汽车工程 ›› 2025, Vol. 47 ›› Issue (10): 1895-1904.doi: 10.19562/j.chinasae.qcgc.2025.10.005
• • 上一篇
王欢欢1,金立生1,2( ),张也1,符旭朋1
),张也1,符旭朋1
收稿日期:2024-12-06
修回日期:2025-04-26
出版日期:2025-10-25
发布日期:2025-10-20
通讯作者:
金立生
E-mail:jinls@ysu.edu.cn
基金资助:
Huanhuan Wang1,Lisheng Jin1,2(),Ye Zhang1,Xupeng Fu1
Received:2024-12-06
Revised:2025-04-26
Online:2025-10-25
Published:2025-10-20
Contact:
Lisheng Jin
E-mail:jinls@ysu.edu.cn
摘要:
针对复杂场景中弱势道路使用者检测面临的目标遮挡、特征冲突和前景背景模糊的问题,本文提出一种基于图像显著性特征融合的轻量化弱势道路使用者检测算法。首先,基于重构的方法提取图像的显著性特征,将其与彩色图像分别输入卷积神经网络。其次,构建轻量化非权重共享特征提取融合网络,实现特征深度融合。在此基础上,引入混合注意力机制,提出高效注意力层聚模块,提高关键特征利用效率。最后,在构建的复杂场景多类别弱势道路使用者数据集进行训练和测试。结果表明:提出的模型能够在复杂交通场景下高效准确地检测弱势道路使用者,平均度达到94.3%,精确率达到94.6%,FPS达到23.25 Hz,相比于基线网络YOLOv7平均精度提高了2.1%,精确率提高了3.5%。
王欢欢,金立生,张也,符旭朋. 基于图像显著性特征融合的弱势道路使用者检测算法[J]. 汽车工程, 2025, 47(10): 1895-1904.
Huanhuan Wang,Lisheng Jin,Ye Zhang,Xupeng Fu. Vulnerable Road User Detection Method Based on Image Salient Feature Fusion[J]. Automotive Engineering, 2025, 47(10): 1895-1904.
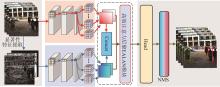
图1
模型总体框架"
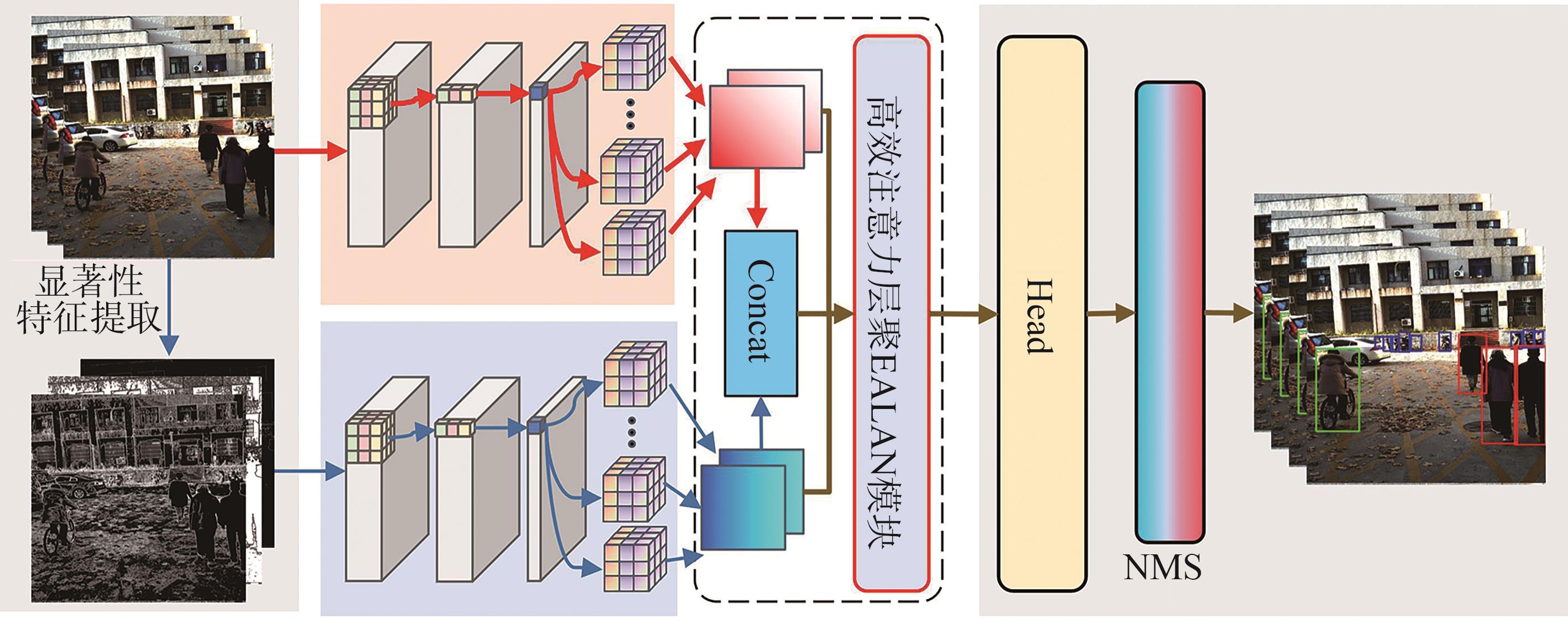

图2
从图像中提取的边界和纹理特征"

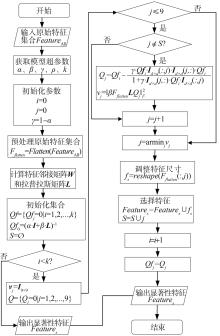
图3
基于重构特征选择算法流程图"
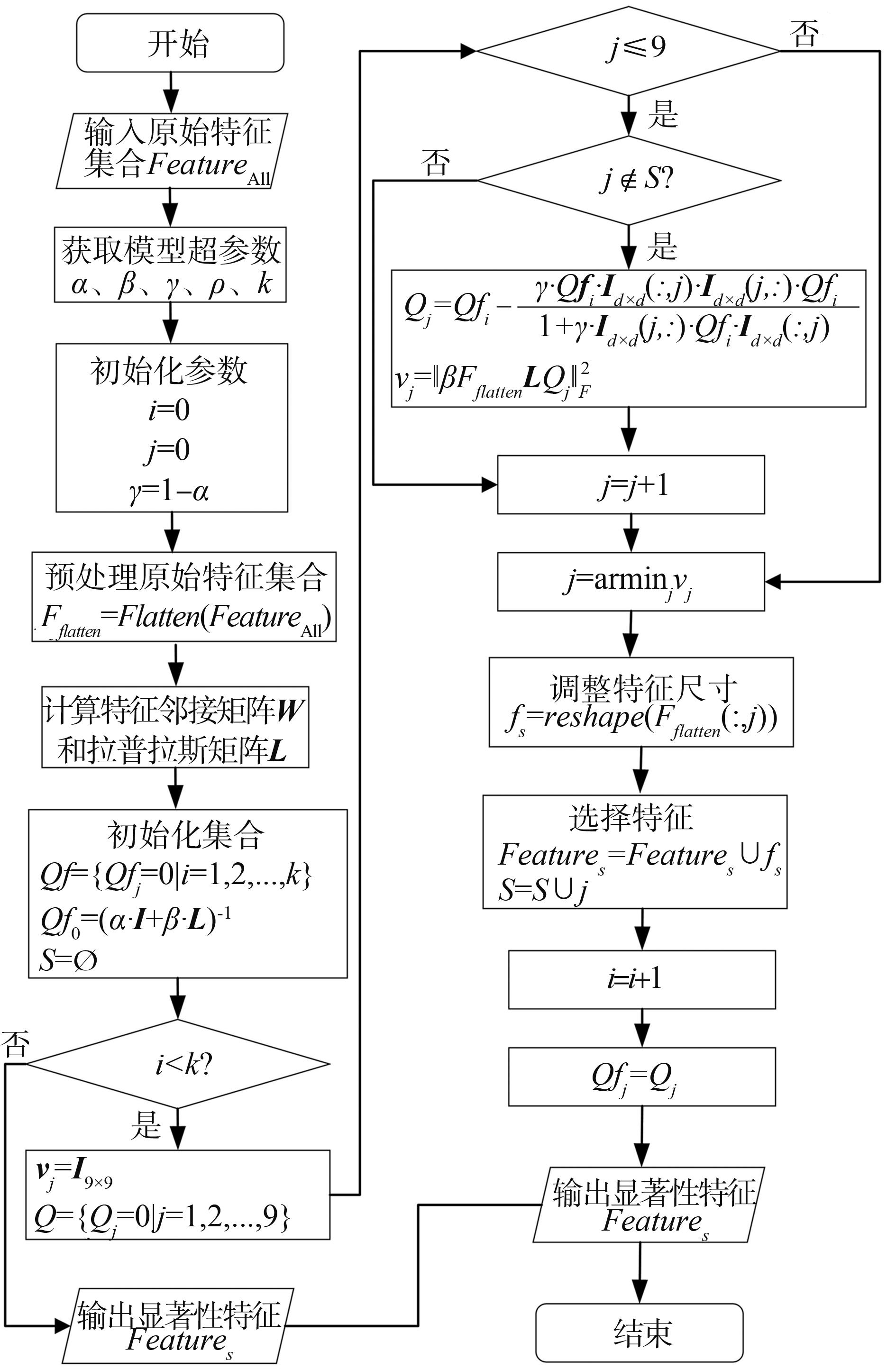

图4
原始图片和提取的显著特征"

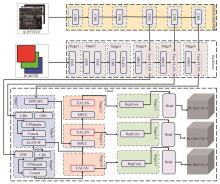
图5
融合图像显著性特征的目标检测网络结构"

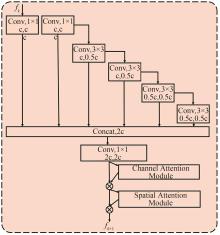
图6
高效注意力层聚网络EALAN"
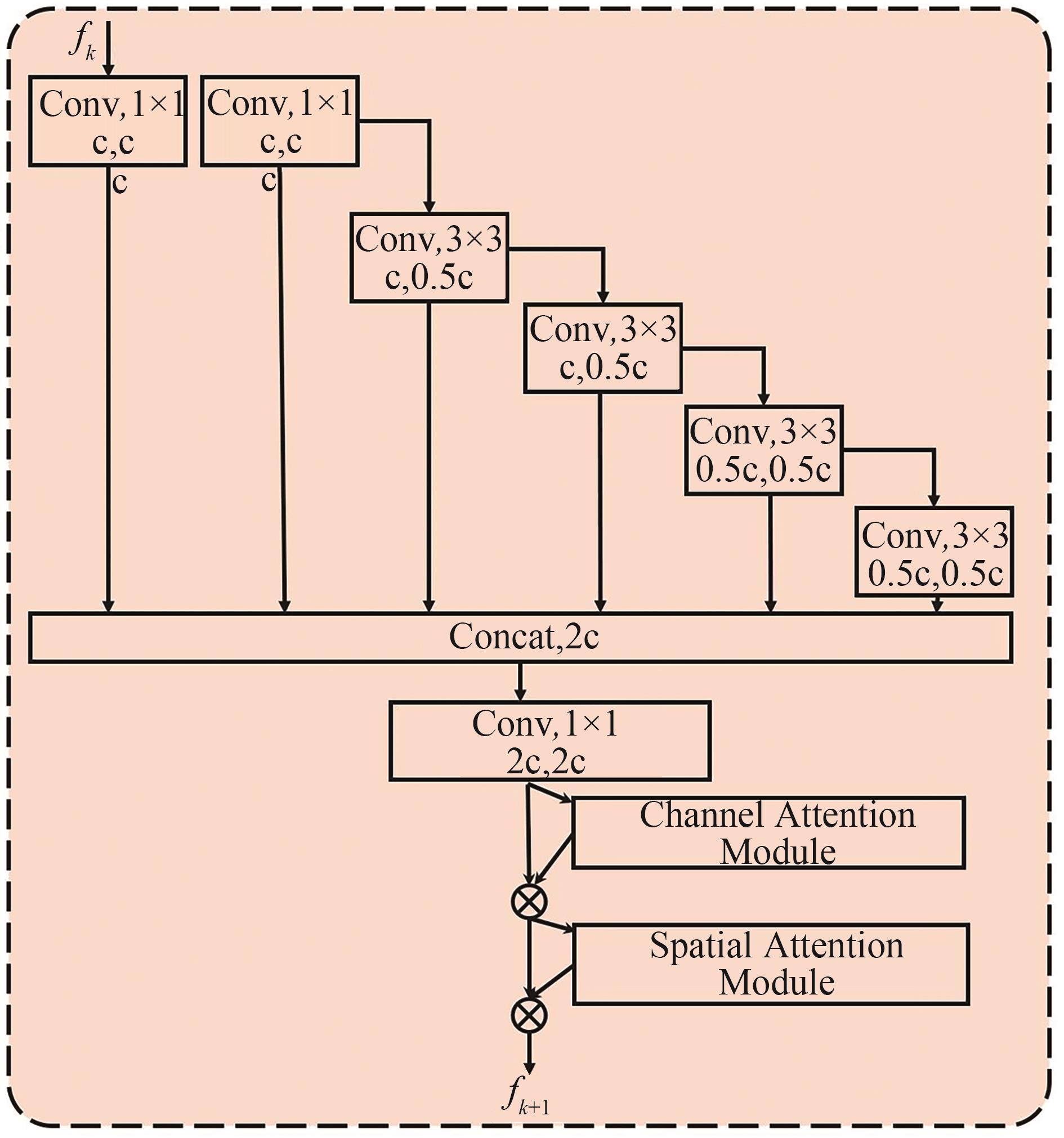
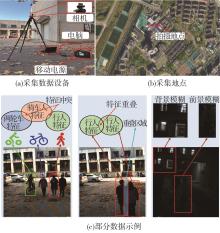
图7
数据采集装置、地点和采集的部分数据"
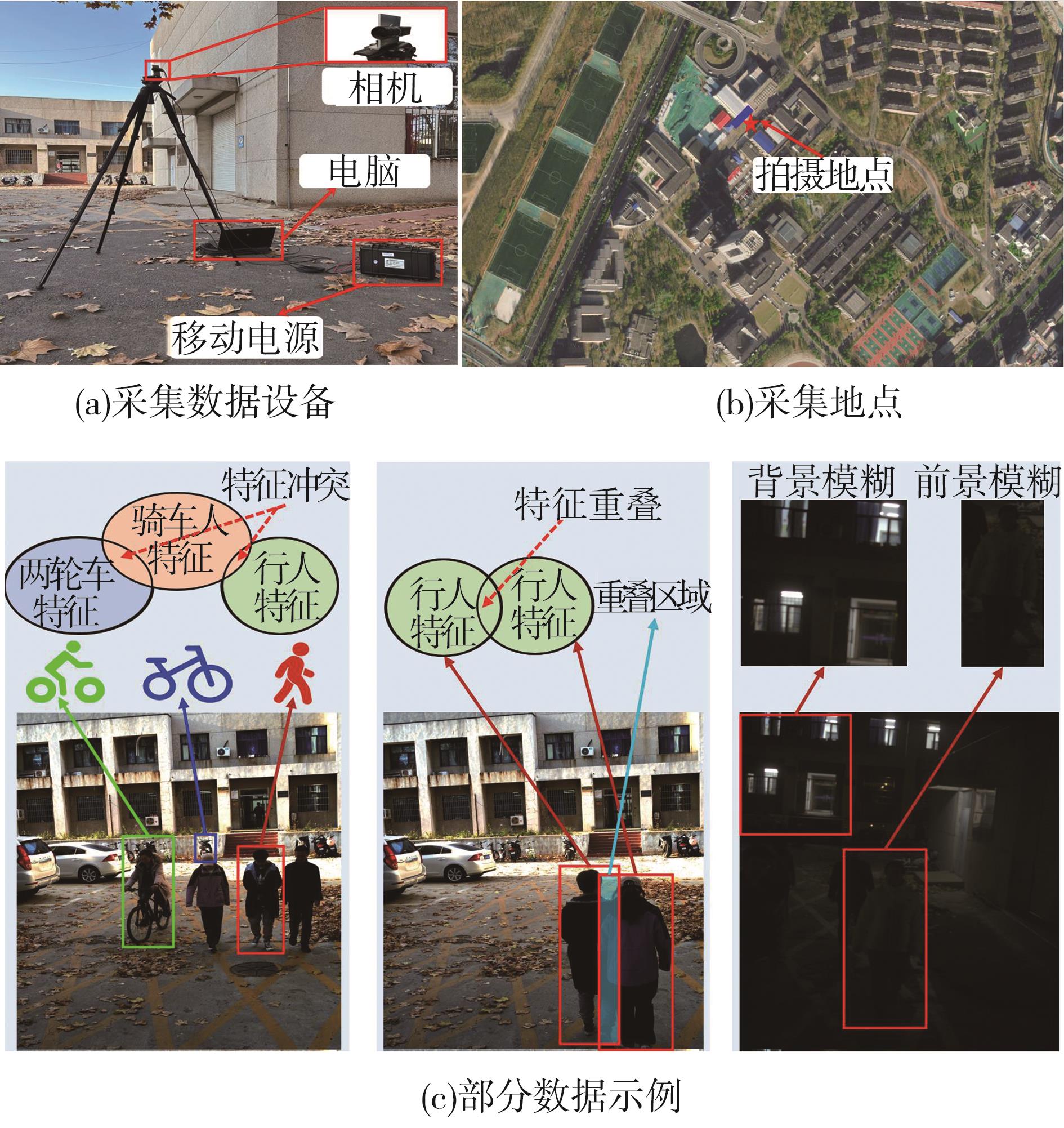
表1
相机传感器参数"
| 指标 | 数值 |
|---|---|
| 型号 | MV-CA050-10GC |
| 分辨率 | |
| 输入电压 | Typ. 3.1 W@12 VDC |
| 数据接口 | GigE |
表2
场景的设置"
场景 条件 | 场景 1 | 场景 2 | 场景 3 | 场景 4 | 场景 5 | 场景 6 | 场景 8 | 场景 8 |
|---|---|---|---|---|---|---|---|---|
