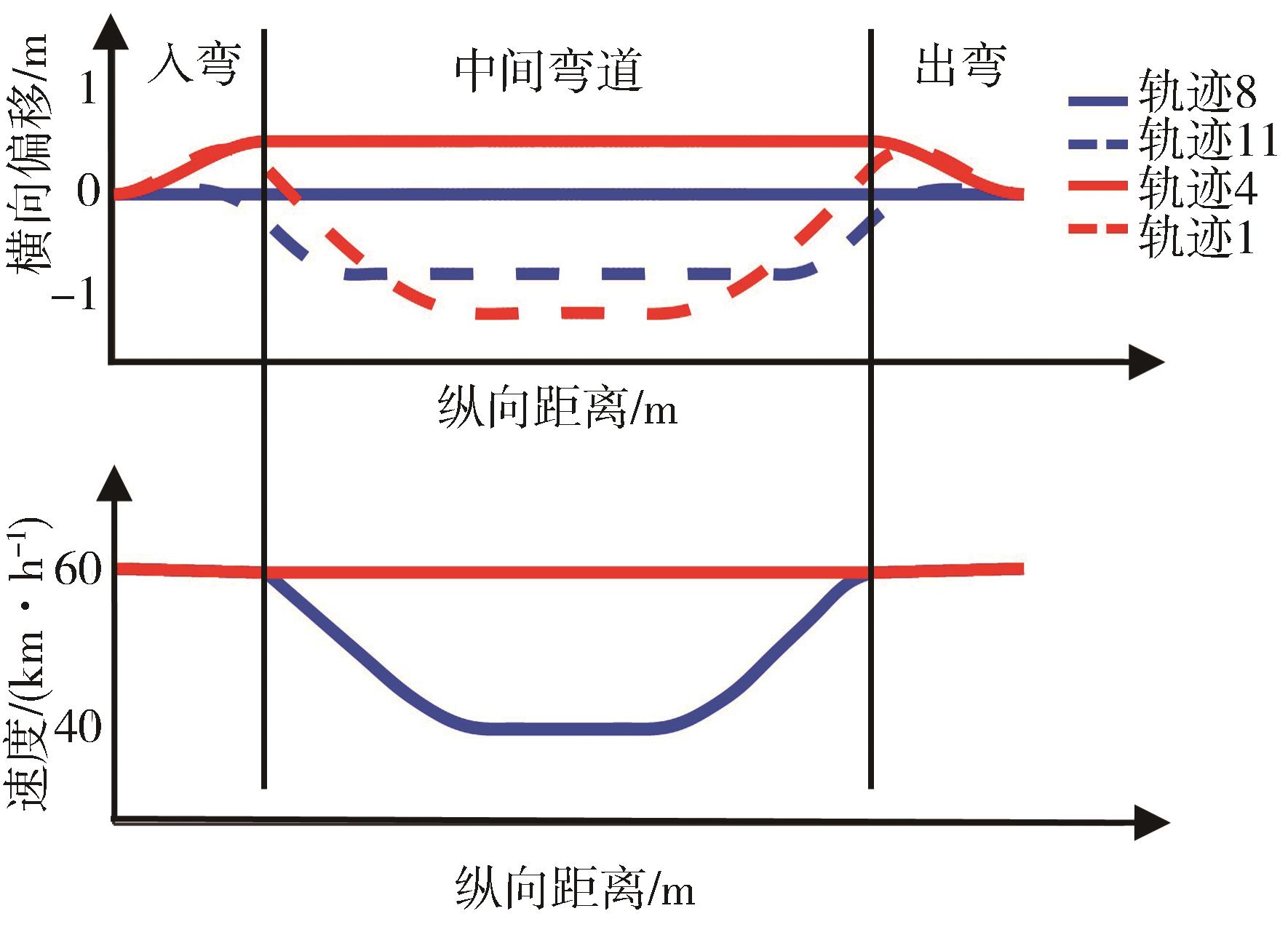
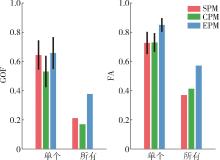
图7
基于评分DPM的模型结果"
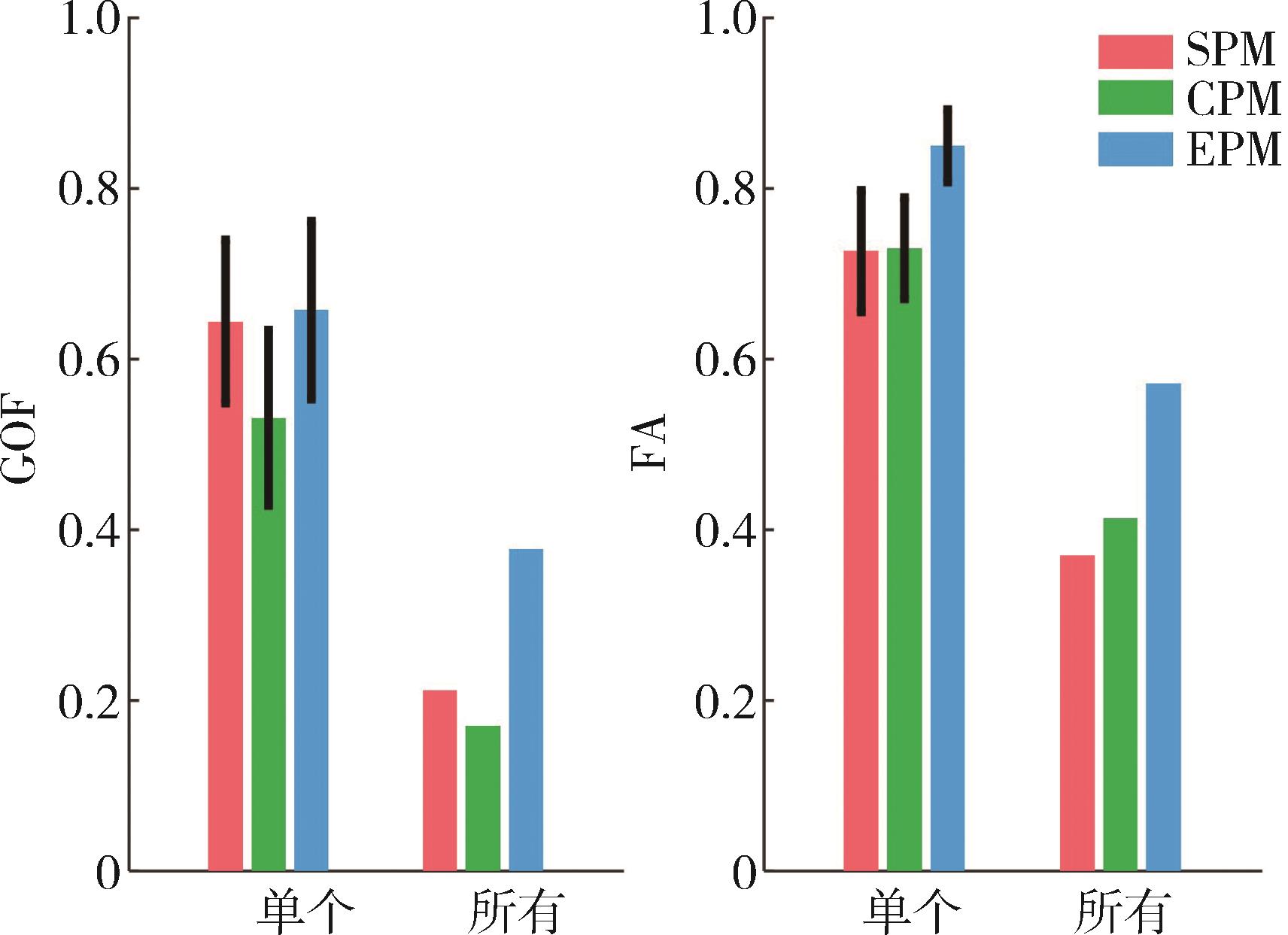
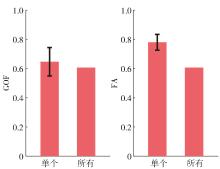
图8
基于评分UEM的模型结果"
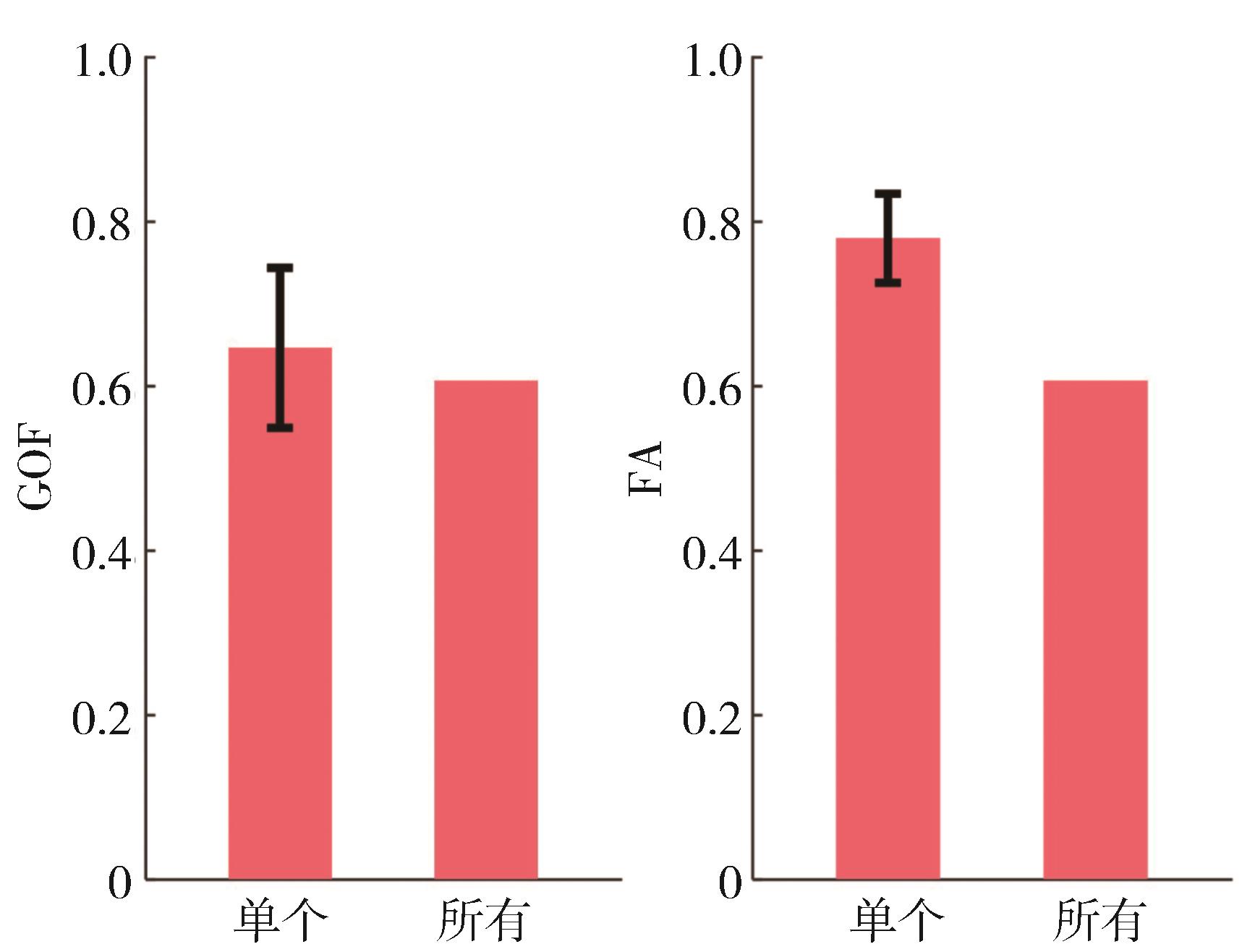
图9
基于比较DPM的模型结果"

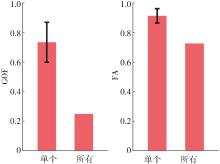
图10
基于评分UEM的模型结果"
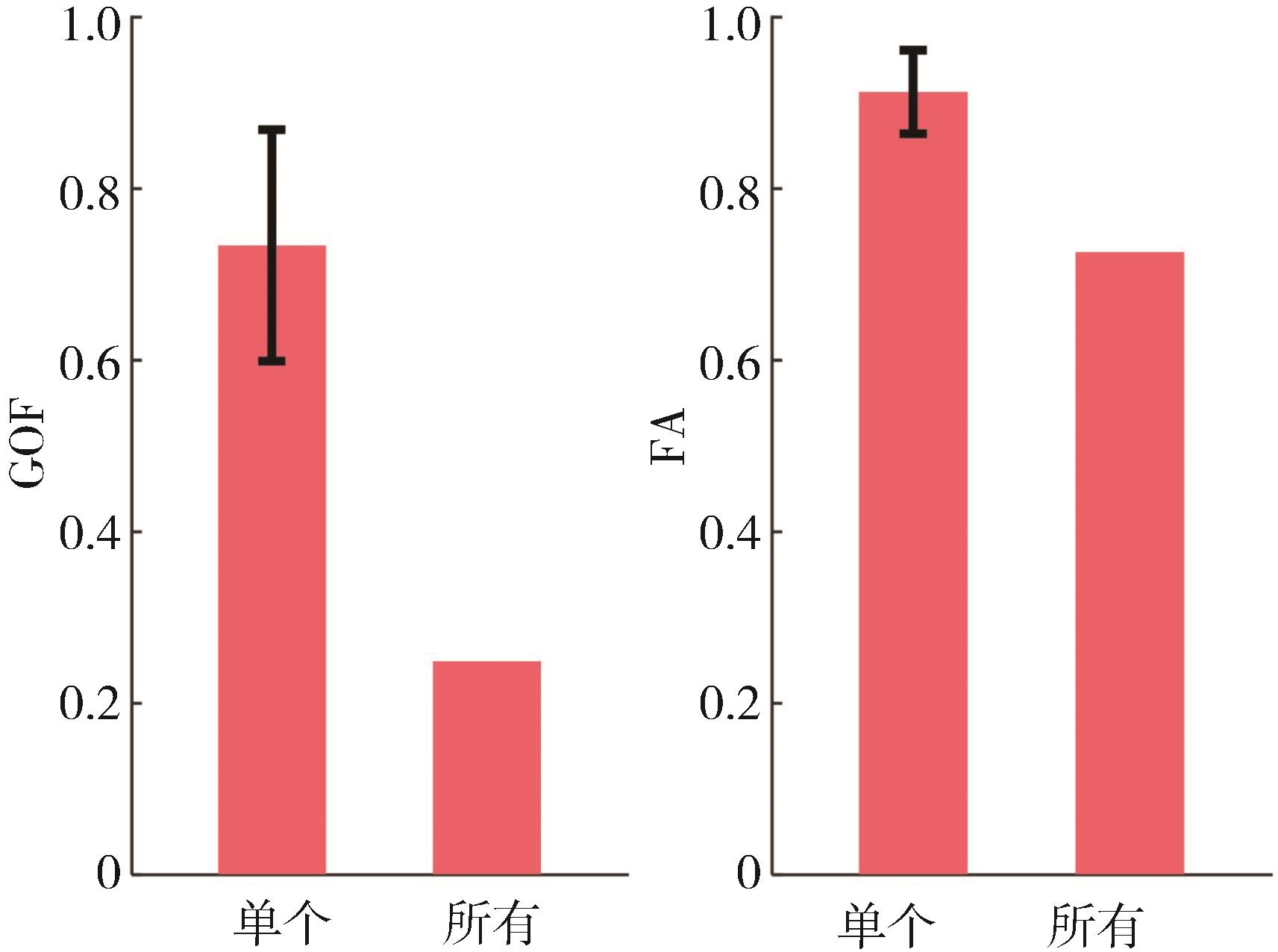
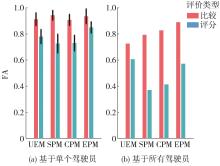
图11
两种评价方式下模型FA对比"

表5
模型选择轨迹特征比较分析"
| 模型 | 评价 方式 | 特征1(数量) | 特征2(数量) | 特征3(数量) |
|---|---|---|---|---|
| SPM | 评分 | 右侧偏移 均值(5) | 左车道线ITLC 最大值(4) | 左侧偏移均值 (4) |
| 比较 | TAD均值 (6) | 左侧偏移均值 (5) | 右侧偏移最大值 (4) | |
| CPM | 评分 | 左侧偏移 均值(4) | 平均减速度 (4) | 左车道线ITLC 最大值(3) |
| 比较 | 左车道线 STLC均值(4) | 左侧偏移均值 (3) | 左侧偏移 最大值(2) | |
| EPM | 评分 | 平均速度 (7) | 平均减速度 (3) | 平均横摆角 加速度(3) |
| 比较 | 最大横向 偏移(6) | 右侧偏移均值 (3) | 平均减速度 (3) |
| 1 | HASENJÄGER M, WERSING H. Personalization in advanced driver assistance systems and autonomous vehicles: a review[C]. 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2017: 1-7. |
| 2 | YI D, SU J, HU L, et al. Implicit personalization in driving assistance: state-of-the-art and open issues[J]. IEEE Transactions on Intelligent Vehicles, 2019, 5(3): 397-413. |
| 3 | XU D, DING Z, HE X, et al. Learning from naturalistic driving data for human-like autonomous highway driving[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 22(12): 7341-7354. |
