Administrator by China Associction for Science and Technology
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Sponsored by China Society of Automotive Engineers
Published by AUTO FAN Magazine Co. Ltd.
Automotive Engineering ›› 2023, Vol. 45 ›› Issue (12): 2280-2290.doi: 10.19562/j.chinasae.qcgc.2023.12.010
Special Issue: 智能网联汽车技术专题-感知&HMI&测评2023年
Previous Articles Next Articles
Linhui Li1,2,Xinliang Zhang1,Yifan Fu1,Jing Lian1,2( ),Jiaxu Ma1
),Jiaxu Ma1
Received:2023-04-22
Revised:2023-05-25
Online:2023-12-25
Published:2023-12-21
Contact:
Jing Lian
E-mail:lianjingdlut@126.com
Linhui Li,Xinliang Zhang,Yifan Fu,Jing Lian,Jiaxu Ma. Research on Visible Light and Infrared Post-Fusion Detection Based on TC-YOLOv7 Algorithm[J].Automotive Engineering, 2023, 45(12): 2280-2290.
"
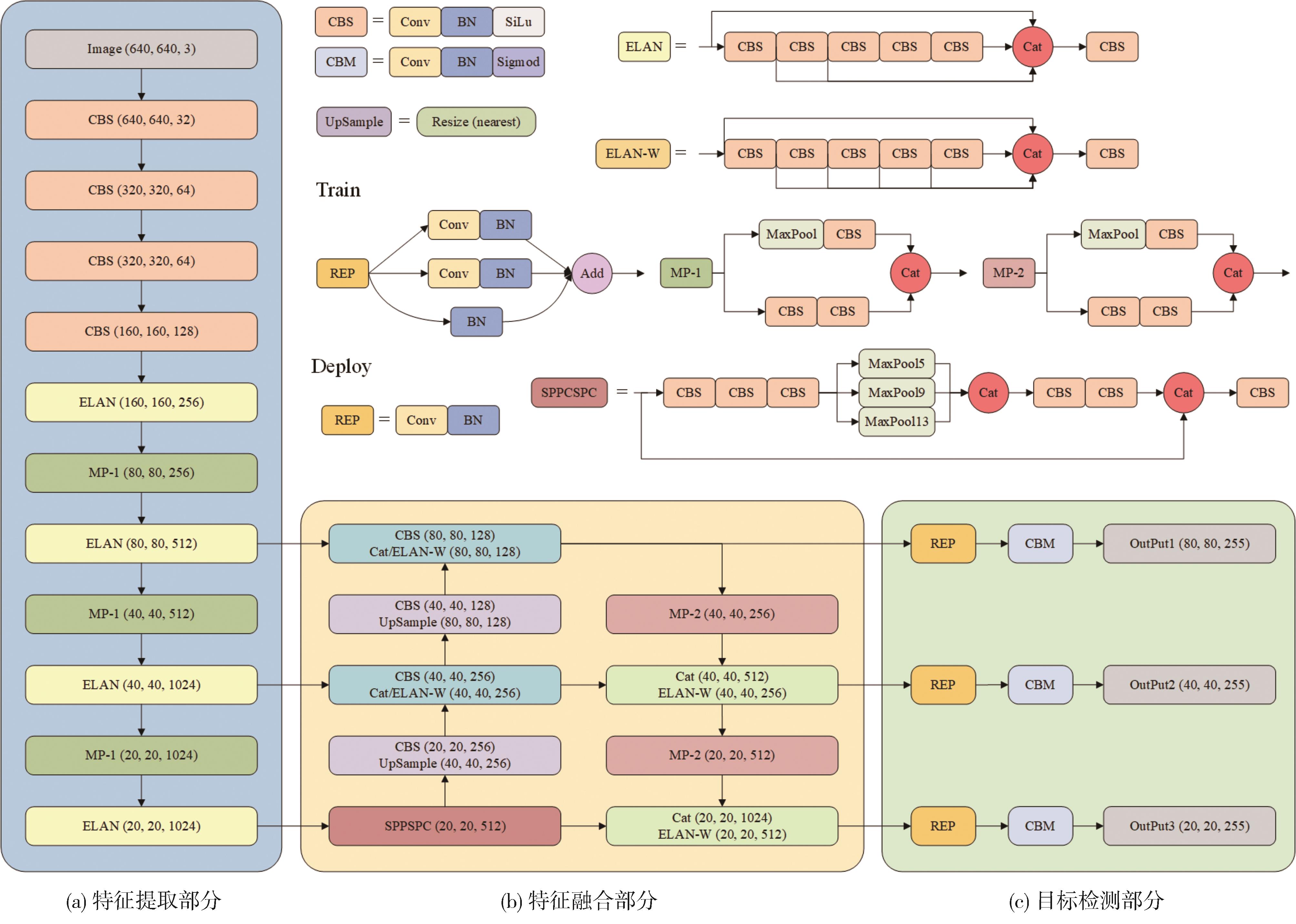

"
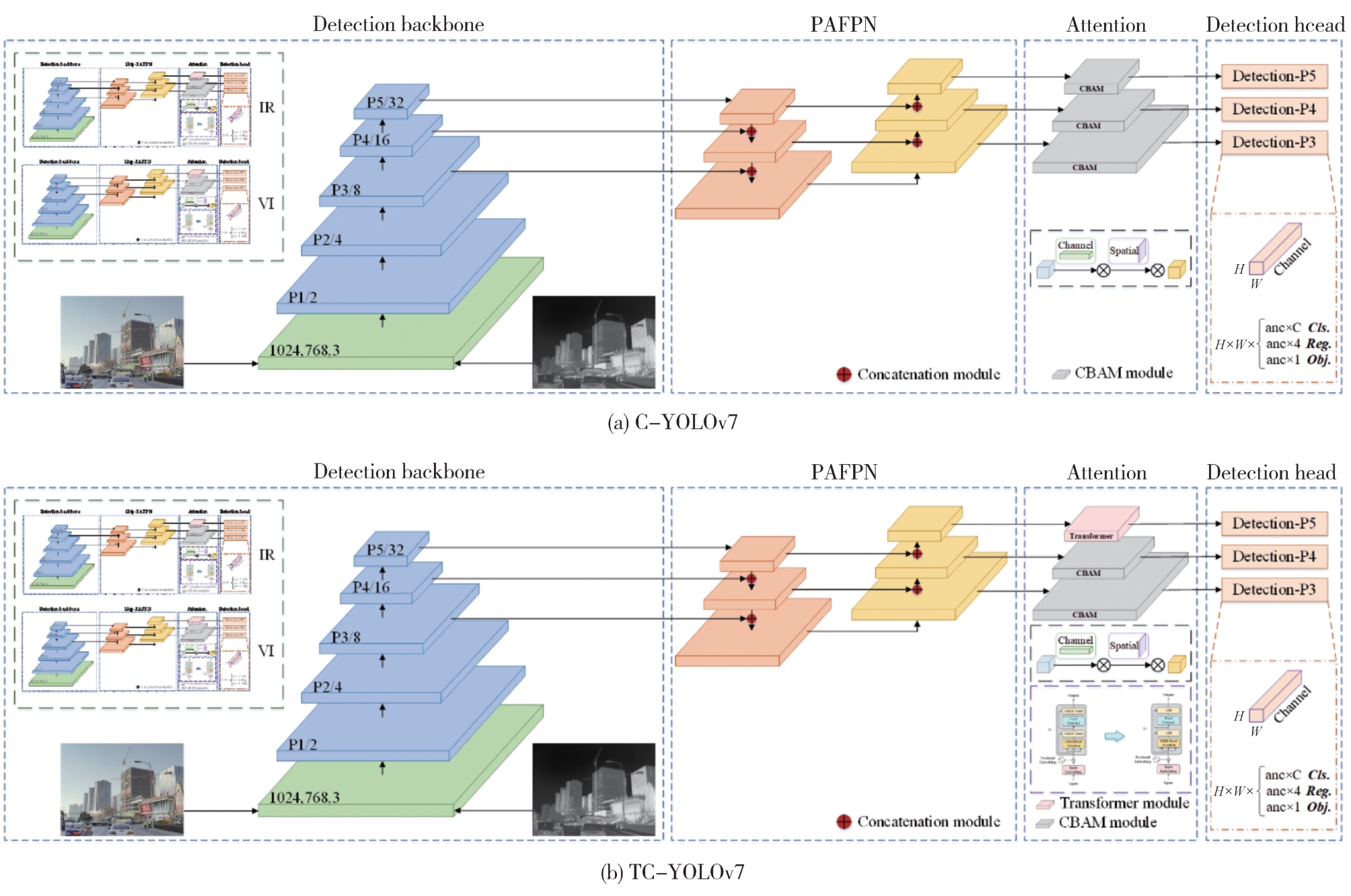
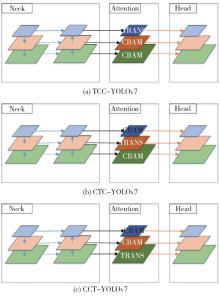
"
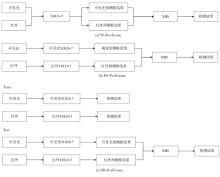
"

"
| 平台主要组成 | 相关配置 |
|---|---|
| GPU | GeForce RTX 3090 |
| CPU | Intel(R) Core(TM) i7-12700K |
| GPU显存 | 24 GB |
| 操作系统 | Linux |
| 计算架构 | CUDA10.1 |
"
| 模型 | 训练集 | 测试集 |
|---|---|---|