| 白天 | √ | √ | √ | √ | ||||
| 夜间 | √ | √ | √ | √ | ||||
| 两轮车 | √ | √ | √ | √ | √ | √ | √ | √ |
| 行人 | √ | √ | √ | √ | ||||
| 骑车人 | √ | √ | √ | √ |
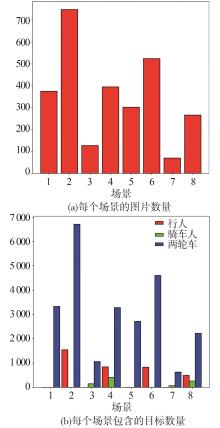
图8
数据集统计"
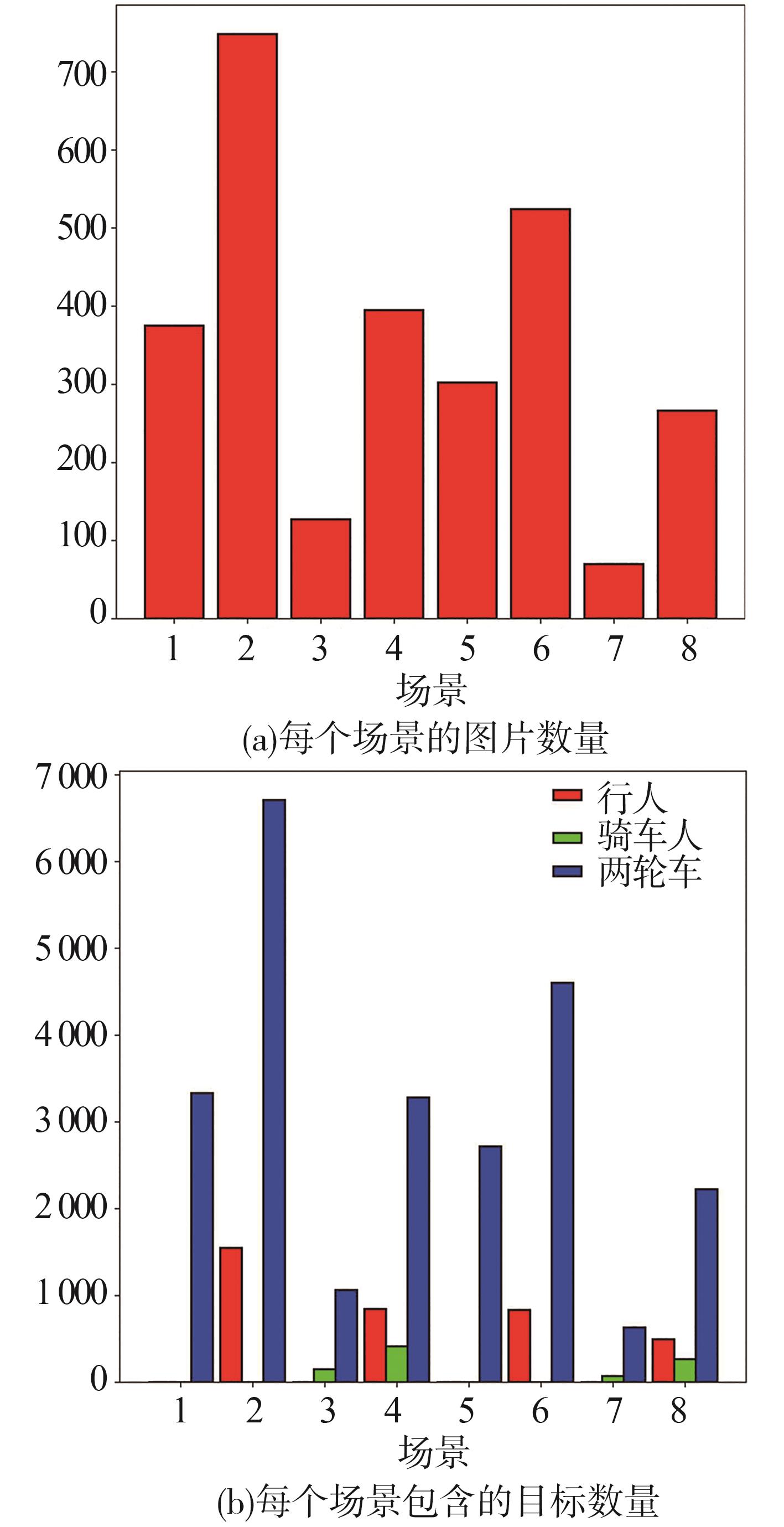
表3
实验平台"
| 平台 | 配置 |
|---|---|
| 集成开发环境 | PyCharm |
| 脚本语言 | Python |
| 深度学习框架 | PyTorch |
| CPU 型号 | Inter Core i7-10700K |
| 操作系统 | Ubuntu 18.04 |
| GPU 型号 | NVIDIA GeForce RTX 2070 Super |
| GPU 加速器 | CUDA 10.2 |
表4
训练参数设置"
| 参数 | 配置 |
|---|---|
| 神经网络优化器 | SGD |
| 学习率 | 0.01 |
| 训练次数 | 50 |
| 动量 | 0.937 |
| 批量大小 | 1 |
| 权重衰减 | 0.000 5 |
| 输入图像尺寸 | [640,640] |
| 锚框尺寸 | [ [ [142,110],[192,243],[459,401] Stage15 |
| 训练IoU阈值 | 0.2 |
表5
消融实验结果"
| 基线 | 显著特征融合 | EALAN | WIoU | Precision/%↑ | Precision/ %↑ | Recall/ %↑ | mAP/ %↑ | Params/ M↓ | FLOPS/ G↓ | FPS/ Hz↑ | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 行人 | 骑车人 | 两轮车 | ||||||||||
| YOLOv7 | 0.921 | 0.871 | 0.935 | 0.909 | 0.875 | 0.922 | 36.49 | 103.2 | 25.84 | |||
| √ | 0.937 | 0.952 | 0.933 | 0.941 | 0.848 | 0.921 | 37.23 | 105.3 | 23.81 | |||
| √ | 0.920 | 0.903 | 0.957 | 0.927 | 0.847 | 0.931 | 36.54 | 103.3 | 25.41 | |||
| √ | 0.941 | 0.852 | 0.887 | 0.893 | 0.855 | 0.923 | 36.49 | 103.2 | 25.87 | |||
| √ | √ | 0.938 | 0.919 | 0.955 | 0.937 | 0.860 | 0.918 | 37.27 | 105.4 | 23.47 | ||
| √ | √ | 0.927 | 0.918 | 0.955 | 0.933 | 0.862 | 0.933 | 37.23 | 105.3 | 23.55 | ||
| √ | √ | 0.921 | 0.938 | 0.968 | 0.942 | 0.868 | 0.936 | 36.54 | 103.3 | 25.32 | ||
| √ | √ | √ | 0.968 | 0.898 | 0.971 | 0.946 | 0.879 | 0.943 | 37.27 | 105.4 | 23.25 | |
表6
不同模型的对比结果"
| 方法 | Precision/%↑ | Precision/%↑ | Recall/%↑ | mAP/%↑ | FPS/Hz↑ | ||
|---|---|---|---|---|---|---|---|
| 行人 | 骑车人 | 两轮车 | |||||
