汽车工程 ›› 2022, Vol. 44 ›› Issue (12): 1797-1808.doi: 10.19562/j.chinasae.qcgc.2022.12.001
所属专题: 智能网联汽车技术专题-感知&HMI&测评2022年
• • 下一篇
宋东鉴,朱冰,赵健( ),韩嘉懿,刘彦辰
),韩嘉懿,刘彦辰
收稿日期:2022-04-29
修回日期:2022-06-06
出版日期:2022-12-25
发布日期:2022-12-22
通讯作者:
赵健
E-mail:zhaojian@jlu.edu.cn
基金资助:
Dongjian Song,Bing Zhu,Jian Zhao(),Jiayi Han,Yanchen Liu
Received:2022-04-29
Revised:2022-06-06
Online:2022-12-25
Published:2022-12-22
Contact:
Jian Zhao
E-mail:zhaojian@jlu.edu.cn
摘要:
本文通过分析驾驶人驾驶行为生成机制,构建了类人行为决策策略(HBDS)。它具有匹配驾驶行为生成机制的策略框架,通过最大熵逆强化学习得到类人奖励函数,并采用玻尔兹曼理性噪声模型建立行为概率与累积奖励的映射关系。通过预期轨迹空间的离散化处理,避免了连续高维空间积分中的维数灾难,并基于统计学规律和安全约束对预期轨迹空间进行压缩和修剪,提升了HBDS采样效率。HBDS在NGSIM数据集上进行训练和测试的结果表明,HBDS能做出符合驾驶人个性化认知特性和行为特征的行为决策。
宋东鉴,朱冰,赵健,韩嘉懿,刘彦辰. 基于驾驶行为生成机制的智能汽车类人行为决策[J]. 汽车工程, 2022, 44(12): 1797-1808.
Dongjian Song,Bing Zhu,Jian Zhao,Jiayi Han,Yanchen Liu. Human-Like Behavior Decision-Making of Intelligent Vehicles Based on Driving Behavior Generation Mechanism[J]. Automotive Engineering, 2022, 44(12): 1797-1808.
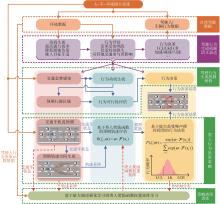
图1
基于驾驶行为生成机制的智能汽车类人行为决策抽象步骤"

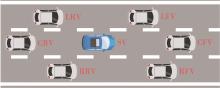
图2
影响EV行为决策的周围交通车"
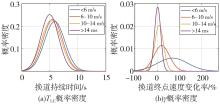
图3
不同初始速度下TLC与γ概率密度分布"
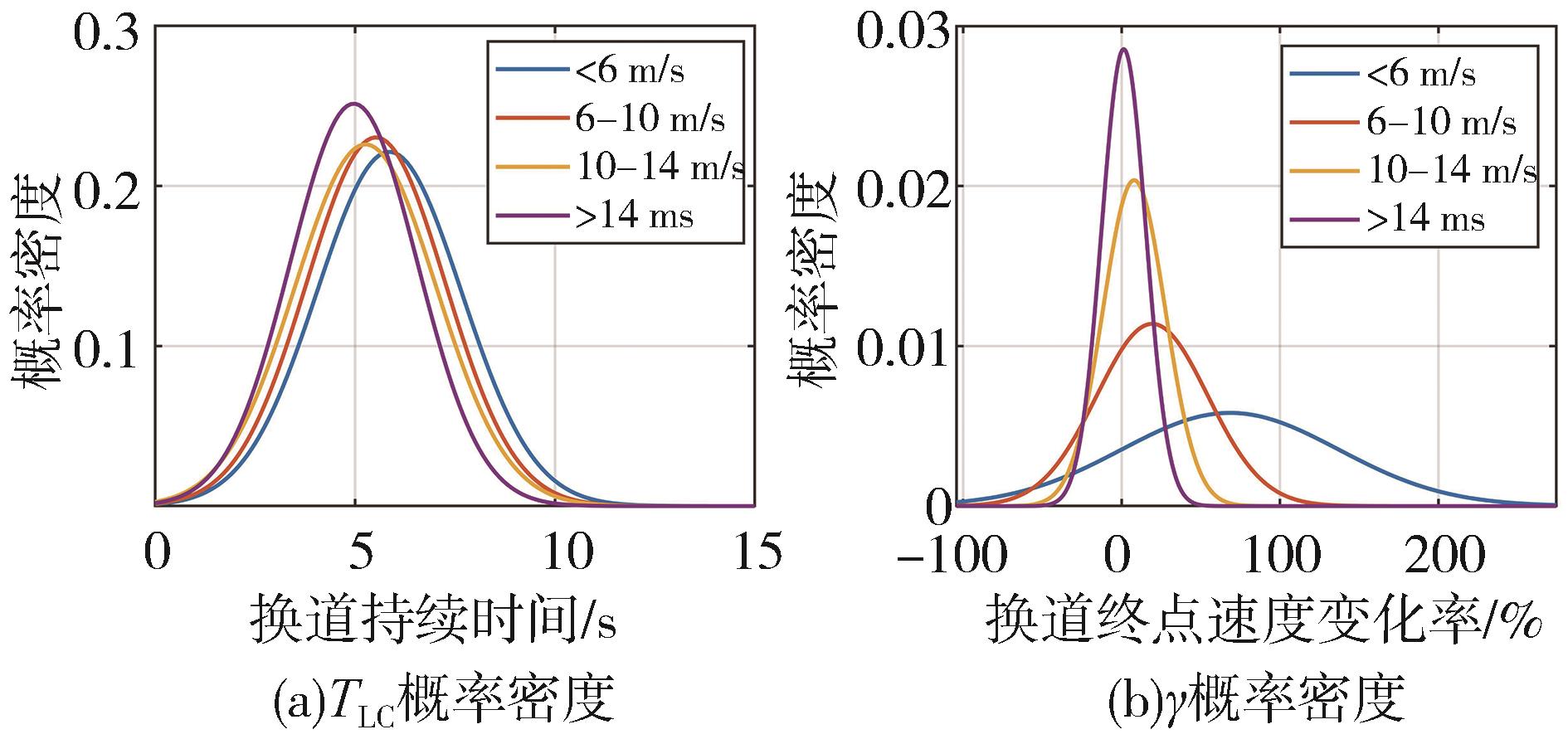
