Administrator by China Associction for Science and Technology
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Automotive Engineering ›› 2023, Vol. 45 ›› Issue (10): 1779-1790.doi: 10.19562/j.chinasae.qcgc.2023.10.001
Special Issue: 智能网联汽车技术专题-感知&HMI&测评2023年
Long Chen1,Chen Yang1,Yingfeng Cai1( ),Hai Wang2,Yicheng Li2
),Hai Wang2,Yicheng Li2
Received:2023-02-13
Revised:2023-03-14
Online:2023-10-25
Published:2023-10-23
Contact:
Yingfeng Cai
E-mail:caicaixiao0304@126.com
Long Chen,Chen Yang,Yingfeng Cai,Hai Wang,Yicheng Li. Pedestrian Crossing Intention Prediction Method Based on Multimodal Feature Fusion[J].Automotive Engineering, 2023, 45(10): 1779-1790.

"


"
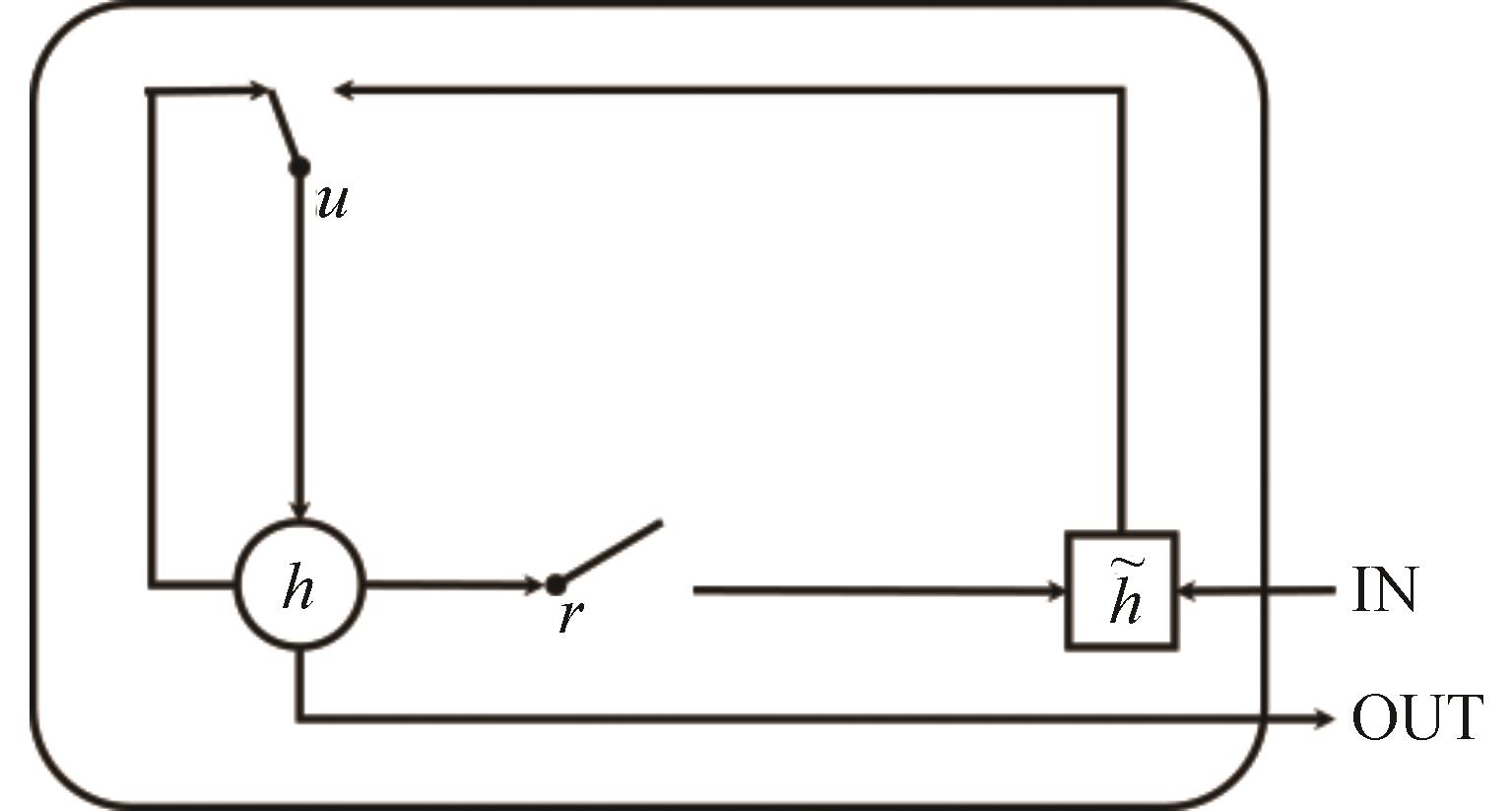
"
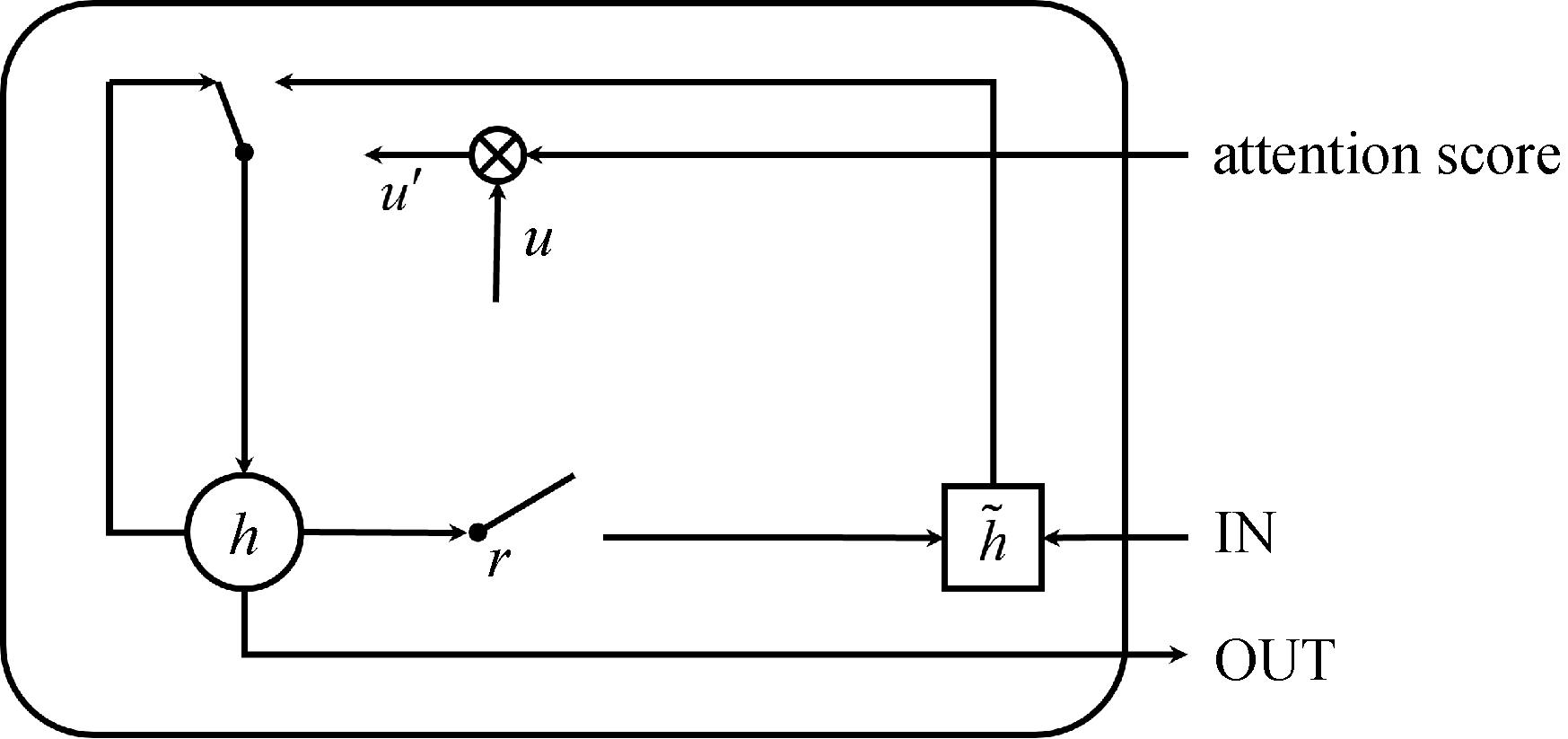

"
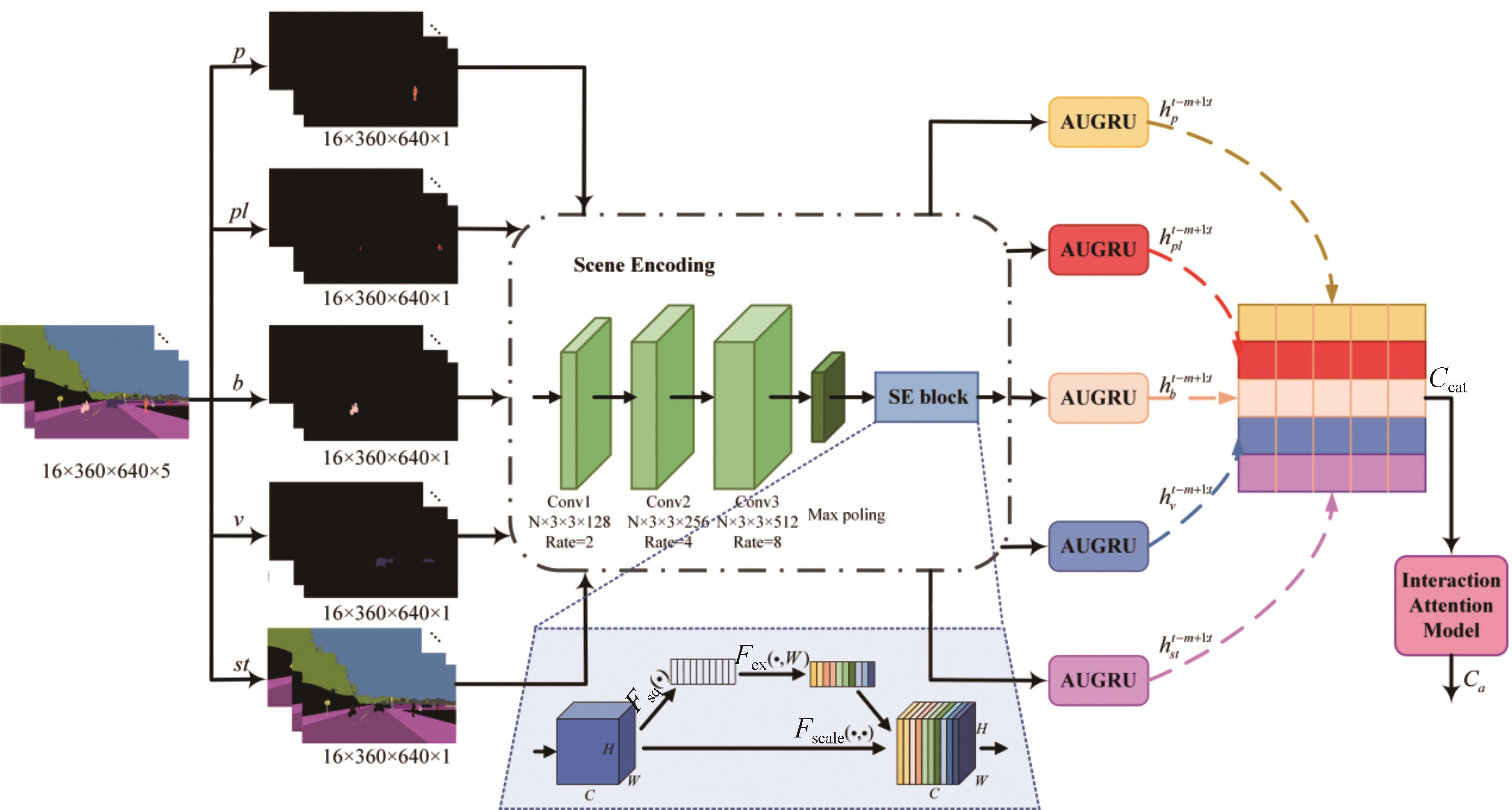

"
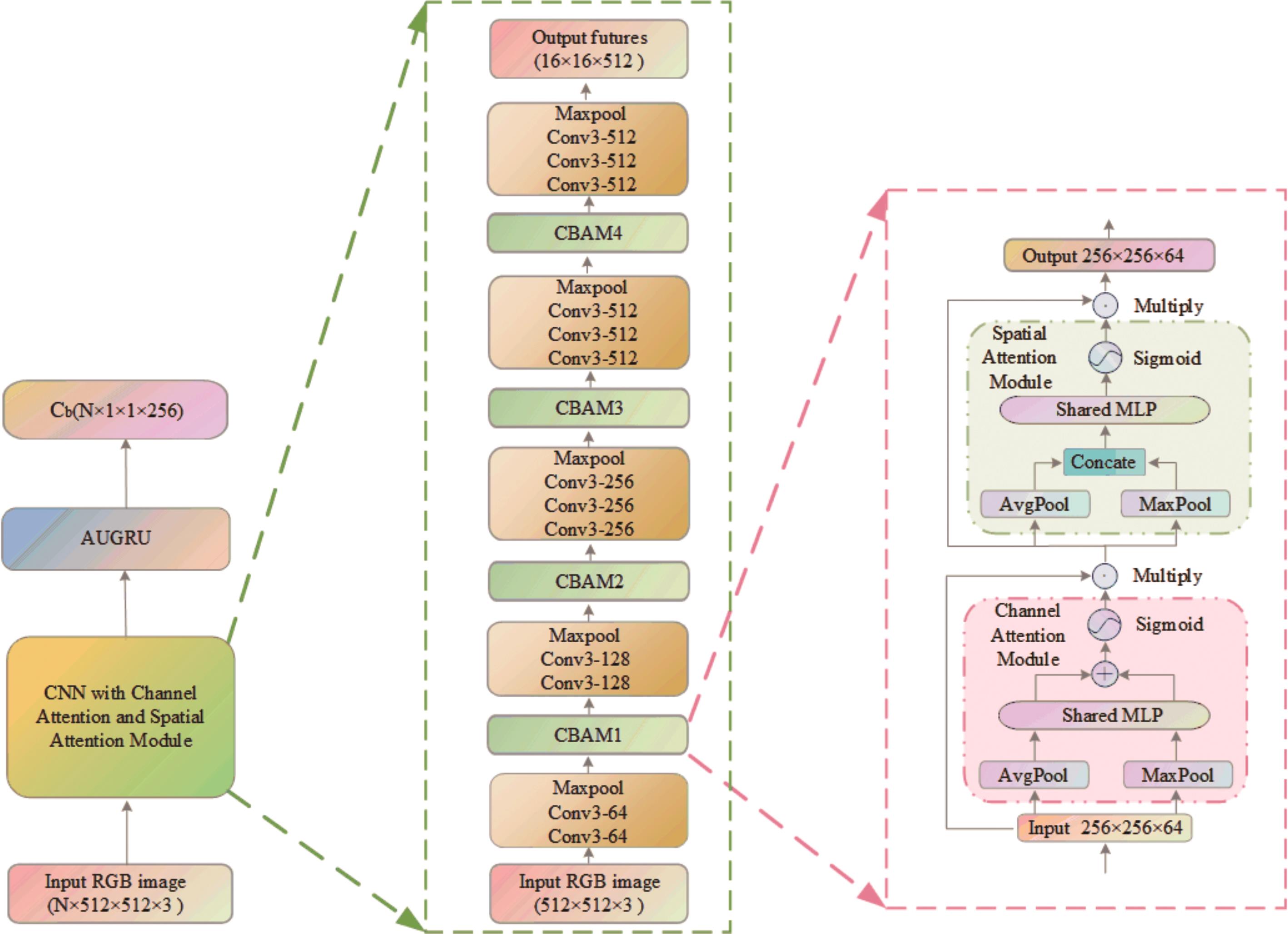

"

"
| Fusion strategy | Acc | AUC | F1 | Pre | Recall |
|---|---|---|---|---|---|
| early-fusion | 0.740 | 0.788 | 0.537 | 0.590 | 0.861 |
| late-fusion | 0.750 | 0.788 | 0.541 | 0.631 | 0.844 |
| hierarchical-fusion | 0.812 | 0.806 | 0.591 | 0.567 | 0.846 |
| hiybrid-fusion | 0.836 | 0.825 | 0.633 | 0.620 | 0.808 |
"
| Fusion strategy | Acc | AUC | F1 | Pre | Recall |
|---|---|---|---|---|---|
| early-fusion | 0.617 | 0.550 | 0.727 | 0.656 | 0.814 |
| late-fusion | 0.622 | 0.547 | 0.730 | 0.647 | 0.837 |
| hierarchical-fusion | 0.542 | 0.513 | 0.643 | 0.634 | 0.691 |
| hiybrid-fusion | 0.619 | 0.566 | 0.731 | 0.683 | 0.779 |
"
| levels | ||||
|---|---|---|---|---|