| Faster R-CNN (ResNet50+FPN)[ | 0.824 | 0.851 | 0.897 | 0.857 | 0.816 | 0.887 | 11.96 |
| YOLOv5[ | 0.926 | 0.918 | 0.954 | 0.932 | 0.866 | 0.942 | 23.27 |
| YOLOX-s[ | 0.934 | 0.902 | 0.897 | 0.911 | 0.907 | 0.913 | 19.51 |
| YOLOR-p6[ | 0.922 | 0.915 | 0.953 | 0.93 | 0.897 | 0.921 | 17.83 |
| YOLOv7[ | 0.921 | 0.871 | 0.935 | 0.909 | 0.875 | 0.922 | 25.84 |
| YOLOv8[ | 0.925 | 0.899 | 0.941 | 0.921 | 0.891 | 0.932 | 32.13 |
| YOLOv11[ | 0.920 | 0.798 | 0.967 | 0.895 | 0.885 | 0.920 | 39.42 |
| YOLOv7+SE[ | 0.922 | 0.875 | 0.938 | 0.912 | 0.871 | 0.924 | 23.10 |
| YOLOv7+CA[ | 0.924 | 0.871 | 0.929 | 0.908 | 0.882 | 0.919 | 22.91 |
| YOLOv7+ESCA[ | 0.933 | 0.880 | 0.951 | 0.921 | 0.893 | 0.930 | 21.42 |
| 本文方法 | 0.968 | 0.898 | 0.971 | 0.946 | 0.879 | 0.943 | 23.25 |
表7
不同模型的对比结果"
| 方法 | Precision/%↑ | Precision/ %↑ | mAP/ %↑ | FPS/ Hz↑ | |
|---|---|---|---|---|---|
| 行人 | 骑车人 | ||||
| Faster R-CNN[ | 0.782 | 0.818 | 0.797 | 0.802 | 13.48 |
| YOLOv5[ | 0.901 | 0.911 | 0.906 | 0.914 | 25.17 |
| YOLOX-s[ | 0.910 | 0.903 | 0.907 | 0.901 | 22.64 |
| YOLOR-p6[ | 0.891 | 0.919 | 0.905 | 0.918 | 20.44 |
| YOLOv7[ | 0.925 | 0.907 | 0.916 | 0.919 | 27.49 |
| YOLOv8[ | 0.931 | 0.920 | 0.925 | 0.933 | 33.76 |
| YOLOv11[ | 0.902 | 0.907 | 0.905 | 0.906 | 40.27 |
| YOLOv7+SE | 0.927 | 0.914 | 0.921 | 0.923 | 24.86 |
| YOLOv7+CA | 0.916 | 0.905 | 0.911 | 0.916 | 23.81 |
| YOLOv7+ESCA | 0.929 | 0.923 | 0.926 | 0.930 | 24.66 |
| 本文方法 | 0.932 | 0.954 | 0.943 | 0.949 | 24.68 |

图9
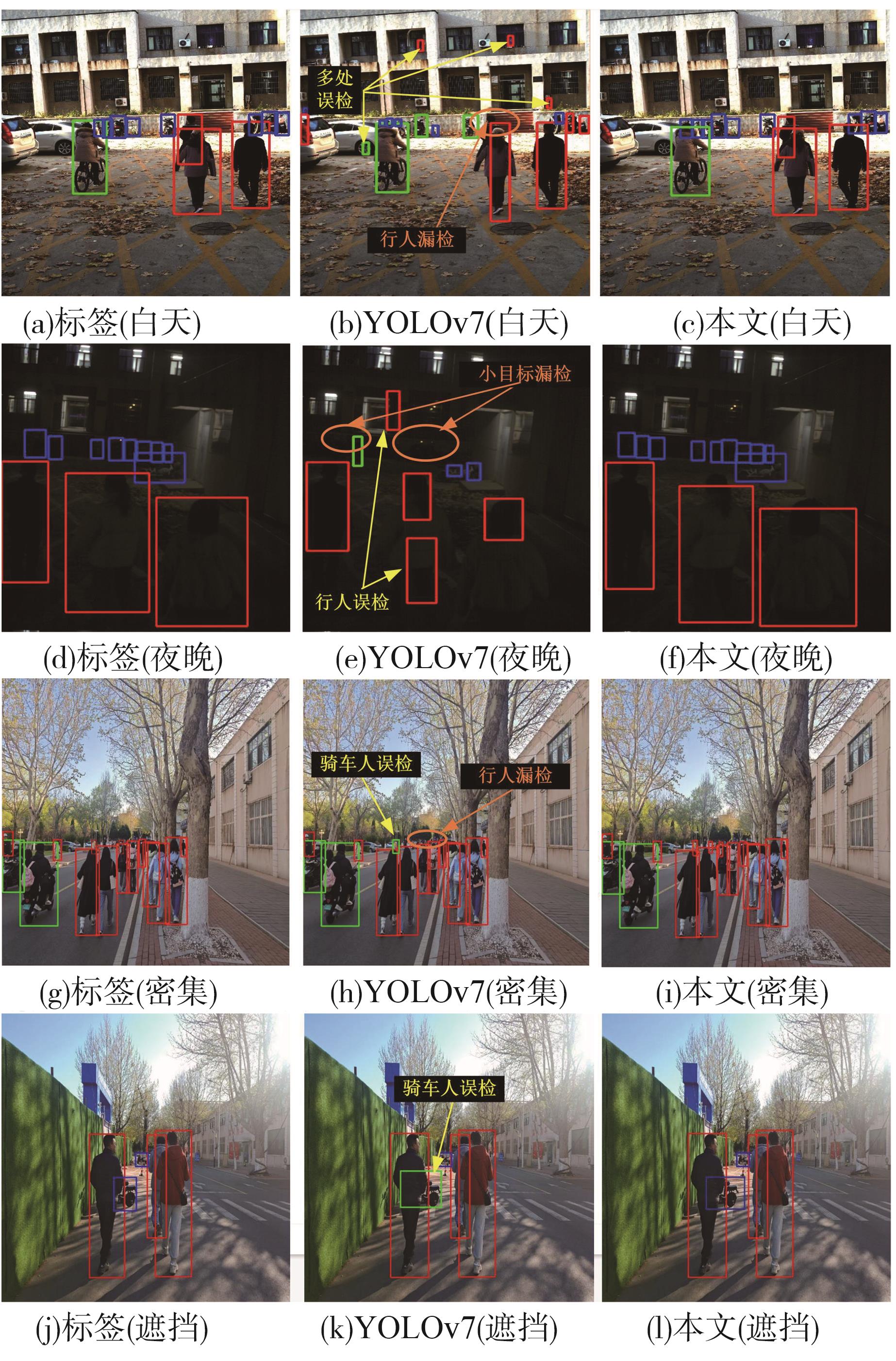
检测结果可视化"
| [1] | OLSZEWSKI P, SZAGALA P, RABCZENKO D, et al. Investigating safety of vulnerable road users in selected EU countries[J]. Journal of Safety Research, 2019, 68: 49-57. |