表1
正态分布参数表"
| 初始速度区间 | ||||
|---|---|---|---|---|
| <6 m/s | 5.858 | 1.802 | 68.516 | 68.522 |
| 6-10 m/s | 5.525 | 1.732 | 19.357 | 35.044 |
| 10-14 m/s | 5.266 | 1.765 | 7.927 | 15.590 |
| >14 m/s | 4.971 | 1.744 | 1.341 | 13.972 |
表2
TLC和γ取值区间与粒度"
| 变量 | 取值粒度 | 初始速度区间 | |||
|---|---|---|---|---|---|
| <6 m/s | 6-10 m/s | 10-14 m/s | >14 m/s | ||
| 1 | [ | ||||
| 10 | [70,200] | [50,90] | [ | [ | |
| 预期轨迹数量 | 168 | 90 | 42 | 36 | |
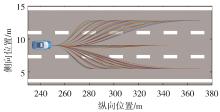
图4
压缩与剪枝后的预期轨迹空间"
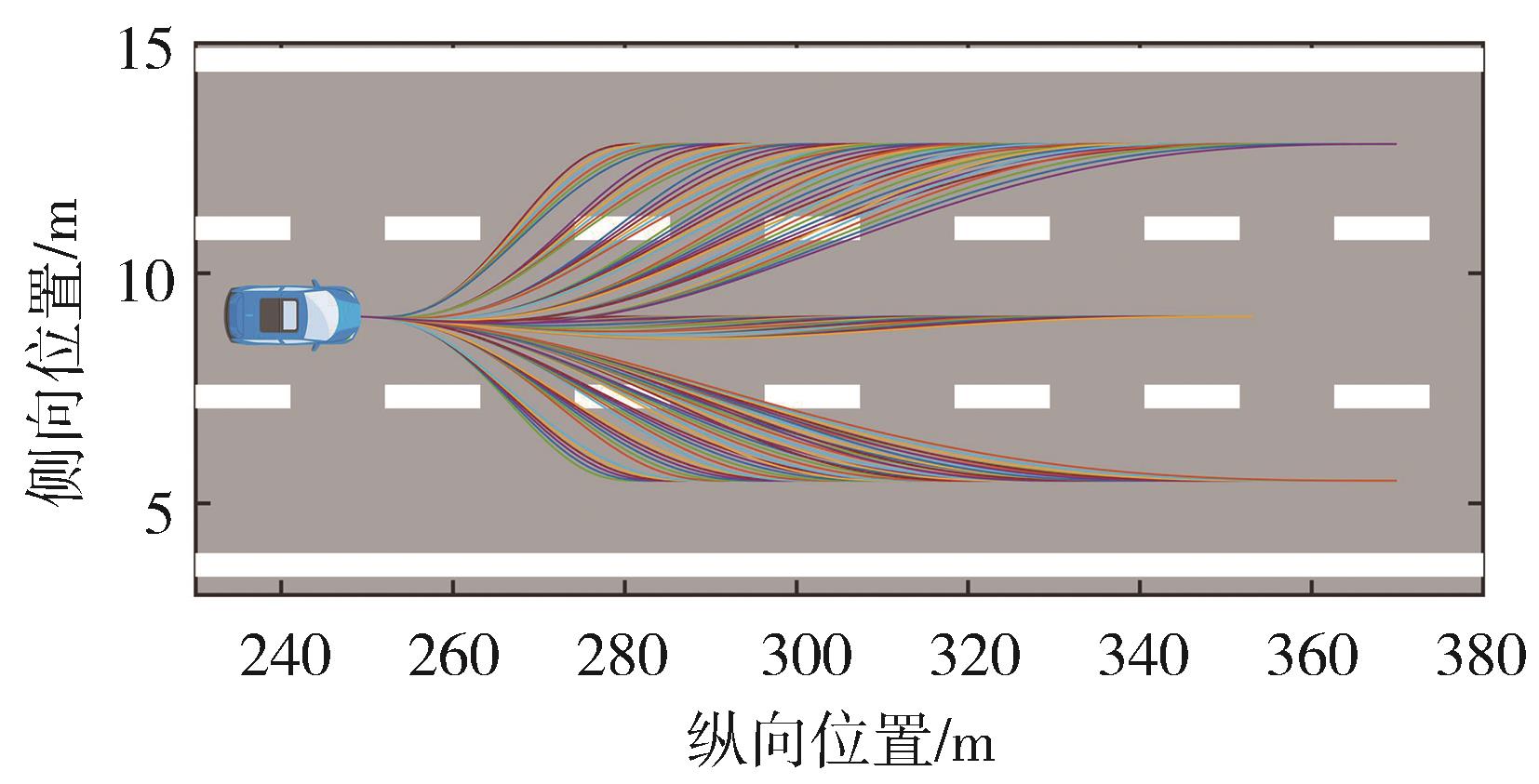
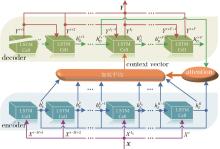
图5
交通车轨迹预测模型结构"
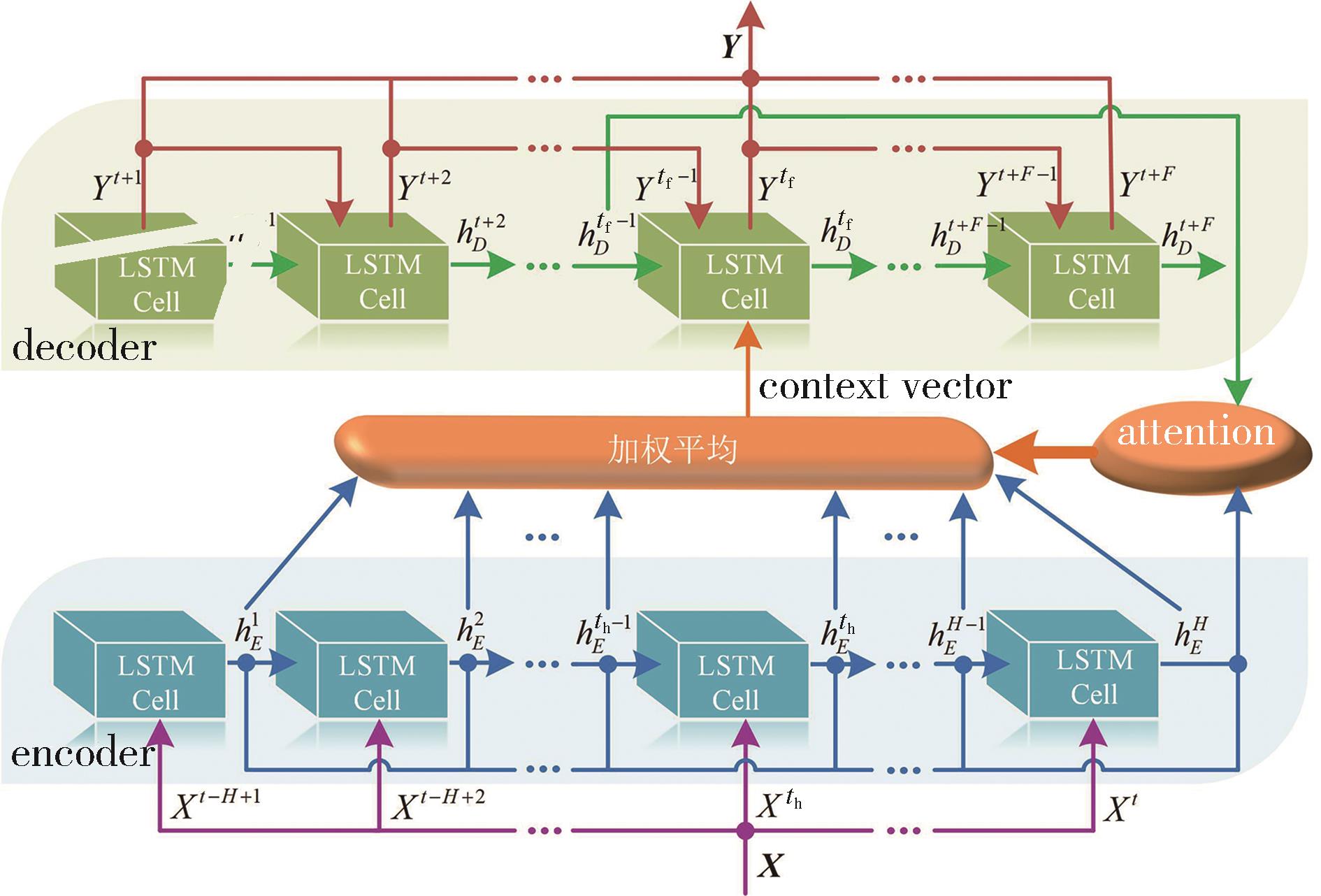
表3
不同预测时窗长度下的RMSE"
| 预测时窗长度/s | RMSE/m |
|---|---|
| 3 | 0.693 4 |
| 4 | 0.943 7 |
| 5 | 1.346 2 |
| 6 | 1.873 6 |
| 7 | 3.342 2 |
| 8 | 4.152 5 |
图6
不同运动状态的交通车风险场场强分布"
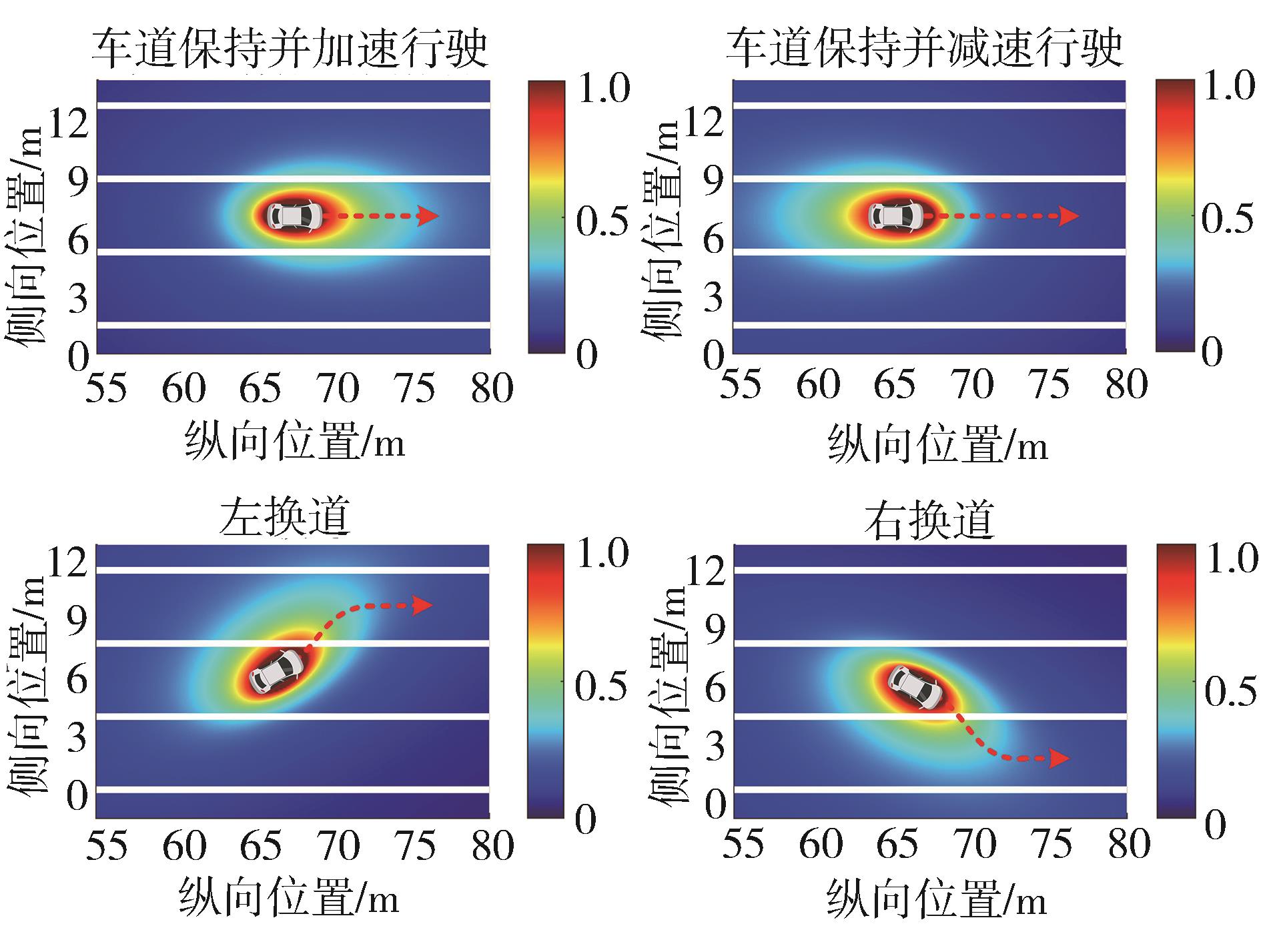
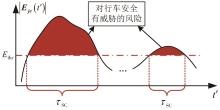
图7
fRiskξ的构造原理"
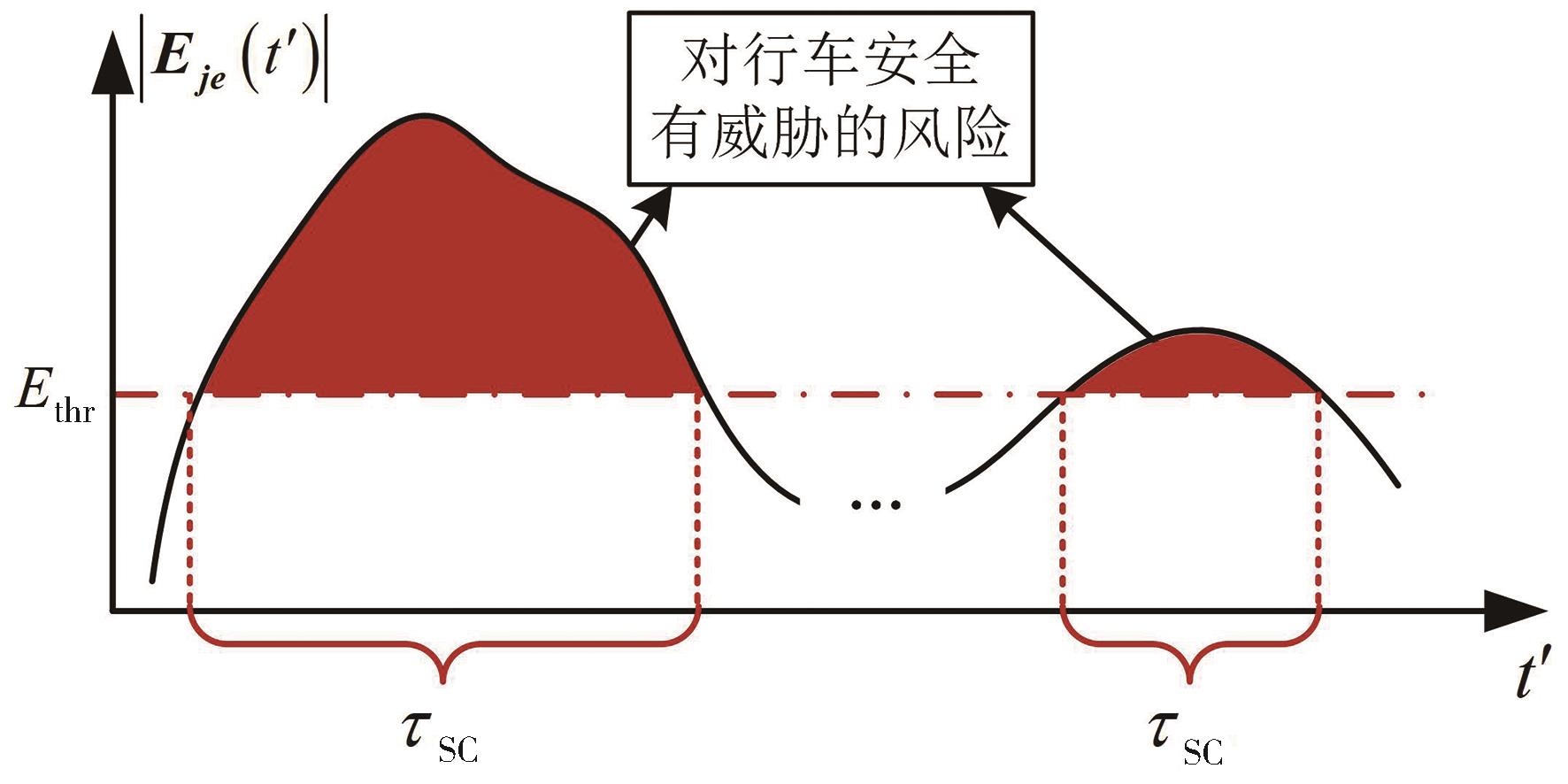
图8
驾驶人轨迹规则化处理"
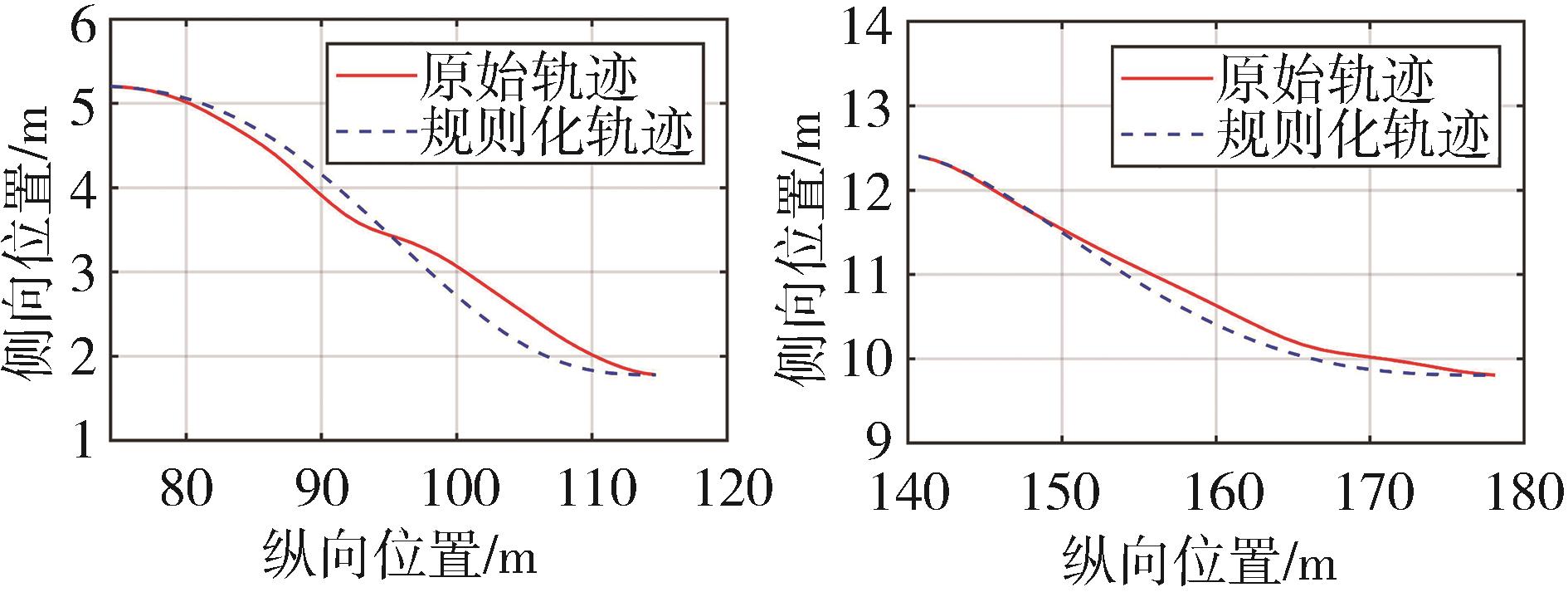
表4
有无各向异性行车风险场策略表现对比"
| 策略 | 行为决策准确率/% | 行为决策时间误差/s | ||
|---|---|---|---|---|
| 训练集 | 测试集 | 训练集 | 测试集 | |
| HBDS | 93.72 | 92.50 | 0.9 | 1.1 |
| HBDS-TTC | 88.46 | 86.92 | 1.3 | 2.1 |
表5
策略收敛回合数对比"