| 1 | A1=Input | B1=Input | C1=Input | D1=Input |
| 2 | A2=Not Input | B2= Not Input | C2= Not Input | D2= Not Input |
"
| Factors | A | B | C | D | Accuracy (JAADall) | Accuracy (JAADbeh) |
|---|---|---|---|---|---|---|
| Numbers | 1 | 2 | 3 | 4 | ||
| 1 | A1 | B1 | C1 | D1 | 0.836 | 0.619 |
| 2 | A1 | B1 | C1 | D2 | 0.824 | 0.622 |
| 3 | A1 | B2 | C2 | D1 | 0.786 | 0.609 |
| 4 | A1 | B2 | C2 | D2 | 0.774 | 0.597 |
| 5 | A2 | B1 | C2 | D1 | 0.802 | 0.605 |
| 6 | A2 | B1 | C2 | D2 | 0.787 | 0.584 |
| 7 | A2 | B2 | C1 | D1 | 0.766 | 0.563 |
| 8 | A2 | B2 | C1 | D2 | 0.750 | 0.557 |
| Ⅰ1 | 0.805 | 0.812 | 0.794 | 0.797 | T1=0.791 | T2=0.595 |
| Ⅱ1 | 0.776 | 0.769 | 0.787 | 0.784 | ||
| Range | 0.029 | 0.043 | 0.007 | 0.013 | ||
| Order | B、A、D、C | |||||
| Ⅰ2 | 0.612 | 0.608 | 0.590 | 0.599 | ||
| Ⅱ2 | 0.577 | 0.582 | 0.599 | 0.590 | ||
| Range | 0.035 | 0.026 | 0.009 | 0.009 | ||
| Order | A、B、C、D | |||||
"
| Models | Visual Encoder | Inputs | Main Fusion Approach | Accuracy | AUC | F1Score | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| SF-GRU | VGG+GRU | Box+BCD | hierarchical fusion | 0.76 | 0.77 | 0.53 | 0.40 | 0.79 |
| PCPA | 3DCNN | Box+BCD | later-fusion | 0.76 | 0.79 | 0.55 | 0.41 | 0.83 |
| Ours1 | VGG+GRU | Box+BCD | hierarchical-fusion | 0.80 | 0.81 | 0.59 | 0.49 | 0.81 |
| Ours2 | VGG+AUGRU | Box+BCD | hierarchical-fusion | 0.81 | 0.82 | 0.61 | 0.50 | 0.80 |
| Ours3 | VGG+AUGRU | Box+ABCD | hiybrid-fusion | 0.84 | 0.83 | 0.63 | 0.52 | 0.81 |
"