SS-PostFusion DS-PostFusion DD-PostFusion | M3FD(3358)(可见光+红外) | M3FD(842)(可见光+红外) |
YOLOv7(可见光) C-YOLOv7(可见光) TC-YOLOv7(可见光) | FLIR(10319)(可见光) | FLIR(3749)(可见光) RTTS(4322) BDD100k(5083/5571) M3FD(4200)(可见光) |
YOLOv7(红外) C-YOLOv7(红外) TC-YOLOv7(红外) | FLIR(10742)(红外) | FLIR(3749)(红外) M3FD(4200)(红外) |
YOLOv7(后融合) TC-YOLOv7(后融合) | FLIR(10319)(可见光) FLIR(10742)(红外) | M3FD(4200)(可见光+红外) |
"
| 模型 | CBAM | Transformer | mAP@.5/% | Precision提升/% | 检测速度/fps |
|---|---|---|---|---|---|
| YOLOv7 | 32.3 | 85 | |||
| C-YOLOv7 | √ | 38.0 | 5.7 | 81 | |
| TC-YOLOv7 | √ | √ | 38.6 | 6.3 | 79 |
"
| 模型 | CBAM | Transformer | mAP@.5/% | Precision提升/% | 检测速度/fps |
|---|---|---|---|---|---|
| YOLOv7 | 53.3 | 100 | |||
| C-YOLOv7 | √ | 55.9 | 2.6 | 86 | |
| TC-YOLOv7 | √ | √ | 56.5 | 3.2 | 89 |
"
| 天气 | 模型 | CBAM | Transformer | mAP@.5/% | Precision提升/% | 检测速度/fps |
|---|---|---|---|---|---|---|
| 雨天 | YOLOv7 | 36.9 | 116 | |||
| C-YOLOv7 | √ | 39.3 | 2.4 | 111 | ||
| TC-YOLOv7 | √ | √ | 40.2 | 3.3 | 109 | |
| 雪天 | YOLOv7 | 36.1 | 116 | |||
| C-YOLOv7 | √ | 37.4 | 1.3 | 111 | ||
| TC-YOLOv7 | √ | √ | 39.4 | 3.3 | 109 |

"
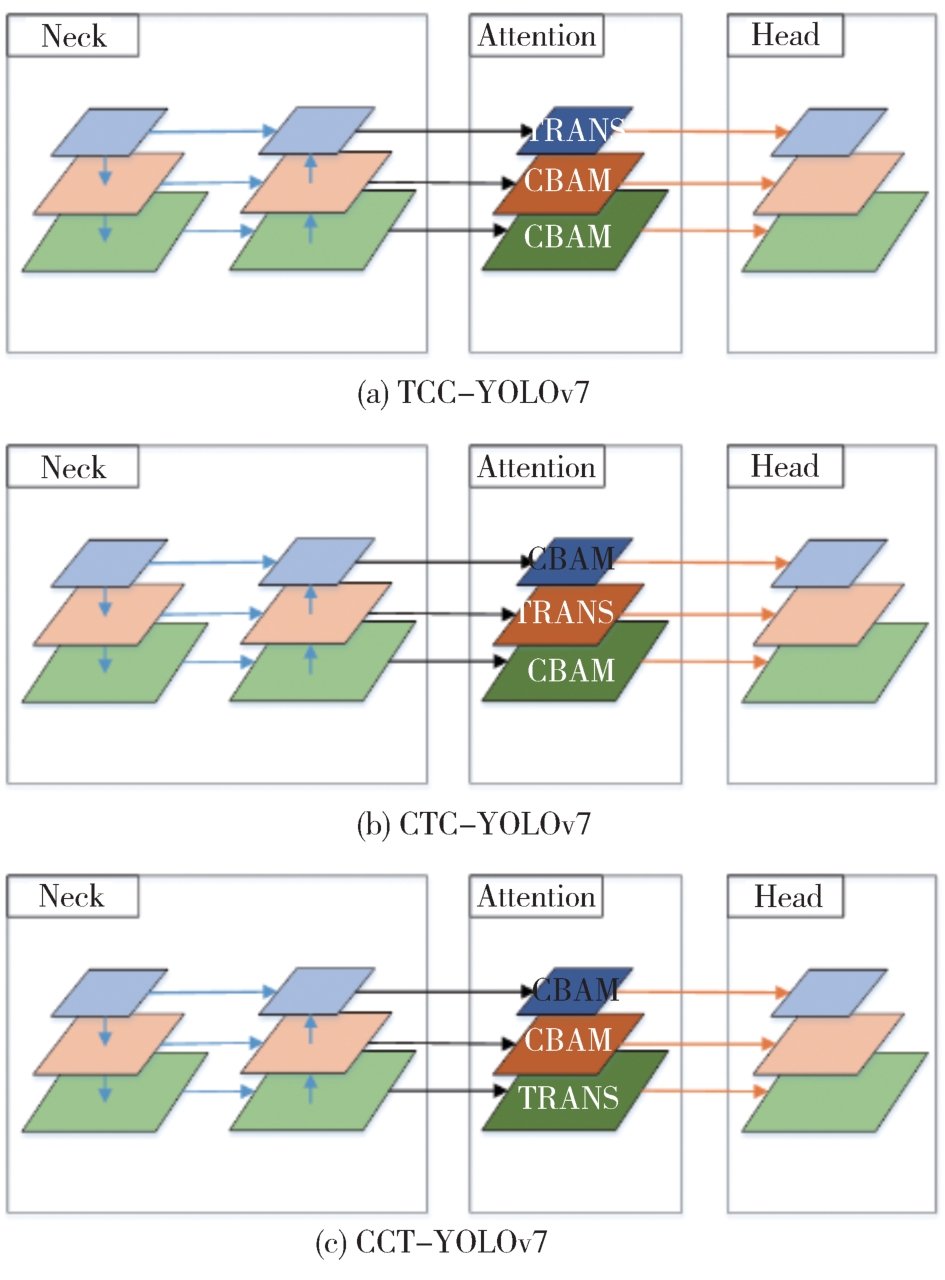
"