是否基于统计学 规律进行压缩 | 是否基于安全 约束进行剪枝 | 策略收敛所需 平均回合数 |
|---|---|---|
| 是 | 是 | 141 |
| 否 | 是 | 267 |
| 是 | 否 | 172 |
| 否 | 否 | 295 |
表6
有无交通车轨迹预测策略表现对比"
| 策略 | 行为决策准确率/% | 行为决策时间误差/s | ||
|---|---|---|---|---|
| 训练集 | 测试集 | 训练集 | 测试集 | |
| HBDS | 93.72 | 92.50 | 0.9 | 1.1 |
| HBDS-WP | 82.58 | 81.34 | 1.8 | 2.7 |
表7
HBDS与其他策略表现对比"
| 策略 | 行为决策准确率/% | 行为决策时间误差/s | ||
|---|---|---|---|---|
| 训练集 | 测试集 | 训练集 | 测试集 | |
| HBDS | 93.72 | 92.50 | 0.9 | 1.1 |
| FSM | 78.63 | 69.47 | 2.2 | 2.8 |
| DQN | 84.27 | 82.36 | 1.8 | 2.3 |
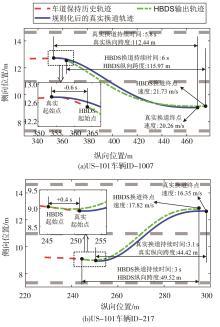
图9
HBDS概率最高轨迹与规则化处理的真实轨迹对比"
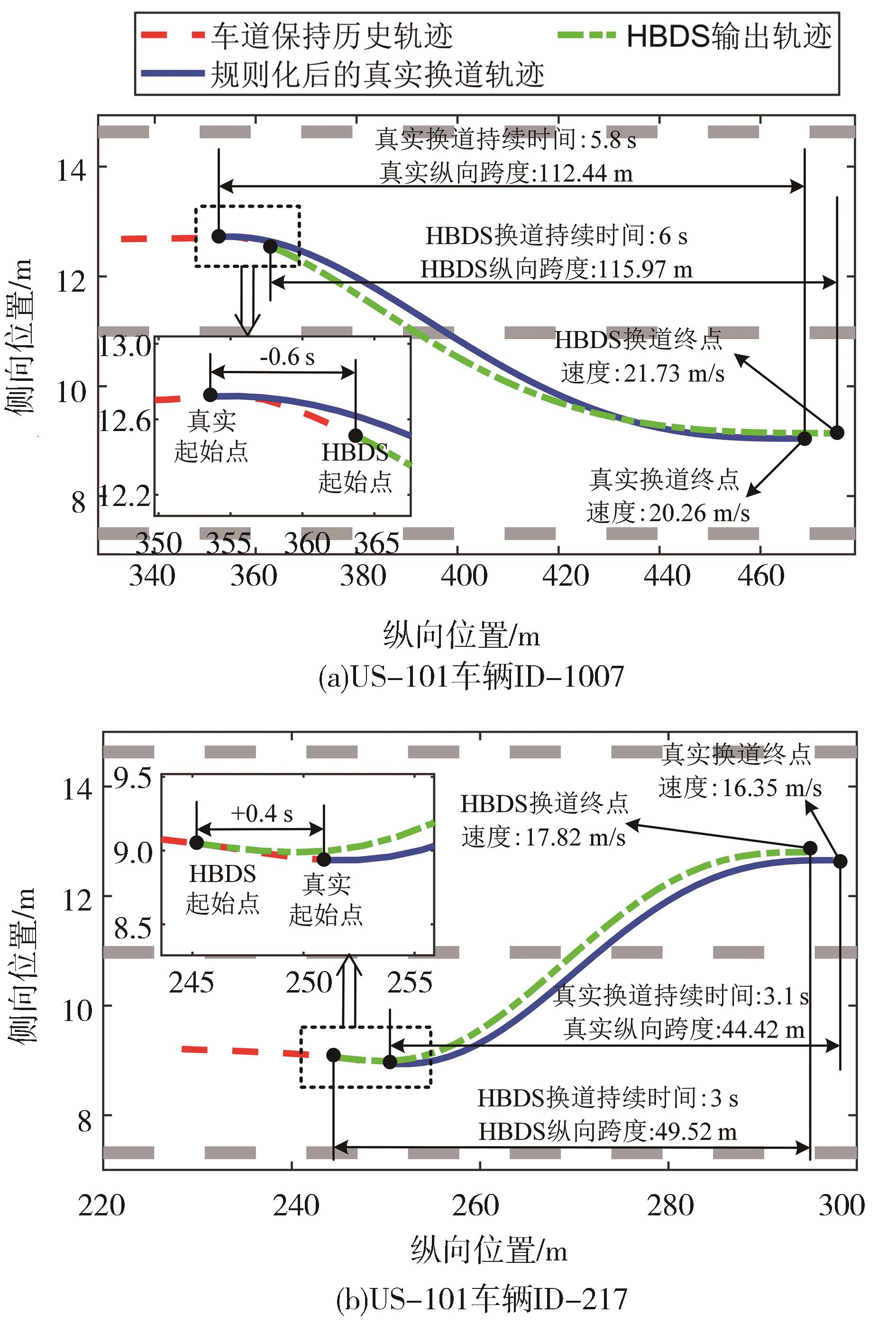
表8
概率最高轨迹与真实轨迹关键指标MAE"
| 换道轨迹持续时间/s | 轨迹终点速度/(m·s-1) | 轨迹纵向跨度/m |
|---|---|---|
| 0.34 | 1.72 | 4.87 |
| 1 | LI D Y, GAO H B. A hardware platform framework for an intelligent vehicle based on a driving brain[J]. Engineering, 2018, 4(4): 464-470. |
| 2 | ZHU B, JIANG Y D, ZHAO J, et al. Typical driving styles oriented personalized adaptive cruise control design based on human driving data[J]. Transportation Research Part C: Emerging Technologies, 2019, 100: 274-288. |
| 3 | YANG Z, FENG Y H, LIU H X. A cooperative driving framework for urban arterials in mixed traffic conditions[J]. Transportation Research Part C: Emerging Technologies, 2021, 124: 274-288. |
