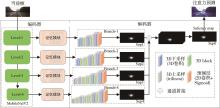
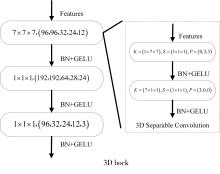
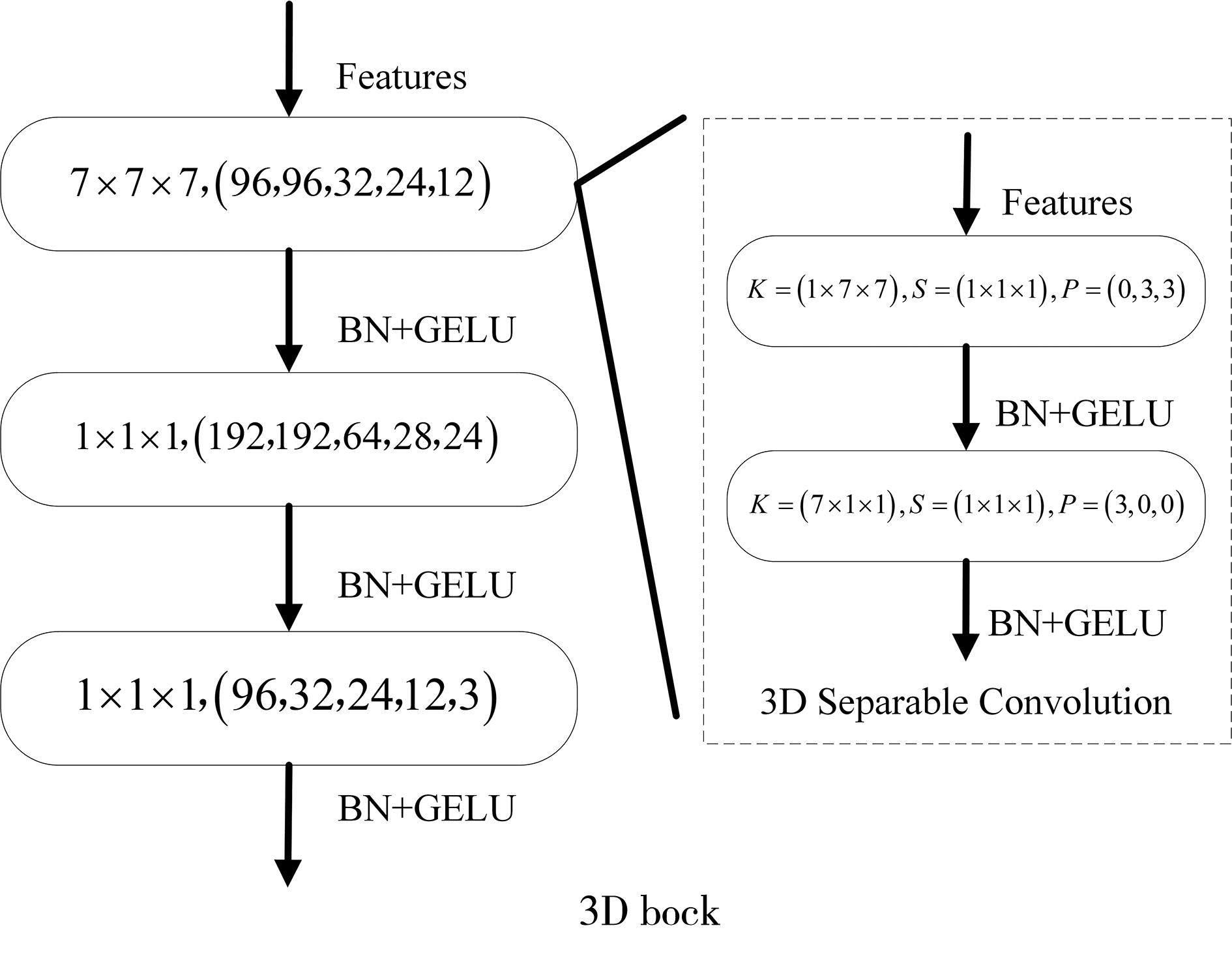
| 1 |
GUO B, JIN L, SUN D, et al. Establishment of the characteristic evaluation index system of secondary task driving and analyzing its importance[J]. Transportation Research Part F: Traffic Psychology and Behaviour, 2019, 64: 308-317.
|
| 2 |
刘军, 陈岚磊, 李汉冰. 基于类人视觉的多任务交通目标实时检测模型[J]. 汽车工程, 2021, 43(1):50-58.
|
|
LIU J, CHEN L L, LI H B. A real⁃time detection model for multi⁃task traffic objects based on humanoid vision[J]. Automotive Engineering, 2021, 43(1): 50-58.
|
| 3 |
FRIDMAN L. Human-centered autonomous vehicle systems: Principles of effective shared autonomy[J]. arXiv Preprint arXiv:,2018.
|
| 4 |
WOLFE J M, HOROWITZ T S. Five factors that guide attention in visual search[J]. Nature Human Behaviour, 2017, 1(3): 1-8.
|
| 5 |
WANG W, SHEN J, GUO F, et al. Revisiting video saliency: a large-scale benchmark and a new model[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4894-4903.
|
| 6 |
HUO D, MA J, CHANG R. Lane-changing-decision characteristics and the allocation of visual attention of drivers with an angry driving style[J]. Transportation Research Part F: Traffic Psychology and Behaviour, 2020, 71: 62-75.
