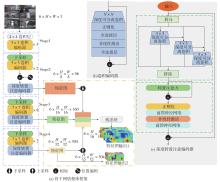
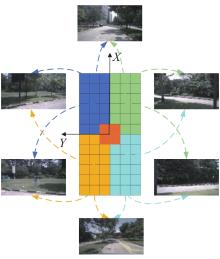
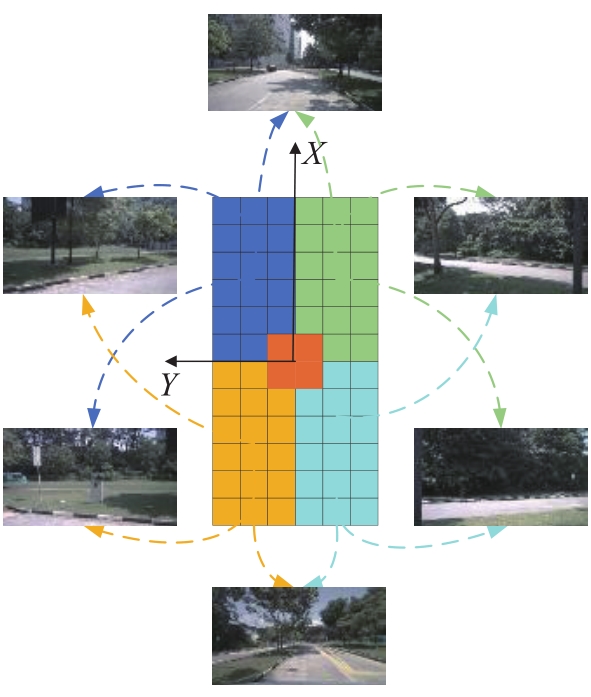
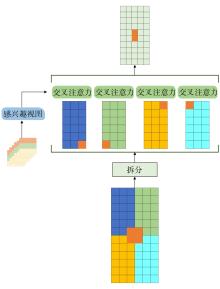
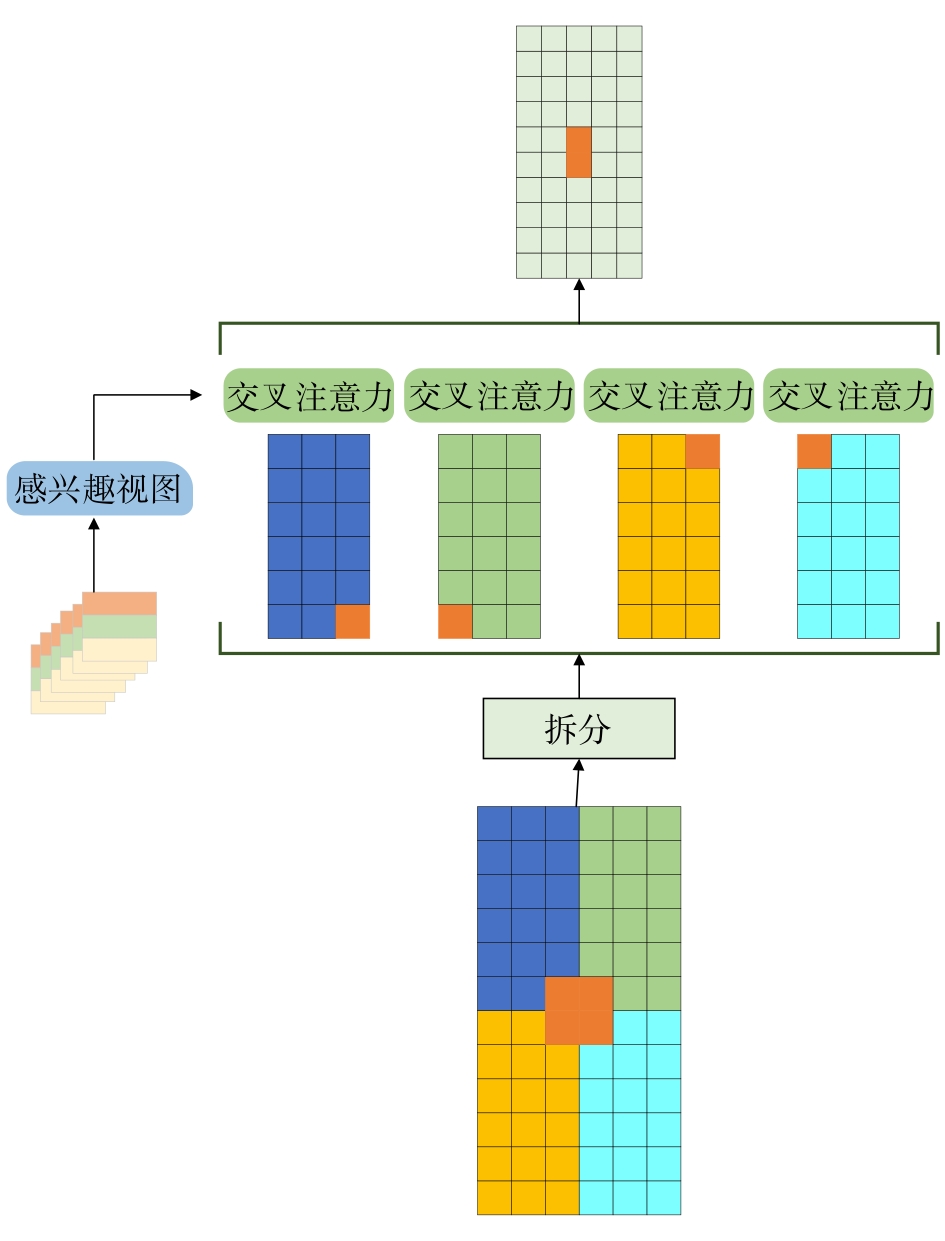
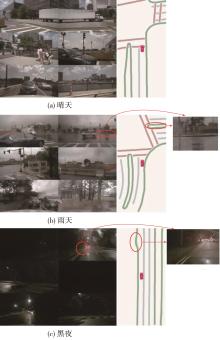
| 1 |
王 海,蔡柏湘,蔡英凤,等. 基于语义分割网络的路面积水与湿滑区域检测[J].汽车工程,2021,43(4):485-491.