| 模型 | CBAM | Transformer Feature Map | mAP@.5/% | Precision 提升/% | 检测 速度/fps |
|---|---|---|---|---|---|
| YOLOv7 | 32.3 | 85 | |||
| C-YOLOv7 | √ | 38.0 | 5.7 | 81 | |
| √ | 80×80 | 38.6 | 6.3 | 53 | |
| CTC-YOLOv7 | √ | 40×40 | 38.8 | 6.5 | 72 |
| TCC-YOLOv7 | √ | 20×20 | 38.6 | 6.3 | 79 |
"
| 模型 | CBAM | Transformer | mAP@.5/% | Precision 提升/% | 检测 速度/fps |
|---|---|---|---|---|---|
| YOLOv7 | 31.7 | 85 | |||
| C-YOLOv7 | √ | 33.0 | 1.3 | 81 | |
| TC-YOLOv7 | √ | √ | 35.4 | 3.7 | 79 |
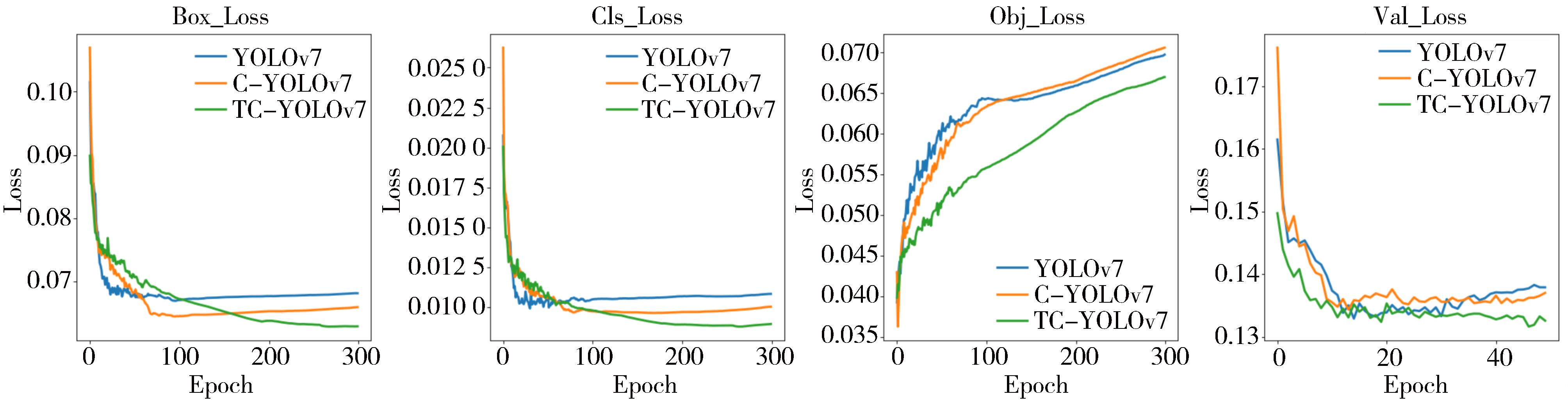
"
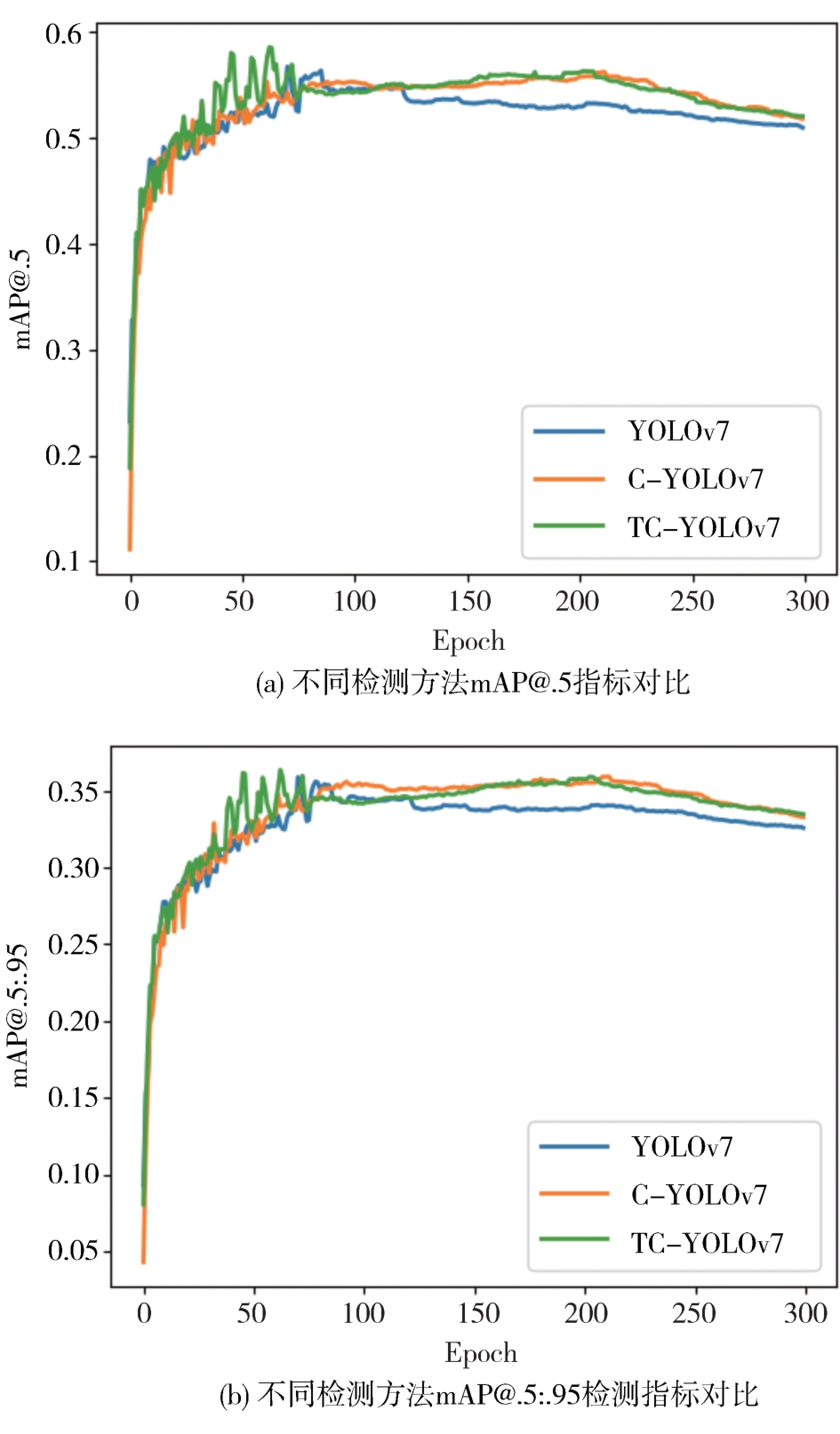
"
| 融合方法 | AP/% | mAP@.5/% | Precision提升/% | 检测速度/fps | |||||
|---|---|---|---|---|---|---|---|---|---|
| Person | Car | Bus | Lamp | Motorcycle | Truck | ||||
| SS-PostFusion | 77.7 | 93.4 | 95.2 | 87.1 | 81.1 | 90.6 | 87.5 | 50 | |
| DS-PostFusion | 76.8 | 93.6 | 93.3 | 87.7 | 81.3 | 89.2 | 87.0 | 49 | |
| DD-PostFusion | 87.4 | 93.8 | 94.0 | 84.6 | 83.4 | 90.9 | 89.0 | 1.5/2.0 | 50 |

"

"
| 模型 | AP/% | mAP@.5/% | Precision 提升/% | 检测 速度/fps | |||||
|---|---|---|---|---|---|---|---|---|---|
| Person | Car | Motorcycle | Bus | Train | Traffic light | ||||