| 4 | 冀杰,黄岩军,李云伍,等. 基于有限状态机的车辆自动驾驶行为决策分析[J].汽车技术,2018(12):1-7. |
| JI J, HUANG Y J, LI Y W, et al. Decision making analysis of autonomous driving behaviors for intelligent vehicles based on finite state machine[J]. Automobile Technology,2018(12):1-7. | |
| 5 | YU H T, TSENG H E, LANGARI R. A human-like game theory-based controller for automatic lane changing[J]. Transportation Research Part C: Emerging Technologies, 2018, 88: 140-158. |
| 6 | 何艳侠,尹慧琳,夏鹏飞. 基于环境态势评估的智能车自主变道决策机制[J]. 汽车工程,2018,40(9):1048-1053. |
| HE Y X, YIN H L, XIA P F. Decision-making mechanism of autonomous lane-change for intelligent vehicles based on environment situation assessment[J]. Automotive Engineering, 2018, 40(9): 1048-1053. | |
| 7 | BALAL E, CHEU R L, SARKODIE-GYAN T. A binary decision model for discretionary lane changing move based on fuzzy inference system[J]. Transportation Research Part C: Emerging Technologies, 2016, 67: 47-61. |
| 8 | CHEN Y P, WANG J K, LI J, et al. LiDAR-video driving dataset: Learning driving policies effectively[C]. 2018 Conference on Computer Vision and Pattern Recognition (CVPR), IEEE/CVF, 2018: 5870-5878. |