| Models | Visual Encoder | Inputs | Main Fusion Approach | Accuracy | AUC | F1Score | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| SF-GRU | VGG+GRU | Box+BCD | hierarchical-fusion | 0.58 | 0.56 | 0.65 | 0.68 | 0.62 |
| PCPA | 3DCNN | Box+BCD | later-fusion | 0.53 | 0.53 | 0.59 | 0.66 | 0.53 |
| Ours1 | VGG+GRU | Box+BCD | hierarchical-fusion | 0.60 | 0.56 | 0.71 | 0.67 | 0.81 |
| Ours4 | VGG+AUGRU | Box+BCD | hierarchical-fusion | 0.61 | 0.57 | 0.73 | 0.67 | 0.76 |
| Ours5 | VGG+AUGRU | Box+ABC | hiybrid-fusion | 0.62 | 0.57 | 0.73 | 0.69 | 0.78 |

"

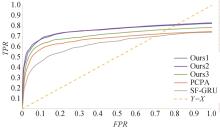
"
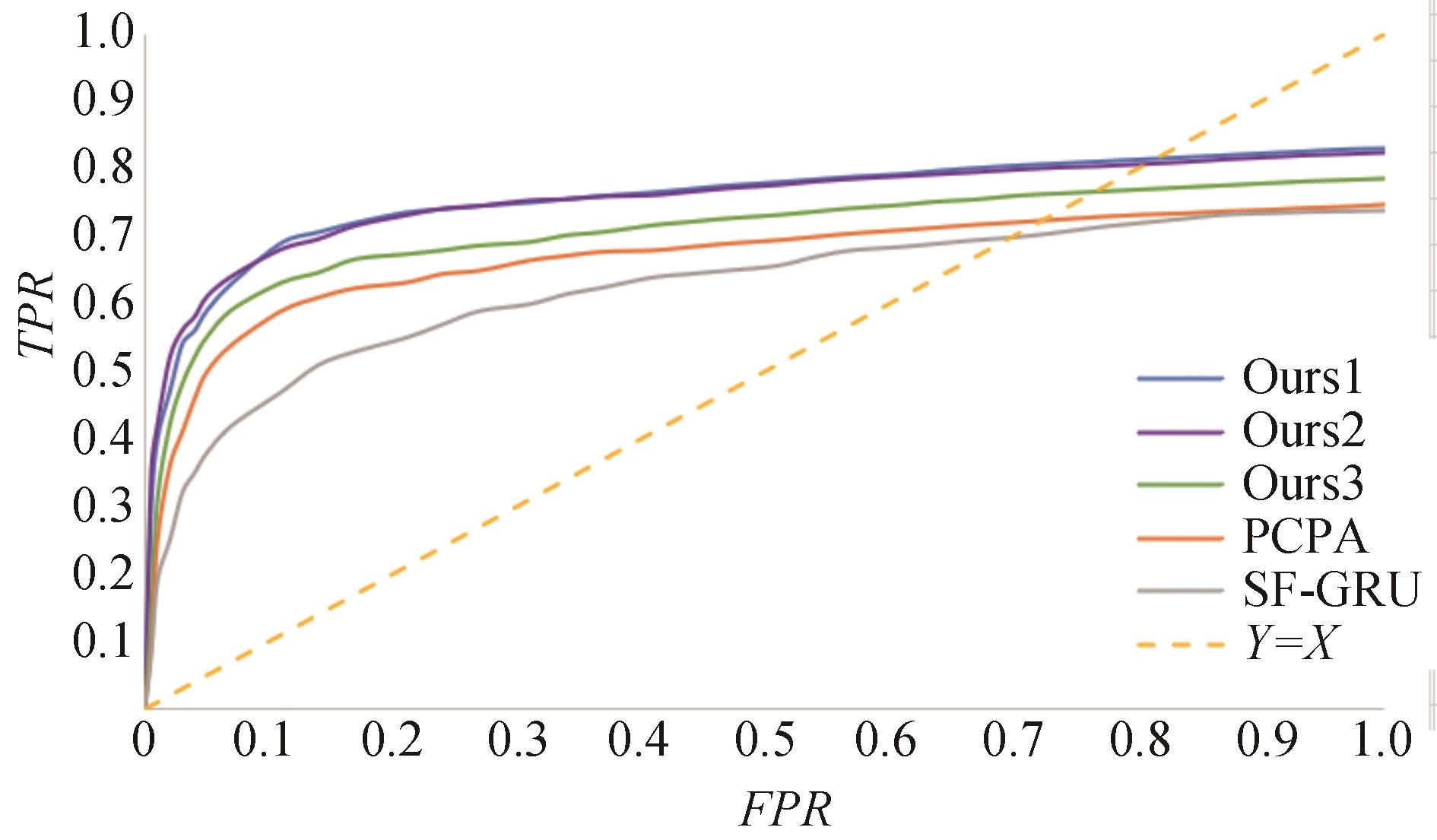

"

| 1 | 张亚丽.世界卫生组织发布《2018年全球道路安全现状报告》[J].中华灾害救援医学,2019, 7 (2): 100. |
| ZHANG Y. World health organization released “global road safety status report 2018” [J]. China Disaster Relief Medicine, 2019, 7(2): 100. | |
| 2 | 王辉. 行人过街时人-车交互特性分析与过街行为预测建模[D]. 西安: 长安大学,2021. |
| WANG H. Analysis of human-vehicle interaction characteristics and predictive modeling of crossing behavior when pedestrians cross the street [D]. Xi'an: Chang'an University, 2021. | |
| 3 | ALAHI A, GOEL K, RAMANATHAN V, et al. Social LSTM: human trajectory prediction in crowded spaces[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016: 961-971. |
| 4 | GUPTA A, JOHNSON J, FEI-FEI L, et al. Social GAN: socially acceptable trajectories with generative adversarial networks[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018: 2255-2264. |
