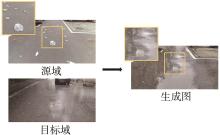
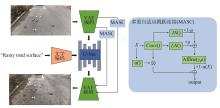
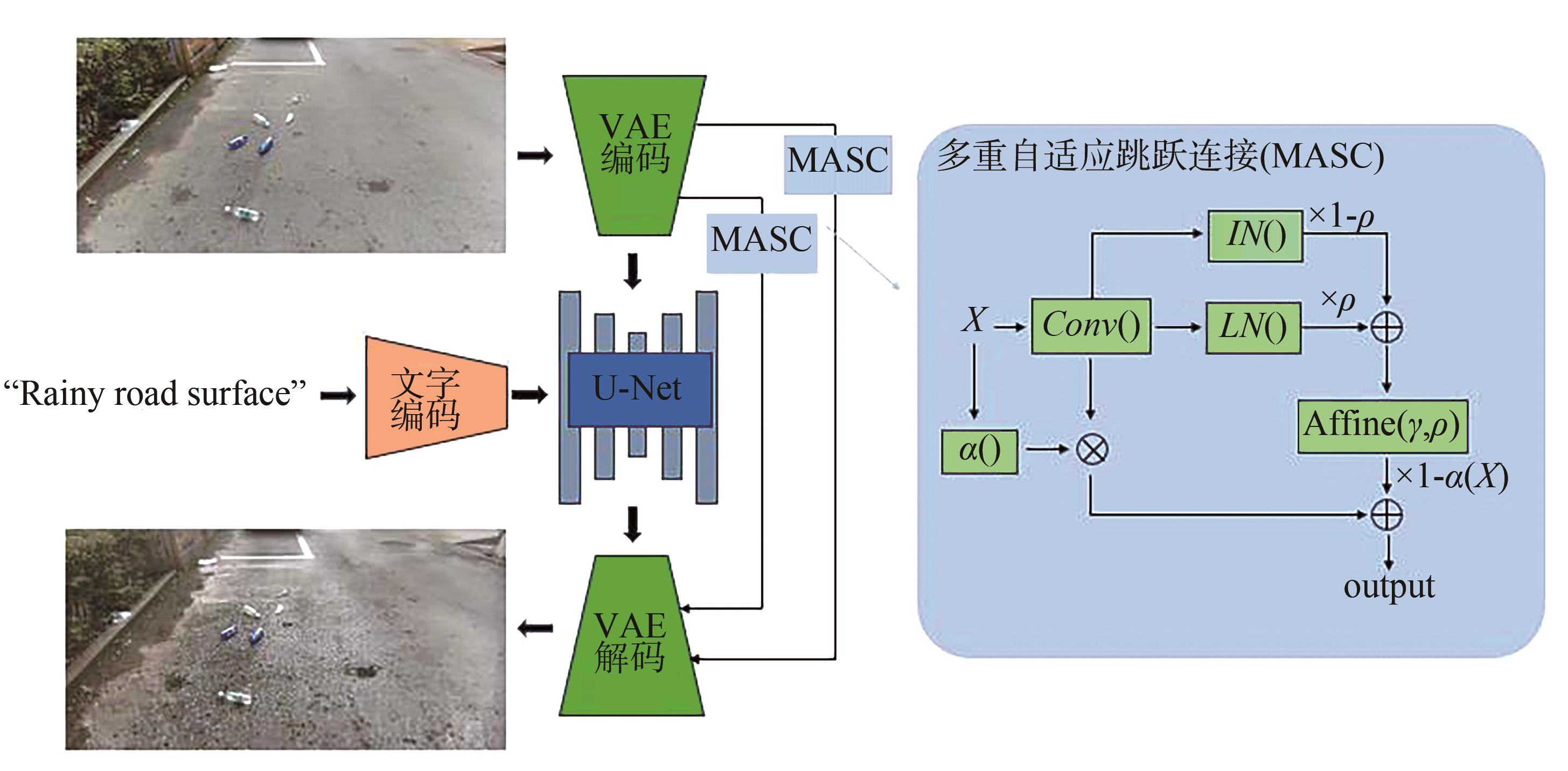
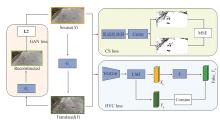
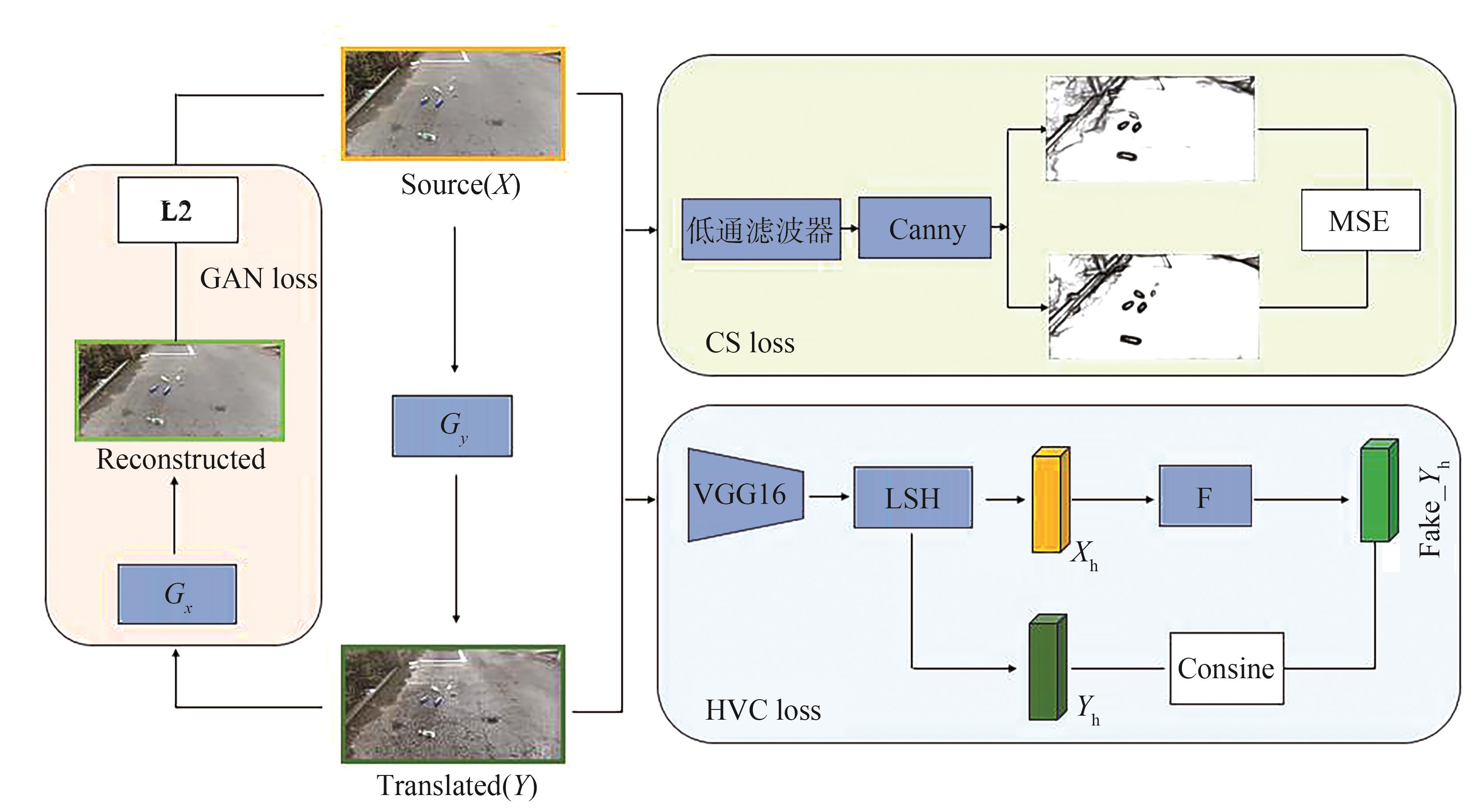
| [1] |
LIN C T, HUANG S W, WU Y Y, et al. GAN-based day-to-night image style transfer for nighttime vehicle detection [J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(2): 951-963.
|
| [2] |
CHEN X, LI H, LI M Q, et al. Learning a sparse transformer network for effective image deraining [C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, CANADA, F Jun 17-24, 2023.