| 9 | ZHU B, HAN J Y, ZHAO J, et al. Combined hierarchical learning framework for personalized automatic lane-changing[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(10): 6275-6285. |
| 10 | MIRCHEVSKA B,PEK C,WERLING M,et al. High⁃level decision making for safe and reasonable autonomous lane changing using reinforcement learning[C]. 2018 21st International Conference on Intelligent Transportation Systems(ITSC). IEEE,2018:2156-2162. |
| 11 | 高振海,闫相同,高 菲,等. 仿驾驶员DDPG汽车纵向自动驾驶决策方法[J]. 汽车工程,2021,43(12):1737-1744. |
| GAO Z H, YAN X T, GAO F, et al. A driver-like decision-making method for longitudinal autonomous driving[J]. Automotive Engineering, 2021,43(12):1737-1744. | |
| 12 | 宋晓琳,盛 鑫,曹昊天,等. 基于模仿学习和强化学习的智能车辆换道行为决策[J]. 汽车工程,2021,43(1):59-67. |
| SONG X L, SHENG X, CAO H T, et al. Lane⁃change behavior decision⁃making of intelligent vehicle based on imitation learning and reinforcement learning[J]. Automotive Engineering, 2021, 43(1): 59-67. | |
| 13 | XU D H, DING Z Z, HE X, et al. Learning from naturalistic driving data for human-like autonomous highway driving[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(12): 7341-7354. |