| [2] | World Health Organization. Global status report on road safety 2023[R]. World Health Organization, 2023. |
| [3] | LI G, YANG Y, QU X. Deep learning approaches on pedestrian detection in hazy weather[J]. IEEE Transactions on Industrial Electronics, 2019, 67(10): 8889-8899. |
| [4] | 肖振久,李思琦,曲海成.基于多尺度特征与互监督的拥挤行人检测[J].计算机工程与科学,2024,46(7):1278-1285. |
| XIAO Z J, LI S Q, QU H C. Pedestrian detection based on multi-scale features and mutual supervision[J]. Computer Engineering & Science, 2024,46(7):1278-1285. | |
| [5] | SROCZYNSKI A, KUROWSKI A, ZAPOROWSKI S, et al. Examining impact of speed recommendation algorithm operating in autonomous road signs on minimum distance between vehicles[J]. Remote Sensing, 2022, 14(12): 2803. |
| [6] | ZHANG S, YANG X, LIU Y, et al. Asymmetric multi-stage CNNs for small-scale pedestrian detection[J]. Neurocomputing, 2020, 409: 12-26. |
| [7] | 马超凡,李翔,王晓霞,等.基于重参数化的轻量化非机动车目标检测[J/OL].计算机工程与应用,1-10[2024-10-08].http://kns.cnki.net/kcms/detail/11.2127.tp.20240522.1323.006.html. |
| MA C F, LI X, WANG X X, et al. Lightweight non-motor vehicle target detection based on re-parameterization [J/OL]. Computer Engineering and Applications,[2024-10-08].http://kns.cnki.net/kcms/detail/11.2127.tp.20240522.1323.006.html. | |
| [8] | LIN C, LU J, ZHOU J. Multi-grained deep feature learning for robust pedestrian detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 29(12): 3608-3621. |
| [9] | 高广鹏,赵峰.基于并行局部特征金字塔的弱势道路使用者检测[J].计算机应用与软件,2022,39(1):151-157,249. |
| GAO G P, ZHAO F. Vulnerable road users detection based on parallel local features pyramid network[J]. Computer Applications and Software, 2022, 39(1):151-157,249. | |