| YOLOv7(可见光) | 50.2 | 83.4 | 44.7 | 60.0 | 46.4 | 52.3 | 56.2 | 91 | |
| TC-YOLOv7(可见光) | 52.4 | 85.5 | 49.4 | 67.1 | 44.3 | 46.4 | 57.5 | 80 | |
| YOLOv7(红外) | 74.4 | 80.2 | 41.8 | 58.2 | 28.0 | 16.5 | 49.9 | 91 | |
| TC-YOLOv7(红外) | 74.6 | 79.6 | 44.0 | 61.2 | 27.7 | 18.1 | 50.9 | 80 | |
| YOLOv7(后融合) | 73.7 | 86.9 | 49.5 | 66.1 | 46.2 | 46.2 | 61.4 | 3.9/10.5 | 48 |
| TC-YOLOv7(后融合) | 74.0 | 87.9 | 54.7 | 68.8 | 45.3 | 41.5 | 62.0 | 4.5/11.1 | 39 |
| 1 | LI L, ZHANG X, LIAN J, et al. Study on practical utility of image dehazing algorithms based on deep learning in computer vision scene understanding[C]. CAAI International Conference on Artificial Intelligence, 2023: 601-612. |
| 2 | MA W, WANG K, LI J, et al. Infrared and visible image fusion technology and application: a review[J]. Sensors, 2023, 23(2): 599. |
| 3 | ZOU Z, SHI Z, GUO Y, et al. Object detection in 20 years: a survey[C]. Proceedings of the IEEE, 2023. |
| 4 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587. |
| 5 | GIRSHICK R. Fast R-CNN[C]. Proceedings of the IEEE International Conference on Computer Vision, 2015: 1440-1448. |