| 5 | KOSARAJU V, SADEGHIAN A, MARTÍN-MARTÍN R, et al.Social-BiGAT: multimodal trajectory forecasting using bicycle-gan and graph attention networks[J]. Advances in Neural Information Processing Systems,2019, 32. |
| 6 | MOHAMED A, QIAN K, ELHOSEINY M, et al. Social-STGCNN: a social spatio-temporal graph convolutional neural network for human trajectory prediction[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2020: 14424-14432. |
| 7 | YAGI T, MANGALAM K, YONETANI R, et al. Future person localization in first-person videos[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018: 7593-7602. |
| 8 | QUINTERO R, PARRA I, LORENZO J, et al. Pedestrian intention recognition by means of a hidden markov model and body language[C]. 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC),2017: 1-7. |
| 9 | YU F, CHEN H, WANG X, et al. Bdd100k: a diverse driving dataset for heterogeneous multitask learning[C].Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2020: 2636-2645. |
| 10 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation,1997, 9 (8): 1735-1780. |
| 11 | FANG Z, LÓPEZ A M. Intention recognition of pedestrians and cyclists by 2D pose estimation[J].IEEE Transactions on Intelligent Transportation Systems,2019, 21 (11): 4773-4783. |
| 12 | ZHANG S, LIU X, XIAO J. On geometric features for skeleton-based action recognition using multilayer lstm networks[C].2017 IEEE Winter Conference on Applications of Computer Vision (WACV),2017: 148-157. |
| 13 | CADENA P R G, YANG M, QIAN Y, et al. Pedestrian graph: pedestrian crossing prediction based on 2D pose estimation and graph convolutional networks[C].2019 IEEE Intelligent Transportation Systems Conference (ITSC),2019: 2000-2005. |