|
|
WANG H, CAI B X, CAI Y F, et al. Detection of water⁃covered and wet areas on road pavement based on semantic segmentation network[J]. Automotive Engineering, 2021, 43(4): 485-491.
|
| 2 |
高涛,邢可,刘占文,等. 基于金字塔多尺度融合的交通标志检测算法[J]. 交通运输工程学报, 2022,22(3): 210-224.
|
|
GAO T, XING K, LIU Z W, et al. Traffic sign detection algorithm based on pyramid multi-scale fusion[J].Journal of Traffic and Transportation Engineering, 2022,22(3): 210-224.
|
| 3 |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,40(4): 834-848.
|
| 4 |
RONNEBERGER O, FISCHER P, BROX T. U⁃Net: convolutional networks for biomedical image segmentation[C].2015 International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), 2015:234-241.
|
| 5 |
MALLOT, HANSPETER A, LITTLE J, et al. Inverse perspective mapping simplifies optical flow computation and obstacle detection[J]. Biological Cybernetics, 1991, 64(3): 177-185.
|
| 6 |
PHILION J, FIDLER S. Lift, splat, shoot: encoding images from arbitrary camera rigs by implicitly unprojecting to 3D [C].2020 European Conference on Computer Vision (ECCV 2020), 2020:194-210.
|
| 7 |
LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds[C].2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019: 12689-12697.
|
| 8 |
HU A, MUREZ Z, MOHAN N, et al. FIERY: future instance prediction in bird's-eye view from surround monocular cameras[C].2021 IEEE International Conference on Computer Vision (ICCV2021), 2021:15253-15262.
|
| 9 |
HUANG J, HUANG G, ZHU Z, et al. Bevdet: highperformance multi-camera 3D object detection in bird-eye-view[J]. arXiv preprint arXiv:, 2021.
|
| 10 |
PAN B, SUN J, LEUNG H Y T, et al. Cross view semantic segmentation for sensing surroundings[J]. IEEE Robotics and Automation Letters, 2020,5(3):4867-4873.
|
| 11 |
LI Q, WANG Y, WANG Y, et al. HDMapNet: an online HD map construction and evaluation framework[J]. arXiv preprint arXiv:,2021.
|
| 12 |
ZHOU B, KRHENBÜHL P. Cross-view transformers for real-time map-view semantic segmentation[C].2022 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2022), 2022: 13750-13759.
|
| 13 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C].2017 In Advances in Neural Information Processing Systems (NIPS), 2017.
|
| 14 |
LI Z, WANG W, LI H, et al. BEVFormer: learning bird’s-eye-view representation from multicamera images via spatiotemporal transformers[J]. arXiv preprint arXiv:, 2022.
|
| 15 |
CHEN S Y, CHENG T H, WANG X G, et al. Efficient and robust 2D-to-bev representation learning via geometry-guided kernel transformer[J]. arXiv preprint arXiv:, 2022.
|
| 16 |
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C].2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2017). IEEE Computer Society, 2017:936-944.
|
| 17 |
MUHAMMAD M, ABDELRAHMAN S, HISHAM C, et al. EdgeNeXt: efficiently amalgamated CNN-transformer architecture for mobile vision applications[J]. arXiv preprint arXiv:2206.10589
|
| 18 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C].2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016), 2016:770-778.
|
| 19 |
LONG J, SHELHAMER E, DARRELL T, et al. Fully convolutional networks for semantic segmentation[C].2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), 2015:3431-3440.
|
| 20 |
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications[J]. CoRR abs/1704.04861 (2017).
|
| 21 |
LIU Z, MAO H, WU C Y, et al. A convnet for the 2020s[C].2022 In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2022), 2022: 11966-11976.
|
| 22 |
CAESAR H, BANKITI V, LANG A H, et al. nuScenes: a multimodal dataset for autonomous driving[J]. arXiv preprint arXiv:, 2019.
|
 ),Liu Zheng1,2,娄路1,郑国峰1
),Liu Zheng1,2,娄路1,郑国峰1