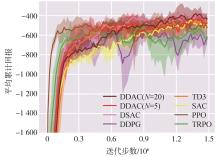
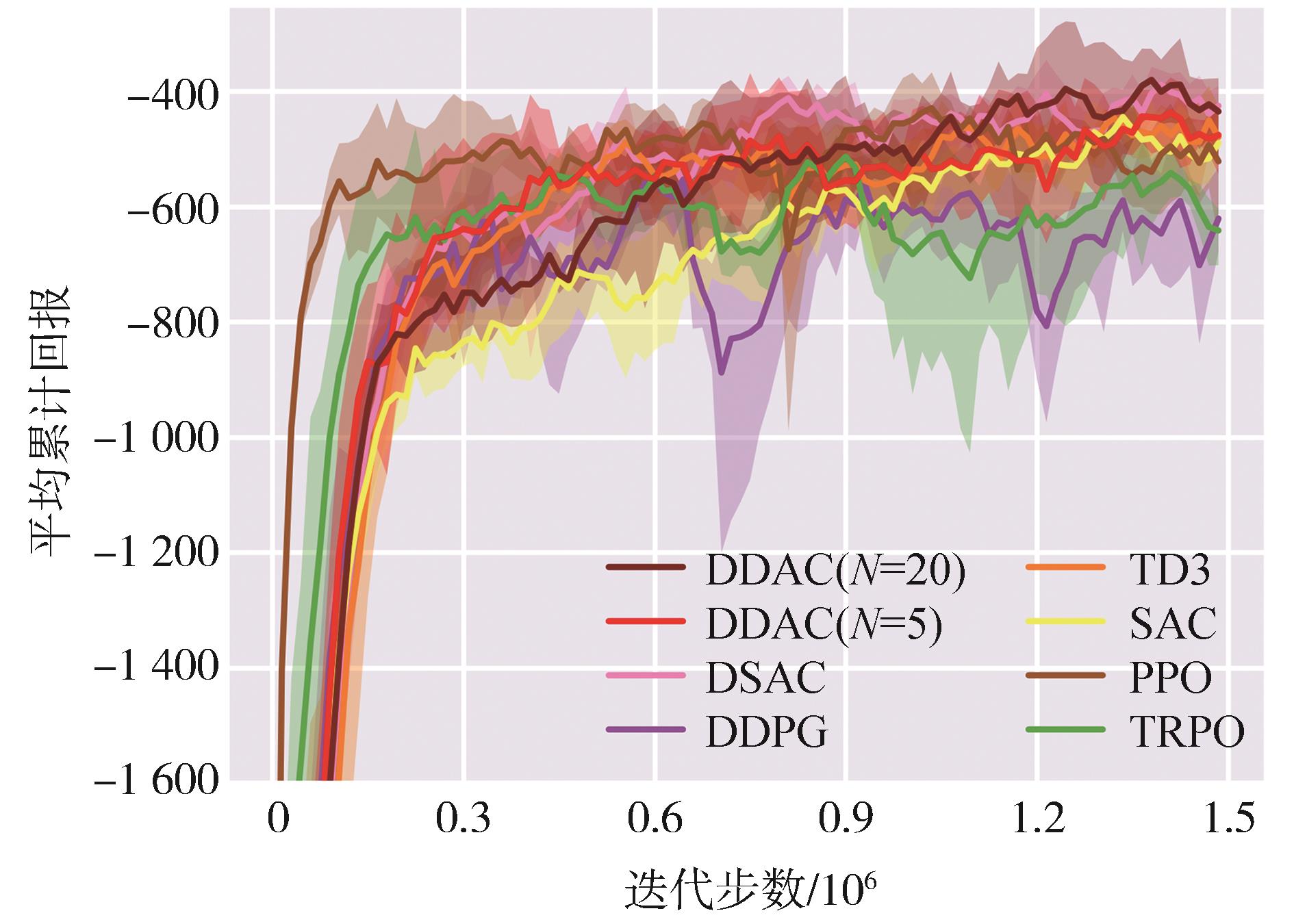
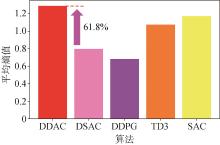
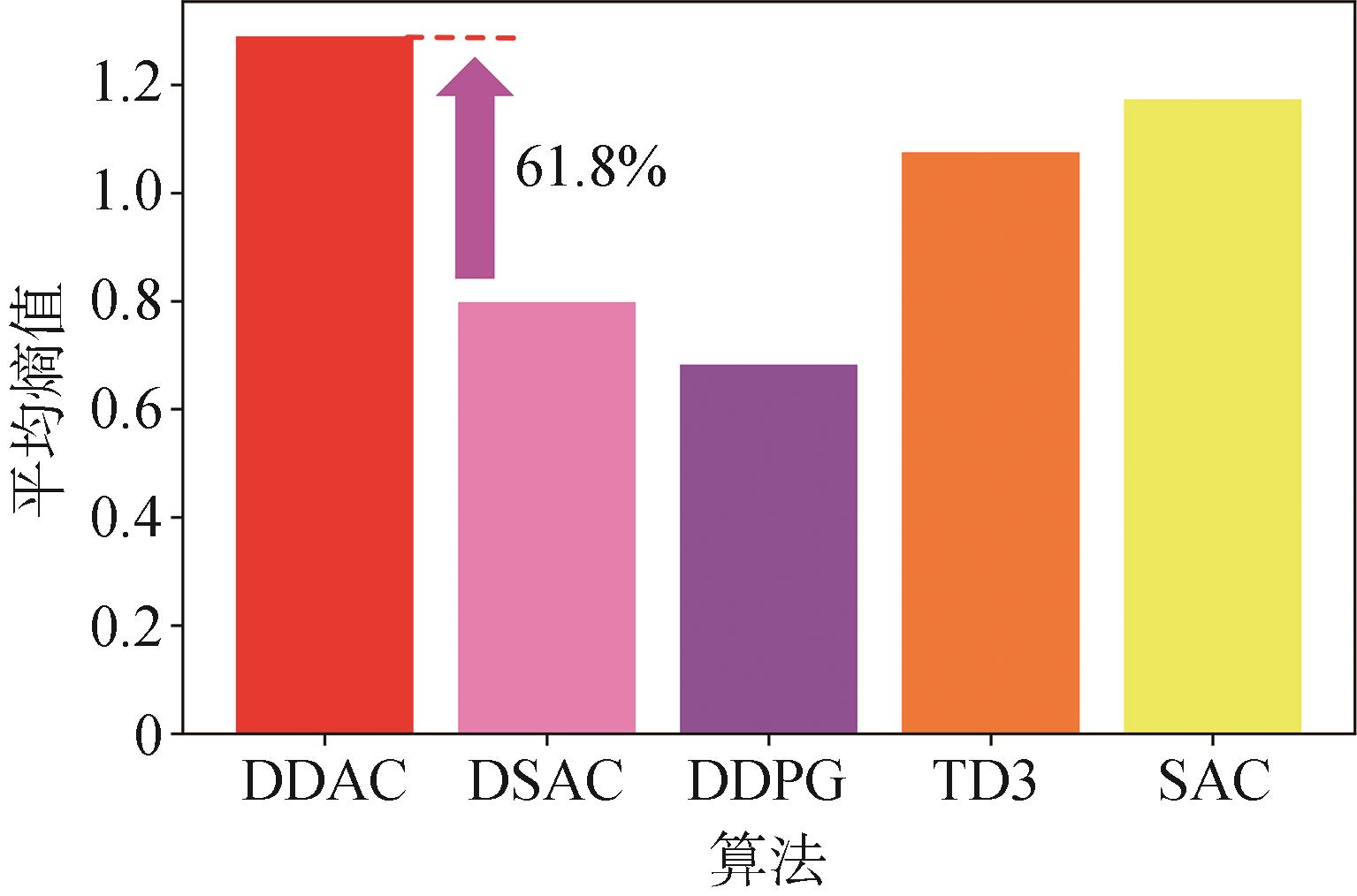
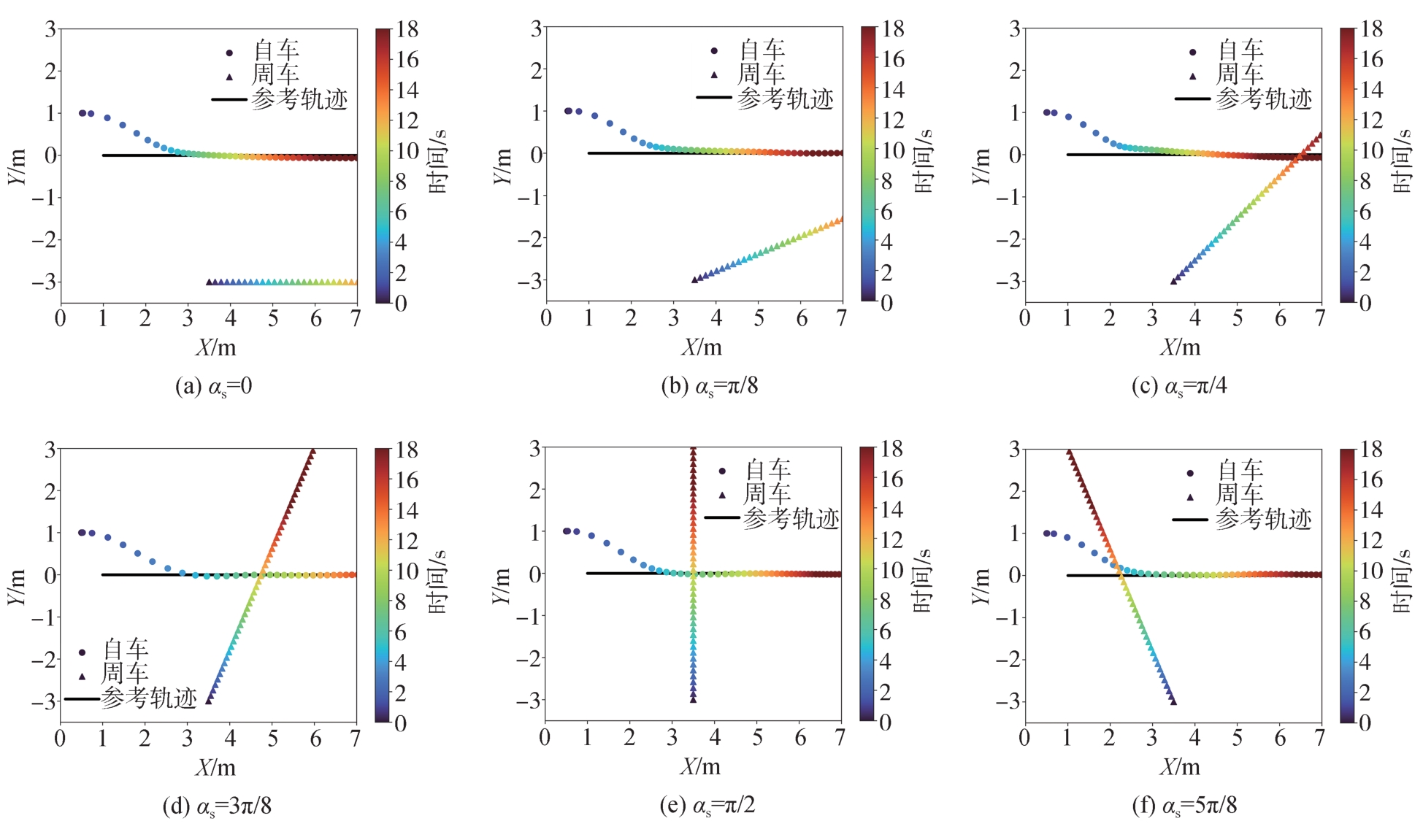
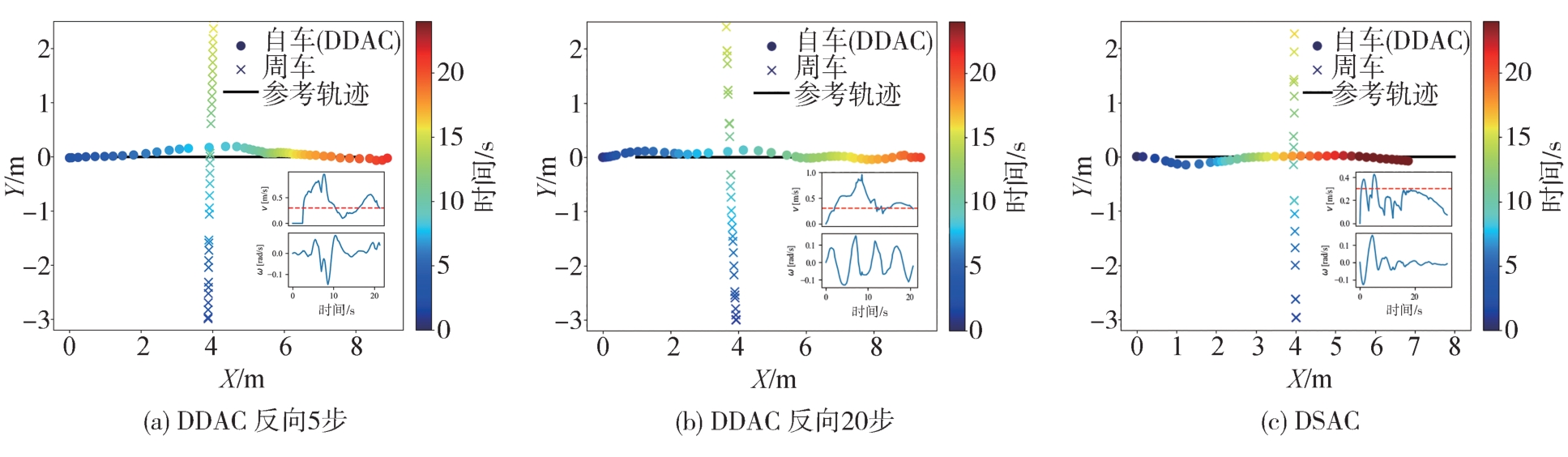
| [1] |
王建,许叁征,甘浩,等. 智能汽车纵深防御关键技术及挑战[C]. 2018 中国汽车工程学会年会论文集,2018:287⁃291.
|
|
WANG J,XU S Z,GAN H,et al. Key technologies and challenges of intelligent vehicle in-depth defense[C]. 2018 SAE-China Annual Conference Proceedings,2018:287-291.
|
| [2] |
肖礼明,张发旺,陈良发,等.依托多风格强化学习的车辆轨迹跟踪避撞控制[J].汽车工程,2024,46(6):945-955.
|
|
XIAO L M,ZHANG F W,CHEN L F,et al. Vehicle trajectory tracking and collision avoidance control based on multi-style reinforcement learning[J]. Automotive Engineering,2024,46(6), 945-955.
|
| [3] |
DUAN J, REN Y, ZHANG F, et al. Encoding distributional soft actor-critic for autonomous driving in multi-lane scenarios [J]. IEEE Computational Intelligence Magazine, 2024, 19(2): 96-112.
|
| [4] |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[J]. arXiv preprint arXiv:, 2013.
|
| [5] |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J]. arXiv preprint arXiv:, 2015.
|
| [6] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:, 2017.
|
| [7] |
MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2016: 1928-1937.