| 14 | SILVER D, BAGNELL J A, STENTZ A. Learning autonomous driving styles and maneuvers from expert demonstration[J]. Experimental Robotics, 2013, 88: 371–386. |
| 15 | NAUMANN M, SUN L T, ZHAN W, et al. Analyzing the suitability of cost functions for explaining and imitating human driving behavior based on inverse reinforcement learning[C]. International Conference on Robotics and Automation (ICRA), IEEE, 2020: 5481-5487. |
| 16 | FERNANDO T, DENMAN S, SRIDHARAN S, et al. Deep inverse reinforcement learning for behavior prediction in autonomous driving: accurate forecasts of vehicle motion[J]. IEEE Signal Processing Magazine, 2021, 38(1): 87-96. |
| 17 | WU Z, SUN L T, ZHAN W, et al. Efficient sampling-based maximum entropy inverse reinforcement learning with application to autonomous driving[J]. IEEE Robotics and Automation Letters, 2020, 5(4): 5355–5362. |
| 18 | HUANG Z Y, WU J D, LV C. Driving behavior modeling using naturalistic human driving data with inverse reinforcement learning[J]. IEEE Transactions on Intelligent Transportation Systems, Early Access, 2021, doi: 10.1109/TITS.2021.3088935. |
| 19 | SUN R Y, HU S, ZHAO H J, et al. Human-like highway trajectory modeling based on inverse reinforcement learning[C]. 2019 Intelligent Transportation Systems Conference (ITSC), IEEE, 2019: 1482-1489. |