| 6 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. Advances in Neural Information Processing Systems, 2015, 28. |
| 7 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788. |
| 8 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]. European Conference on Computer Vision. Springer, 2016: 21-37. |
| 9 | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]. Proceedings of the IEEE International Conference on Computer Vision, 2017: 2980-2988. |
| 10 | JOCHER G, STOKEN A, BOROVEC J, et al. YOLOv5[EB/OL]. http://doi.org/10.5281/zenodo.4154370. |
| 11 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7464-7475. |
| 12 | GE Z, LIU S, WANG F, et al. Yolox: exceeding YOLO series in 2021[J]. arXiv preprint arXiv:, 2021. |
| 13 | WOO S, PARK J, LEE J Y, et al. Cbam: convolutional block attention module[C]. Proceedings of the European Conference on Computer Vision (ECCV), 2018: 3-19. |
| 14 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132-7141. |
| 15 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017,30. |
| 16 | TELEDYNE F. FLIR thermal dataset for algorithm training[EB/OL]. https://adas-dataset-v2.flirconservator.com. |
| 17 | LI B, REN W, FU D, et al. Benchmarking single image dehazing and beyond[J]. IEEE Transactions on Image Processing, 2018, 28(1): 492-505. |
| 18 | YU F, CHEN H, WANG X, et al. Bdd100k: a diverse driving dataset for heterogeneous multitask learning[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 2636-2645. |
| 19 | LIU J, FAN X, HUANG Z, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5802-5811. |
| [1] | Ze Gao, Zunkang Chu, Jiasheng Shi, Fu Lin, Weixiong Rao, Haiyan Yu. Research on Fast Prediction Method of Stress Field of Automotive Parts Based on Graph Network [J]. Automotive Engineering, 2024, 46(1): 170-178. |
| [2] | Lei Ma, Shunqing Yang, Huanhuan Wang, Jiachen Zhai, Jianao Xu. Lightweight Object Detection Algorithm Based on Image Saliency Feature Fusion [J]. Automotive Engineering, 2024, 46(1): 84-91. |
| [3] | Yongtao Li,Chenxu Sun,Weiguang Zheng,Enyong Xu,Yufang Li,Shanchao Wang. Collision Warning Based on Fusion of Millimeter Wave Radar and Vision [J]. Automotive Engineering, 2023, 45(9): 1666-1676. |
| [4] | Weiguo Liu,Zhiyu Xiang,Rui Liu,Guodong Li,Zixu Wang. Research on End-to-End Vehicle Motion Planning Method Based on Deep Learning [J]. Automotive Engineering, 2023, 45(8): 1343-1352. |