|
| 7 |
KIRCHER K, AHLSTROM C. Minimum required attention: a human-centered approach to driver inattention[J]. Human Factors, 2017, 59(3): 471-484.
|
| 8 |
CAVANAGH P, ALVAREZ G A. Tracking multiple targets with multifocal attention[J]. Trends in Cognitive Sciences, 2005, 9(7): 349-354.
|
| 9 |
陈骥驰, 王宏, 王翘秀, 等. 基于脑电信号的疲劳驾驶状态研究[J]. 汽车工程, 2018, 40(5): 515-520.
|
|
CHEN J C, WANG H, WANG Q X, et al. A study on drowsy driving state based on EEG signals[J]. Automotive Engineering, 2018, 40(5): 515-520.
|
| 10 |
华强, 金立生, 郭柏苍, 等. 一种混行环境下驾驶人认知分心识别方法[J]. 吉林大学学报(工学版), 2022, 52(8): 1800-1807.
|
|
HUA Q, JIN L S, GUO B C, et al. A recognition method for driver’s cognitive distraction in simulated mixed traffic environment[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(8): 1800-1807.
|
| 11 |
马勇, 付锐.驾驶人视觉特性与行车安全研究进展[J].中国公路学报,2015,28(6):82-94.
|
|
MA Y, FU R. Research and development of drivers visual behavior and driving safety[J]. China Journal of Highway and Transport, 2015, 28(6): 82-94.
|
| 12 |
ALLETTO S, PALAZZI A, SOLERA F, et al. DR (eye) VE: a dataset for attention-based tasks with applications to autonomous and assisted driving[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2016: 54-60.
|
| 13 |
PALAZZI A, SOLERA F, CALDERARA S, et al. Learning where to attend like a human driver[C]. 2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017: 920-925.
|
| 14 |
PALAZZI A, ABATI D, SOLERA F, et al. Predicting the driver's focus of attention: the DR (eye) VE project[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(7): 1720-1733.
|
| 15 |
XU H, GAO Y, YU F, et al. End-to-end learning of driving models from large-scale video datasets[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2174-2182.
|
| 16 |
XIA Y, ZHANG D, KIM J, et al. Predicting driver attention in critical situations[C]. Asian Conference on Computer Vision. Springer, Cham, 2018: 658-674.
|
| 17 |
DENG T, YAN H, QIN L, et al. How do drivers allocate their potential attention? driving fixation prediction via convolutional neural networks[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(5): 2146-2154.
|
| 18 |
FANG J, YAN D, QIAO J, et al. Dada-2000: can driving accident be predicted by driver attentionƒ analyzed by a benchmark[C]. 2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE, 2019: 4303-4309.
|
| 19 |
FANG J, YAN D, QIAO J, et al. DADA: driver attention prediction in driving accident scenarios[J]. IEEE Transactions on Intelligent Transportation Systems, 2021.
|
| 20 |
LI Q, LIU C, CHANG F, et al. Adaptive short-temporal induced aware fusion network for predicting attention regions like a driver[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(10): 18695-18706.
|
| 21 |
CHANG Q, ZHU S. Temporal-spatial feature pyramid for video saliency detection[J]. arXiv Preprint arXiv:, 2021.
|
| 22 |
WANG Z, LIU Z, LI G, et al. Spatio-temporal self-attention network for video saliency prediction[J]. IEEE Transactions on Multimedia, 2021.
|
| 23 |
BELLITTO G, PROIETTO SALANITRI F, PALAZZO S, et al. Hierarchical domain-adapted feature learning for video saliency prediction[J]. International Journal of Computer Vision, 2021, 129(12): 3216-3232.
|
| 24 |
SANDLER M, HOWARD A, ZHU M, et al. Mobilenetv2: inverted residuals and linear bottlenecks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520.
|
| 25 |
LIU Z, MAO H, WU C Y, et al. A convnet for the 2020s[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 11976-11986.
|
| 26 |
XIE S, SUN C, HUANG J, et al. Rethinking spatiotemporal feature learning: speed-accuracy trade-offs in video classification[C]. Proceedings of the European Conference on Computer Vision (ECCV), 2018: 305-321.
|
| 27 |
BYLINSKII Z, JUDD T, OLIVA A, et al. What do different evaluation metrics tell us about saliency models?[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(3): 740-757.
|
| 28 |
ITTI L, KOCH C. Computational modelling of visual attention[J]. Nature Reviews Neuroscience, 2001, 2(3): 194-203.
|
| 29 |
HUANG X, SHEN C, BOIX X, et al. Salicon: reducing the semantic gap in saliency prediction by adapting deep neural networks[C]. Proceedings of the IEEE International Conference on Computer Vision, 2015: 262-270.
|
| 30 |
HAREL J, KOCH C, PERONA P. Graph-based visual saliency[J]. Advances in Neural Information Processing Systems, 2006, 19.
|
| 31 |
LI J, LEVINE M D, AN X, et al. Visual saliency based on scale-space analysis in the frequency domain[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 35(4): 996-1010.
|
| 32 |
CORNIA M, BARALDI L, SERRA G, et al. A deep multi-level network for saliency prediction[C]. 2016 23rd International Conference on Pattern Recognition (ICPR). IEEE, 2016: 3488-3493.
|
| 33 |
ZHANG K, CHEN Z. Video saliency prediction based on spatial-temporal two-stream network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 29(12): 3544-3557.
|
| 34 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
|
 )
)