| 4 | ZIEGLER J, BENDER P, DANG T, et al. Trajectory planning for Bertha—A local, continuous method[C]. 2014 IEEE Intelligent Vehicles Symposium Proceedings. IEEE, 2014: 450-457. |
| 5 | MALIK S, KHAN M A, EL-SAYED H, et al. How do autonomous vehicles decide?[J]. Sensors, 2022, 23(1): 317. |
| 6 | SUTTON R S, BARTO A G. Reinforcement learning: an introduction[M]. MIT Press, 2018. |
| 7 | LU C, GONG J, LV C, et al. A personalized behavior learning system for human-like longitudinal speed control of autonomous vehicles[J]. Sensors, 2019, 19(17): 3672. |
| 8 | ZHU M, WANG X, WANG Y. Human-like autonomous car-following model with deep reinforcement learning[J]. Transportation Research Part C: Emerging Technologies, 2018, 97: 348-368. |
| 9 | XIE J, XU X, WANG F, et al. Modeling human-like longitudinal driver model for intelligent vehicles based on reinforcement learning[J]. Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering, 2021, 235(8): 2226-2241. |
| 10 | REDDY S, DRAGAN A, LEVINE S, et al. Learning human objectives by evaluating hypothetical behavior[C]. International Conference on Machine Learning. PMLR, 2020: 8020-8029. |
| 11 | ABBEEL P, NG A Y. Apprenticeship learning via inverse reinforcement learning[C]. Proceedings of the Twenty-First International Conference on Machine Learning, 2004: 1. |