| [10] | FENG D, HAASE-SCHUTZ C, ROSENBAUM L, et al. Deep multi-modal object detection and semantic segmentation for autonomous driving: datasets, methods, and challenges[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 22(3): 1341-1360. |
| [11] | FENG X, HAN J, YAO X, et al. TCANet: triple context-aware network for weakly supervised object detection in remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 59(8): 6946-6955. |
| [12] | LI Y, YU A W, MENG T, et al. Deepfusion: lidar-camera deep fusion for multi-modal 3D object detection[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022: 17182-17191. |
| [13] | PAL S K, PRAMANIK A, MAITI J, et al. Deep learning in multi-object detection and tracking: state of the art[J]. Applied Intelligence, 2021, 51: 6400-6429. |
| [14] | DAI X, HU J, ZHANG H, et al. Multi-task faster R-CNN for nighttime pedestrian detection and distance estimation[J]. Infrared Physics & Technology, 2021, 115: 103694. |
| [15] | BRAZIL G, YIN X, LIU X. Illuminating pedestrians via simultaneous detection & segmentation[C]. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017: 4950-4959. |
| [16] | MAO J, XIAO T, JIANG Y, et al. What can help pedestrian detection?[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 3127-3136. |
| [17] | HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021: 13713-13722. |
| [18] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018: 7132-7141. |
| [19] | LIU H, ZHANG Y, CHEN Y. A symmetric efficient spatial and channel attention (ESCA) module based on convolutional neural networks[J]. Symmetry, 2024, 16(8): 952. |
| [20] | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]. European Conference on Computer Vision. Cham: Springer International Publishing, 2020: 213-229. |