| [5] | Dongyu Zhao, Shuen Zhao. Autonomous Driving 3D Object Detection Based on Cascade YOLOv7 [J]. Automotive Engineering, 2023, 45(7): 1112-1122. |
| [6] | Zhenfeng Pu, Liang Tang, Wenbin Shangguan, Weiwei Wang, Kaihong Jiang. Research on the Estimation of Vehicle Speed Under Low-Speed Conditions Based on Multi-sensor Information [J]. Automotive Engineering, 2023, 45(7): 1235-1243. |
| [7] | Jiahao Zhao,Zhiquan Qi,Zhifeng Qi,Hao Wang,Lei He. Calculation of Heading Angle of Parallel Large Vehicle Based on Tire Feature Points [J]. Automotive Engineering, 2023, 45(6): 1031-1039. |
| [8] | Xia Zhao,Zhao Li,Rui Fu,Zhenzhen Ge,Chang Wang. Real-Time Detection of Distracted Driving Behavior Based on Deep Convolution-Tokens Dimensionality Reduction Optimized Visual Transformer Model [J]. Automotive Engineering, 2023, 45(6): 974-988. |
| [9] | Yanyan Chen,Hai Wang,Yingfeng Cai,Long Chen,Yicheng Li. Efficient Automatic Driving Instance Segmentation Method Based on Detection [J]. Automotive Engineering, 2023, 45(4): 541-550. |