| 12 | WU Z, QU F, YANG L, et al. Human-like decision making for autonomous vehicles at the intersection using inverse reinforcement learning[J]. Sensors, 2022, 22(12): 4500. |
| 13 | KUDERER M, GULATI S, BURGARD W. Learning driving styles for autonomous vehicles from demonstration[C]. 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015: 2641-2646. |
| 14 | NAGAHAMA A, SAITO T, WADA T, et al. Autonomous driving learning preference of collision avoidance maneuvers[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 22(9): 5624-5634. |
| 15 | ZIEBART B D, MAAS A L, BAGNELL J A, et al. Maximum entropy inverse reinforcement learning[C]. Aaai. 2008, 8: 1433-1438. |
| 16 | 宋东鉴,朱冰,赵健,等. 基于驾驶行为生成机制的智能汽车类人行为决策[J]. 汽车工程, 2022, 44(12): 1797-1808. |
| SONG D J, ZHU B, ZHAO J, et al. Human-like behavior decision-making of intelligent vehicles based on driving behavior generation mechanism[J]. Automotive Engineering, 2022, 44(12): 1797-1808. | |
| 17 | KÄTHNER D, GRIESCHE S. Should my vehicle drive as I do? A methodology to determine drivers, preference for automated driving styles[C]. TEAP 2017. 2017. |
| 18 | BASU C, YANG Q, HUNGERMAN D, et al. Do you want your autonomous car to drive like you?[C]. Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, 2017: 417-425. |