| [21] | ZHANG S, CHEN D, YANG J, et al. Guided attention in cnns for occluded pedestrian detection and re-identification[J]. International Journal of Computer Vision, 2021, 129: 1875-1892. |
| [22] | ASSEFA A A, TIAN W, ACHEAMPONG K N, et al. Small‐scale and occluded pedestrian detection using multi mapping feature extraction function and modified soft‐nms[J]. Computational Intelligence and Neuroscience, 2022, 2022(1): 9325803. |
| [23] | MA J, WAN H, WANG J, et al. An improved one-stage pedestrian detection method based on multi-scale attention feature extraction[J]. Journal of Real-Time Image Processing, 2021: 1-14. |
| [24] | WANG M, CHEN H, LI Y, et al. Multi‐scale pedestrian detection based on self‐attention and adaptively spatial feature fusion[J]. IET Intelligent Transport Systems, 2021, 15(6): 837-849. |
| [25] | YESHURUN Y. The spatial distribution of attention[J]. Current Opinion in Psychology, 2019, 29: 76-81. |
| [26] | WOO S, PARK J, LEE J Y, et al. Cbam: convolutional block attention module[C]. Proceedings of the European Conference on Computer Vision, 2018: 3-19. |
| [27] | YANG G, WANG Z, ZHUANG S, et al. PFF‐CB: multiscale occlusion pedestrian detection method based on PFF and CBAM[J]. Computational Intelligence and Neuroscience, 2022, 2022(1): 3798060. |
| [28] | LIU M, WAN L, WANG B, et al. SE-YOLOv4: shuffle expansion YOLOv4 for pedestrian detection based on PixelShuffle[J]. Applied Intelligence, 2023, 53(15): 18171-18188. |
| [29] | OUNOUGHI C, YAHIA S B. Data fusion for ITS: a systematic literature review[J]. Information Fusion, 2023, 89: 267-291. |
| [30] | SHAKERI A, MOSHIRI B, GRAKANI H G. Pedestrian detection using image fusion and stereo vision in autonomous vehicles[C]. 2018 9th International Symposium on Telecommunications (IST). IEEE, 2018: 592-596. |