| 14 | HUYNH M, ALAGHBAND G. GPRAR: graph convolutional network based pose reconstruction and action recognition for human trajectory prediction[J].arXiv preprint arXiv:,2021. |
| 15 | ALIAKBARIAN M S, SALEH F S, SALZMANN M, et al. VIENA: a driving anticipation dataset[C].Computer Vision-ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part I,2019: 449-466. |
| 16 | RASOULI A, KOTSERUBA I, TSOTSOS J K. Are they going to cross? a benchmark dataset and baseline for pedestrian crosswalk behavior[C].Proceedings of the IEEE International Conference on Computer Vision Workshops,2017: 206-213. |
| 17 | RASOULI A, KOTSERUBA I, KUNIC T, et al. Pie: a large-scale dataset and models for pedestrian intention estimation and trajectory prediction[C].Proceedings of the IEEE/CVF International Conference on Computer Vision,2019: 6262-6271. |
| 18 | PICCOLI F, BALAKRISHNAN R, PEREZ M J, et al. Fussi-Net: fusion of spatio-temporal skeletons for intention prediction network[C].2020 54th Asilomar Conference on Signals, Systems, and Computers,2020: 68-72. |
| 19 | RASOULI A, KOTSERUBA I, TSOTSOS J K. Pedestrian action anticipation using contextual feature fusion in stacked rnns[J].arXiv preprint arXiv:,2020. |
| 20 | KOTSERUBA I, RASOULI A, TSOTSOS J K. Benchmark for evaluating pedestrian action prediction[C].Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision,2021: 1258-1268. |