| 19 | YUSOF N M, KARJANTO J, TERKEN J, et al. The exploration of autonomous vehicle driving styles: preferred longitudinal, lateral, and vertical accelerations[C]. Proceedings of the 8th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, 2016: 245-252. |
| 20 | HORSWILL M S, MCKENNA F P. The effect of perceived control on risk taking 1[J]. Journal of Applied Social Psychology, 1999, 29(2): 377-391. |
| 21 | 赵斌,陈慧,冉巍,等.车道对中控制系统的驾驶员自适应需求验证[J].汽车技术, 2021(3):1-6. |
| ZHAO B, CHEN H, RAN W, et al. Study on the necessity of designing personalized lane centering control system [J].Automobile Technolody, 2021(3):1-6. | |
| 22 | KEENEY R L, RAIFFA H. Decisions with multiple objectives: preferences and value trade-offs[M]. Cambridge University Press, 1993. |
| 23 | BEN-AKIVA M E, LERMAN S R, LERMAN S R. Discrete choice analysis: theory and application to travel demand[M]. MIT Press, 1985. |
| 24 | DEUBEL C, ERNST S, PROKOP G. Objective evaluation methods of vehicle ride comfort-a literature review[J]. Journal of Sound and Vibration, 2022: 117515. |
| 25 | ZONG C, GUO K, GUAN H. Research on closed-loop comprehensive evaluation method of vehicle handling and stability[C]. SAE Paper 2000-01-0694. |
| 26 | JOHANNES F, EYKE H. Preference learning[M]. Berlin & Heidelberg: Springer, 2010. |