| [31] | WEI W, CHENG L, XIA Y, et al. Occluded pedestrian detection based on depth vision significance in biomimetic binocular[J]. IEEE Sensors Journal, 2019, 19(23): 11469-11474. |
| [32] | ZHAO Y, ZHAO M, SHI F, et al. Light-field imaging for distinguishing fake pedestrians using convolutional neural networks[J]. International Journal of Advanced Robotic Systems, 2021, 18(1): 1729881420987400. |
| [33] | SHABESTARI Z B, HOSSEININAVEH A, REMONDINOI F. Motorcycle detection and collision warning using monocular images from a vehicle[J]. Remote Sensing, 2023, 15(23): 5548. |
| [34] | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023: 7464-7475. |
| [35] | CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986 (6): 679-698. |
| [36] | HARALICK R M, SHANMUGAM K, DINSTEIN I H. Textural features for image classification[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1973 (6): 610-621. |
| [37] | LI J, TANG J, LIU H. Reconstruction-based unsupervised feature selection: an embedded approach[C]. IJCAI, 2017: 2159-2165. |
| [38] | ZHENG Z, WANG P, REN D, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics, 2021, 52(8): 8574-8586. |
| [39] | TONG Z, CHEN Y, XU Z, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism[J]. arXiv preprint arXiv:, 2023. |
| [40] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(6): 1137-1149. |
| [41] | ZHAN W, SUN C, WANG M, et al. An improved Yolov5 real-time detection method for small objects captured by UAV[J]. Soft Computing, 2022, 26: 361-373. |
| [42] | GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021[J]. arXiv preprint arXiv:, 2021. |