| 20 | WULFMEIER M, RAO D, WANG D Z, et al. Large-scale cost function learning for path planning using deep inverse reinforcement learning[J]. The International Journal of Robotics Research, 2017, 36(10): 1073–1087. |
| 21 | ZIEBART B D, MAAS A, BAGNELL J A, et al. Maximum entropy inverse reinforcement learning[C]. 23rd AAAI Conference Artificial Intelligence, 2008, 8: 1433–1438. |
| 22 | TREIBER M, HENNECKE A, HELBING D. Congested traffic states in empirical observations and microscopic simulations[J]. Physical Review E, 2000, 62(2): 1805–1824. |
| 23 | JONES K, BENTLEY B E, WOOD J M, et al. Application of parallax for the measurement of visibility distances in the open-road environment[J]. International Archives of Photogrammetry and Remote Sensing, 1998, 33(5): 74-79. |
| 24 | Federal Highway Adminnistration. Ngsim-next generation simulation [EB/OL]. http://ops. fhwa. dot. Gov/reafficanalysistools/ngsim. |
| 25 | YAO W, ZENG Q Q, LIN Y P, et al. On-road vehicle trajectory collection and scene-based lane change analysis: Part II[J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(1): 206-220. |
| [1] | 付新科,蔡英凤,陈龙,王海,刘擎超. 不确定性环境下的自动驾驶汽车行为决策方法[J]. 汽车工程, 2024, 46(2): 211-221. |