| 27 | MARTINEZ C M, HEUCKE M, WANG F Y, et al. Driving style recognition for intelligent vehicle control and advanced driver assistance: a survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 19(3): 666-676. |
| 28 | 郭子彬,陈慧,夏韬锴,等. 弯道工况下驾驶员主观风险感知的量化研究[J]. 汽车工程, 2022, 44(9): 1447-1455. |
| GUO Z B, CHEN H, XIA T K,et al. Study on quantification of driver’s subjective risk perception in curve driving condition[J]. Automotive Engineering, 2022, 44(9): 1447-1455. | |
| 29 | 余志生. 汽车理论[M]. 5版.北京: 机械工业出版社, 2009. |
| YU Z S. Automobile theory [M]. 5th ed. Beijing: China Machine Press, 2009. | |
| 30 | MANSFIELD N J, WHITING-LEWIS E. Correlation between objective and subjective measures of automobile ride comfort for 1203 drivers[C]. 18th International Congress on Acoustics, Kyoto, Japan. 2004. |
| 31 | KIM M S, KIM K W, YOO W S. Method to objectively evaluate subjective ratings of ride comfort[J]. International Journal of Automotive Technology, 2011, 12: 831-837. |
| 32 | AO D, WONG P K, HUANG W, et al. Analysis of co-relation between objective measurement and subjective assessment for dynamic comfort of vehicles[J]. International Journal of Automotive Technology, 2020, 21: 1553-1567. |
| 33 | CAO H, ZHAO S, SONG X, et al. An optimal hierarchical framework of the trajectory following by convex optimisation for highly automated driving vehicles[J]. Vehicle System Dynamics, 2019, 57(9): 1287-1317. |