|
| [3] |
CHEN Y C, LIN Y Y, YANG M H, et al. CrDoCo: pixel-level domain transfer with cross-domain consistency [C]. Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, F Jun 16-20, 2019.
|
| [4] |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]. Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, CANADA, F Dec 08-13, 2014.
|
| [5] |
NICHOL A, DHARIWAL P. Improved denoising diffusion probabilistic models [C]. Proceedings of the International Conference on Machine Learning (ICML), Electr Network, F Jul 18-24, 2021.
|
| [6] |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]. Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, ITALY, F Oct 22-29, 2017.
|
| [7] |
LIU M Y, BREUEL T, KAUTZ J. Unsupervised image-to-image translation networks [C]. Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, F Dec 04-09, 2017.
|
| [8] |
HUANG X, LIU M Y, BELONGIE S, et al. Multimodal unsupervised image-to-image translation [C]. Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, GERMANY, F Sep 08-14, 2018.
|
| [9] |
JIA Z W, YUAN B D, WANG K K, et al. Semantically robust unpaired image translation for data with unmatched semantics statistics [C]. Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Electr Network, F Oct 11-17, 2021.
|
| [10] |
PARK T, EFROS A A, ZHANG R, et al. Contrastive learning for unpaired image-to-image translation [C]. Proceedings of the Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16, F, 2020. Springer.
|
| [11] |
LEE H Y, LI Y H, LEE T H, et al. Progressively unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation [J]. Sensors, 2023, 23(15).
|
| [12] |
JIANG Y F, CHANG S Y, WANG Z Y. TransGAN: two pure transformers can make one strong GAN, and that can scale up [C]. Proceedings of the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), Electr Network, F Dec 06-14, 2021.
|
| [13] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]. Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, F Dec 04-09, 2017.
|
| [14] |
THEISS J, LEVERETT J, KIM D, et al. Unpaired image translation via vector symbolic architectures [C]. Proceedings of the 17th European Conference on Computer Vision (ECCV), Tel Aviv, ISRAEL, F Oct 23-27, 2022.
|
| [15] |
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851.
|
| [16] |
SASAKI H, WILLCOCKS C G, BRECKON T P. UNIT-DDPM: UNpaired image translation with denoising diffusion probabilistic models [J]. arXiv, 2021.
|
| [17] |
ZHAO M, BAO F, LI C X, et al. EGSDE: unpaired image-to-image translation via energy-guided stochastic differential equations [C]. Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS), Electr Network, F Nov 28-Dec 09, 2022.
|
| [18] |
WU C H, DE LA TORRE F, IEEE. A latent space of stochastic diffusion models for zero-shot image editing and guidance [C]; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, FRANCE, F Oct 02-06, 2023.
|
| [19] |
PARMAR G, PARK T, NARASIMHAN S, et al. One-step image translation with text-to-image models [J]. arXiv preprint arXiv:, 2024.
|
| [20] |
DHARIWAL P, NICHOL A. Diffusion models beat GANs on image synthesis [C]. Proceedings of the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), Electr Network, F Dec 06-14, 2021.
|
| [21] |
KINGMA D P, WELLING M. Auto-encoding variational bayes [Z]. Banff, Canada. 2013.
|
| [22] |
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, F Jun 18-24, 2022.
|
| [23] |
HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [J]. ICLR, 2022, 1(2): 3.
|
| [24] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]. Proceedings of the International Conference on Machine Learning (ICML), Electr Network, F Jul 18-24, 2021.
|
| [25] |
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding [C]. Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, F Jun 27-30, 2016.
|
| [26] |
RICHTER S R, VINEET V, ROTH S, et al. Playing for data: ground truth from computer games [C]. Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, NETHERLANDS, F Oct 08-16, 2016.
|
| [27] |
HENSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local nash equilibrium [C]. Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, F Dec 04-09, 2017.
|
| [28] |
SUTHERLAND J, ARBEL M, GRETTON A. Demystifying MMD GANS [C]. Proceedings of the International Conference for Learning Representations, F, 2018.
|
| [29] |
CHERIAN A, SULLIVAN A. Sem-GAN: semantically-consistent image-to-image translation [C]. Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (wacv), F, 2019, IEEE.
|
| [30] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [J]. arXiv preprint arXiv:, 2017.
|
 ),廖家才2,崔昊巍3,张月3
),廖家才2,崔昊巍3,张月3