| [43] | WANG C Y, YEH I H, LIAO H Y M. You only learn one representation: unified network for multiple tasks[J]. arXiv preprint arXiv:, 2021. |
| [44] | VARGHESE R, SAMBATH M. Yolov8: a novel object detection algorithm with enhanced performance and robustness [C]. 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), 2024. |
| [45] | KHANAM R, HUSSAIN M. Yolov11: an overview of the key architectural enhancements[J].arXiv preprint arXiv: , 2024. |
| [1] | 龚伟,王亚飞,汪博文,李泽星,孙家铭. 基于跨域时空特征匹配的路端3D目标检测无监督学习方法研究[J]. 汽车工程, 2025, 47(9): 1665-1673. |
| [2] | 徐慧智,张建召,蒋贤才,宋成举. 基于MobileViT模型和光流融合的驾驶人行为识别[J]. 汽车工程, 2025, 47(8): 1479-1489. |
| [3] | 朱凌云,王海洋. 基于LiDAR点云特征补全的雪天无人车目标检测[J]. 汽车工程, 2025, 47(6): 1133-1143. |
| [4] | 隆艾岐,冯治国,张振博,田兴强,向巍. 基于轻量级RT-DETR-tiny的车辆目标检测算法[J]. 汽车工程, 2025, 47(6): 1188-1197. |
| [5] | 魏超,随淑鑫,李路兴. 基于极坐标的环视视觉稀疏化时序3D目标检测[J]. 汽车工程, 2025, 47(6): 1198-1206. |
| [6] | 刘宸宇,王海,蔡英凤,陈龙. 面向自动驾驶道路场景的相机与毫米波融合的多目标检测算法[J]. 汽车工程, 2025, 47(5): 829-838. |
| [7] | 张亿鸿,钟铭恩,谭佳威,范康,李正峰. 基于直方图特征蒸馏的密集交通目标检测[J]. 汽车工程, 2025, 47(4): 636-644. |
| [8] | 时培成,戈润帅,Chakir Chadia,董心龙,梁涛年,杨爱喜. PolarDet:基于位置与语义信息加权的极坐标BEV端到端3D目标检测算法[J]. 汽车工程, 2025, 47(3): 430-439. |
| [9] | 索锦辉, 王晓伟, 蒋沛文, 丁驰, 高铭, 边有钢. 基于多粒度关系推理的自动驾驶域自适应视觉目标检测算法[J]. 汽车工程, 2025, 47(2): 201-210. |
| [10] | 张曦,杨颖,陈超君,王春风,杨磊. 增强双流Transformer的柴油发动机剩余寿命预测模型[J]. 汽车工程, 2025, 47(2): 292-300. |
| [11] | 王海,张桂荣,罗彤,邱梦,蔡英凤,陈龙. 面向自动驾驶道路场景中异常案例的多模态数据挖掘算法[J]. 汽车工程, 2024, 46(7): 1239-1248. |
| [12] | 金立生,张洪瑜,郭柏苍. 基于特征增稳的混合固态激光雷达目标检测[J]. 汽车工程, 2024, 46(6): 1015-1024. |
| [13] | 邓云红,赵治国,杨一飞,于勤. ADAS系统视觉与毫米波雷达分布式抗差卡尔曼滤波融合算法[J]. 汽车工程, 2024, 46(5): 805-815. |
| [14] | 程腾,倪昊,张强,王文冲,石琴. 基于虚拟点云的二阶段多模态融合网络[J]. 汽车工程, 2024, 46(2): 222-229. |
| [15] | 刘凉,张滢,史晨阳,赵新华,孟宪明,刘增昌. 铆接铝合金板铆钉失效缺陷检测方法研究[J]. 汽车工程, 2024, 46(2): 366-374. |
|
||