| 34 | HOFFMANN G M, TOMLIN C J, MONTEMERLO M, et al. Autonomous automobile trajectory tracking for off-road driving: controller design, experimental validation and racing[C]. 2007 American Control Conference. IEEE, 2007: 2296-2301. |
| [1] | 赵晓聪,房世玉,李子睿,孙剑. 社会性驾驶交互关键效用析取与应用[J]. 汽车工程, 2024, 46(2): 230-240. |
| [2] | 刘卫国,项志宇,刘锐,李国栋,王子旭. 基于深度学习的端到端车辆运动规划方法研究[J]. 汽车工程, 2023, 45(8): 1343-1352. |
| [3] | 王明,唐小林,杨凯,李国法,胡晓松. 考虑预测风险的自动驾驶车辆运动规划方法[J]. 汽车工程, 2023, 45(8): 1362-1372. |
| [4] | 高锋,冯德福,胡秋霞. 面向NMPC运动规划系统的数值优化加速技术[J]. 汽车工程, 2023, 45(8): 1438-1447. |
| [5] | 林程, 汪博文, 吕沛原, 宫新乐, 于潇. 面向变曲率道路的自动驾驶汽车换道博弈运动规划与协同控制研究[J]. 汽车工程, 2023, 45(7): 1099-1111. |
| [6] | 崔格格,吕超,李景行,张哲雨,熊光明,龚建伟. 数据驱动的智能车个性化场景风险图构建[J]. 汽车工程, 2023, 45(2): 231-242. |
| [7] | 兰凤崇,刘迎节,陈吉清,刘照麟. 基于动态博弈算法的切入场景下自动驾驶车辆运动规划研究[J]. 汽车工程, 2023, 45(1): 9-19. |
| [8] | 朱乃宣,高振海,胡宏宇,吕颖,赵伟光. 基于交通风险评估的个性化换道触发研究[J]. 汽车工程, 2021, 43(9): 1314-1321. |
| [9] | 兰凤崇,李诗成,陈吉清,沈宗卯. 自动驾驶汽车乘员个性化乘坐舒适性辨识方法[J]. 汽车工程, 2021, 43(8): 1168-1176. |
| [10] | 王安杰,郑玲,李以农,王戡. 基于预测风险场的智能汽车主动避撞运动规划[J]. 汽车工程, 2021, 43(7): 1096-1104. |
| [11] | 田洪清,丁峰,郑讯佳,黄荷叶,王建强. 基于势能场虚拟力的智能网联车辆运动规划[J]. 汽车工程, 2021, 43(4): 518-526. |
| [12] | 张一鸣, 周兵, 吴晓建, 崔庆佳, 柴天. 基于前车轨迹预测的高速智能车运动规划*[J]. 汽车工程, 2020, 42(5): 574-580. |
|