| 21 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C].Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13,2014: 740-755. |
| 22 | SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C].Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019: 5693-5703. |
| 23 | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016: 3213-3223. |
| 24 | CHEN L C, PAPANDREOU G, SCHROFF F, et al.Rethinking atrous convolution for semantic image segmentation[J].arXiv preprint arXiv:,2017. |
| 25 | ZHOU G, MOU N, FAN Y, et al. Deep interest evolution network for click-through rate prediction[C].Proceedings of the AAAI Conference on Artificial Intelligence, 2019: 5941-5948. |
| 26 | CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[J].arXiv preprint arXiv:,2014. |
| 27 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132-7141. |
| 28 | YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[J].arXiv preprint arXiv:,2015. |
| 29 | LUONG M T, PHAM H, MANNING C D. Effective approaches to attention-based neural machine translation[J].arXiv preprint arXiv:,2015. |
| 30 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J].arXiv preprint arXiv:,2014. |
| 31 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C].Proceedings of the European Conference on Computer Vision (ECCV),2018: 3-19. |
| 32 | RASOULI A, KOTSERUBA I, TSOTSOS J K. It's not all about size: on the role of data properties in pedestrian detection[C].Proceedings of the European Conference on Computer Vision (ECCV) Workshops,2018. |
| [1] | Xinke Fu,Yingfeng Cai,Long Chen,Hai Wang,Qingchao Liu. Decision-Making for Autonomous Driving in Uncertain Environment [J]. Automotive Engineering, 2024, 46(2): 211-221. |
| [2] | Yongtao Li,Chenxu Sun,Weiguang Zheng,Enyong Xu,Yufang Li,Shanchao Wang. Collision Warning Based on Fusion of Millimeter Wave Radar and Vision [J]. Automotive Engineering, 2023, 45(9): 1666-1676. |
| [3] | Cheng Lin, Bowen Wang, Lü Peiyuan, Xinle Gong, Xiao Yu. Research on Motion Planning and Cooperative Control for Autonomous Vehicles with Lane Change Gaming Maneuvers Under the Curved Road [J]. Automotive Engineering, 2023, 45(7): 1099-1111. |
| [4] | Xia Zhao,Zhao Li,Rui Fu,Zhenzhen Ge,Chang Wang. Real-Time Detection of Distracted Driving Behavior Based on Deep Convolution-Tokens Dimensionality Reduction Optimized Visual Transformer Model [J]. Automotive Engineering, 2023, 45(6): 974-988. |
| [5] | Yanyan Chen,Hai Wang,Yingfeng Cai,Long Chen,Yicheng Li. Efficient Automatic Driving Instance Segmentation Method Based on Detection [J]. Automotive Engineering, 2023, 45(4): 541-550. |
| [6] | Lü Ying,Xu Qi,Qiuzheng Liu,Xinyu Wang,Guoying Chen. Path Tracking Control Method with Steering Lag for Autonomous Vehicles [J]. Automotive Engineering, 2023, 45(12): 2234-2241. |
| [7] | Linhui Li,Xinliang Zhang,Yifan Fu,Jing Lian,Jiaxu Ma. Research on Visible Light and Infrared Post-Fusion Detection Based on TC-YOLOv7 Algorithm [J]. Automotive Engineering, 2023, 45(12): 2280-2290. |