| [2] | 郝建平,苏炎召,钟志华,黄晋. 面向智能汽车的SOA架构及服务调度机制研究[J]. 汽车工程, 2023, 45(9): 1563-1572. |
| [3] | 赵高士,陈龙,蔡英凤,廉玉波,王海,刘擎超,滕成龙. 融合复杂网络和记忆增强网络的轨迹预测技术[J]. 汽车工程, 2023, 45(9): 1608-1616. |
| [4] | 胡启慧,蔡英凤,王海,陈龙,董钊志,刘擎超. 基于层次图注意的异构多目标轨迹预测方法[J]. 汽车工程, 2023, 45(8): 1448-1456. |
| [5] | 金立生,纪丙东,郭柏苍. 基于多层时空融合网络的驾驶人注意力预测[J]. 汽车工程, 2023, 45(5): 759-767. |
| [6] | 高翔,陈龙,王歆叶,熊晓夏,李祎承,陈月霞. 基于轨迹预测的智能汽车行驶风险评估方法[J]. 汽车工程, 2023, 45(4): 588-597. |
| [7] | 胡杰,朱琪,陈锐鹏,张敏超,张志豪,刘昊岩. 引入必经点约束的智能汽车全局路径规划[J]. 汽车工程, 2023, 45(3): 350-360. |
| [8] | 张紫微,郑玲,李以农,乔旭强,郑浩,王戡. 考虑前车运动不确定性的多目标自适应巡航控制[J]. 汽车工程, 2023, 45(3): 361-371. |
| [9] | 刘正发,吴亚,刘佩根,顾荣琦,陈广. 基于特征和标签联合分布匹配的智能驾驶跨域自适应目标检测[J]. 汽车工程, 2023, 45(11): 2082-2091. |
| [10] | 赵树廉,来飞,李克强,陈涛,孟璋劼,唐逸超,吴思宇,田浩东. 基于数字孪生技术的智能汽车测试方法研究[J]. 汽车工程, 2023, 45(1): 42-51. |
| [11] | 邵文博,李骏,张玉新,王红. 智能汽车预期功能安全保障关键技术[J]. 汽车工程, 2022, 44(9): 1289-1304. |
| [12] | 汪梓豪,蔡英凤,王海,陈龙,熊晓夏. 基于单目视觉运动估计的周边多目标轨迹预测方法[J]. 汽车工程, 2022, 44(9): 1318-1326. |
| [13] | 梁旺,秦兆博,陈亮,边有钢,胡满江. 基于改进BP神经网络的智能车纵向控制方法[J]. 汽车工程, 2022, 44(8): 1162-1172. |
| [14] | 赵健,宋东鉴,朱冰,吴杭哲,韩嘉懿,刘宇翔. 数据机理混合驱动的交通车意图识别方法[J]. 汽车工程, 2022, 44(7): 997-1008. |
| [15] | 袁田,赵轩,刘瑞,余强,朱西产,王姝. 基于自然驾驶数据的城市交叉口纵向驾驶特征分析[J]. 汽车工程, 2022, 44(6): 821-830. |
|