| [10] | Fengchong Lan,Jikai Chen,Jiqing Chen,Xinping Jiang,Zihan Li,Wei Pan. Research on Lithium Battery Remaining Useful Life Prediction Method Driven by Real Vehicle Data [J]. Automotive Engineering, 2023, 45(2): 175-182. |
| [11] | Long Chen,Chen Yang,Yingfeng Cai,Hai Wang,Yicheng Li. Pedestrian Crossing Intention Prediction Method Based on Multimodal Feature Fusion [J]. Automotive Engineering, 2023, 45(10): 1779-1790. |
| [12] | Xiaojun Zhang,Jingzhe Xi,Yanlei Shi,Anlu Yuan. Lightweight YOLOv7-R Algorithm for Road-Side View Target Detection [J]. Automotive Engineering, 2023, 45(10): 1833-1844. |
| [13] | Jie Hu,Yuanjie Li,Hao Geng,Huangzheng Geng,Xiong Guo,Hongwei Yi. Construction of Vehicle Fault Knowledge Graph Based on Deep Learning [J]. Automotive Engineering, 2023, 45(1): 52-60. |
| [14] | Jie Hu,Boyuan Xu,Zongquan Xiong,Minjie Chang,Di Guo,Lihao Xie. Cross-Domain Object Detection Algorithm Based on Multi-scale Mask Classification Domain Adaptive Network [J]. Automotive Engineering, 2022, 44(9): 1327-1338. |
| [15] | Guihong Bi,Xu Xie,Zilong Cai,Zhao Luo,Chenpeng Chen,Xin Zhao. Capacity Estimation of Lithium-ion Battery Based on Deep Learning Under Dynamic Conditions [J]. Automotive Engineering, 2022, 44(6): 868-878. |
|