| [8] | Zhengfa Liu,Ya Wu,Peigen Liu,Rongqi Gu,Guang Chen. Cross-Domain Object Detection for Intelligent Driving Based on Joint Distribution Matching of Features and Labels [J]. Automotive Engineering, 2023, 45(11): 2082-2091. |
| [9] | Xiaojun Zhang,Jingzhe Xi,Yanlei Shi,Anlu Yuan. Lightweight YOLOv7-R Algorithm for Road-Side View Target Detection [J]. Automotive Engineering, 2023, 45(10): 1833-1844. |
| [10] | Fengchong Lan,Yingjie Liu,Jiqing Chen,Zhaolin Liu. Study on Motion Planning of Autonomous Vehicles in Cut-in Scenes Based on Dynamic Game Algorithm [J]. Automotive Engineering, 2023, 45(1): 9-19. |
| [11] | Yingfeng Cai,Ziheng Lu,Yicheng Li,Long Chen,Hai Wang. Tightly Coupled SLAM System Based on Multi-Sensor Fusion [J]. Automotive Engineering, 2022, 44(3): 350-361. |
| [12] | Jingwei Zhang,Tiejun Liu,Rengang Li,Dan Liu,Jinglin Zhan,Hongwei Kan. A Temporal Calibration Method for Multi-Sensor Fusion of Autonomous Vehicles [J]. Automotive Engineering, 2022, 44(2): 215-224. |
| [13] | Chaoyang Jiang,Tianran Lan,Xiaoni Zheng,Jiulong Gao,Xuetong Ye. Distributed Multi-vehicle Collaborative Visual SLAM System [J]. Automotive Engineering, 2022, 44(12): 1809-1817. |
| [14] | Yuande Jiang,Bing Zhu,Xiangmo Zhao,Jian Zhao,Bingbing Zheng. Modeling of Traffic Vehicle Interaction for Autonomous Vehicle Testing [J]. Automotive Engineering, 2022, 44(12): 1825-1833. |
| [15] | Dafang Wang,Hai Shang,Jiang Cao,Tao Wang,Xiangteng Xia,Yulin Han. Semantic Segmentation Method of Point Cloud in Automatic Driving Scene Based on Self-attention Mechanism [J]. Automotive Engineering, 2022, 44(11): 1656-1664. |