|
| [8] |
HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[C].International Conference on Machine Learning. PMLR, 2018: 1861-1870.
|
| [9] |
DUAN J, GUAN Y, LI S E, et al. Distributional soft actor-critic: off-policy reinforcement learning for addressing value estimation errors[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 33(11): 6584-6598.
|
| [10] |
DUAN J, WANG W, XIAO L, et al. DSAC-T: distributional soft actor-critic with three refinements[J]. arXiv preprint arXiv:, 2023.
|
| [11] |
YANG L, HUANG Z, LEI F, et al. Policy representation via diffusion probability model for reinforcement learning[J]. arXiv preprint arXiv:, 2023.
|
| [12] |
KANG B, MA X, DU C, et al. Efficient diffusion policies for offline reinforcement learning[J]. Advances in Neural Information Processing Systems, 2024, 36.
|
| [13] |
ARENZ O, NEUMANN G, ZHONG M. Efficient gradient-free variational inference using policy search[C].International Conference on Machine Learning. PMLR, 2018: 234-243.
|
| [14] |
TANG Y, AGRAWAL S. Boosting trust region policy optimization by normalizing flows policy[J]. arXiv preprint arXiv:, 2018.
|
| [15] |
HAARNOJA T, TANG H, ABBEEL P, et al. Reinforcement learning with deep energy-based policies[C]. International Conference on Machine Learning. PMLR, 2017: 1352-1361.
|
| [16] |
CROITORU F A, HONDRU V, IONESCU R T, et al. Diffusion models in vision: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
|
| [17] |
SONG Y, DURKAN C, MURRAY I, et al. Maximum likelihood training of score-based diffusion models[J]. Advances in Neural Information Processing Systems, 2021, 34: 1415-1428.
|
| [18] |
DHARIWAL P, NICHOL A. Diffusion models beat gans on image synthesis[J]. Advances in Neural Information Processing Systems, 2021, 34: 8780-8794.
|
| [19] |
SOHL-DICKSTEIN J, WEISS E, MAHESWARANATHAN N, et al. Deep unsupervised learning using nonequilibrium thermodynamics[C]. International Conference on Machine Learning. PMLR, 2015: 2256-2265.
|
| [20] |
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851.
|
| [21] |
WANG Z, HUNT J J, ZHOU M. Diffusion policies as an expressive policy class for offline reinforcement learning[J]. arXiv preprint arXiv:, 2022.
|
| [22] |
AJAY A, DU Y, GUPTA A, et al. Is conditional generative modeling all you need for decision-making?[J]. arXiv preprint arXiv:, 2022.
|
| [23] |
CHEN Y, LI H, ZHAO D. Boosting continuous control with consistency policy[J]. arXiv preprint arXiv:, 2023.
|
| [24] |
CHI C, FENG S, DU Y, et al. Diffusion policy: visuomotor policy learning via action diffusion[J]. arXiv preprint arXiv:, 2023.
|
| [25] |
CODEVILLA F, SANTANA E, LÓPEZ A M, et al. Exploring the limitations of behavior cloning for autonomous driving[C].Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 9329-9338.
|
| [26] |
LY A O, AKHLOUFI M. Learning to drive by imitation: an overview of deep behavior cloning methods[J]. IEEE Transactions on Intelligent Vehicles, 2020, 6(2): 195-209.
|
| [27] |
PSENKA M, ESCONTRELA A, ABBEEL P, et al. Learning a diffusion model policy from rewards via Q-score matching[J]. arXiv preprint arXiv:, 2023.
|
| [28] |
XIAO Z, KREIS K, VAHDAT A. Tackling the generative learning trilemma with denoising diffusion gans[J]. arXiv preprint arXiv:, 2021.
|
| [29] |
WANG W, ZHANG Y, GAO J, et al. GOPS: a general optimal control problem solver for autonomous driving and industrial control applications[J]. Communications in Transportation Research, 2023, 3: 100096.
|
| [30] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:, 2017.
|
 )
)