汽车工程 ›› 2025, Vol. 47 ›› Issue (9): 1674-1685.doi: 10.19562/j.chinasae.qcgc.2025.09.004
• • 上一篇
汤白雪1,蔡英凤1( ),陈龙1,王海2,饶中钰1,刘泽1
),陈龙1,王海2,饶中钰1,刘泽1
Baixue Tang1,Yingfeng Cai1(),Long Chen1,Hai Wang2,Zhongyu Rao1,Ze Liu1
摘要:
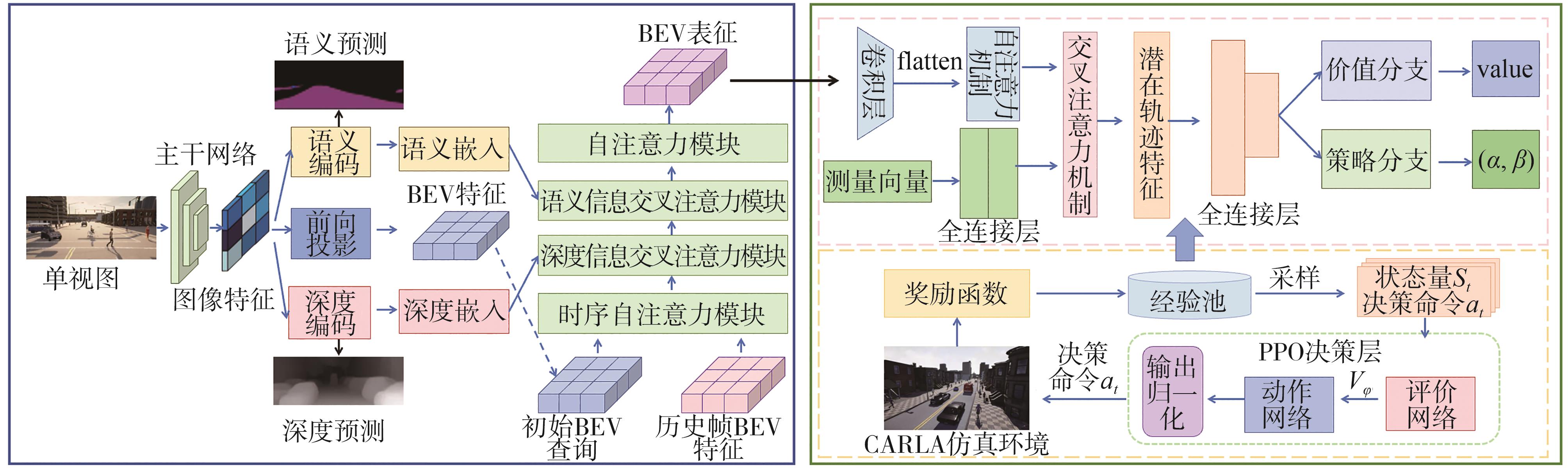
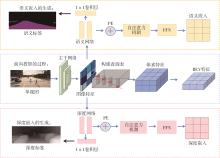
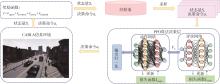
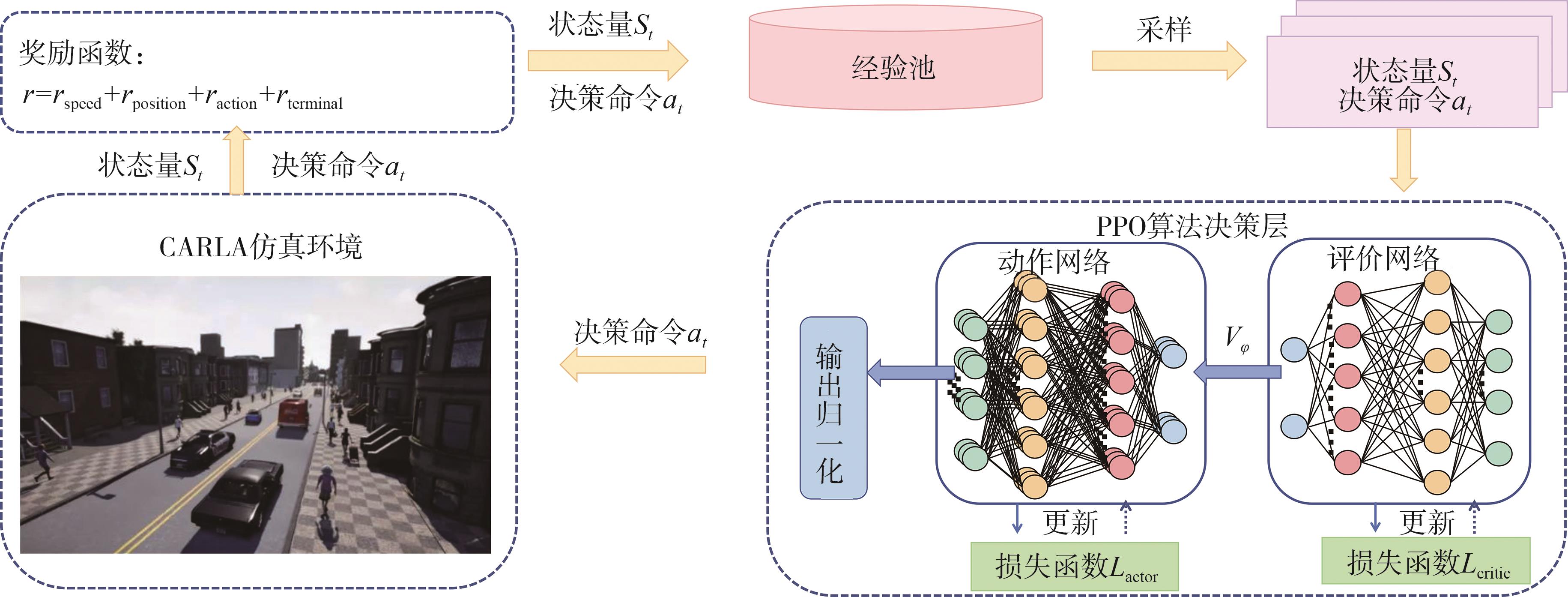
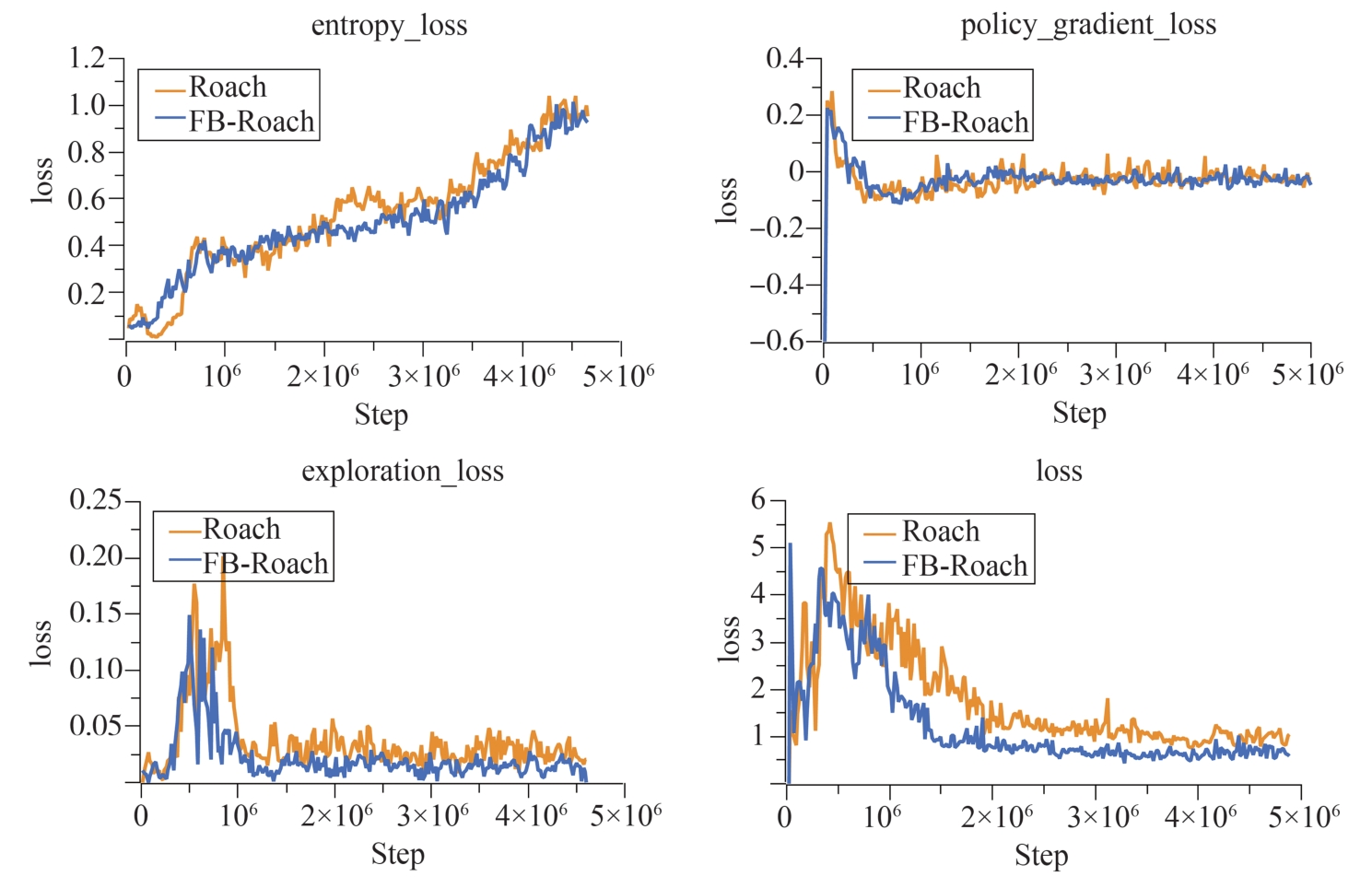
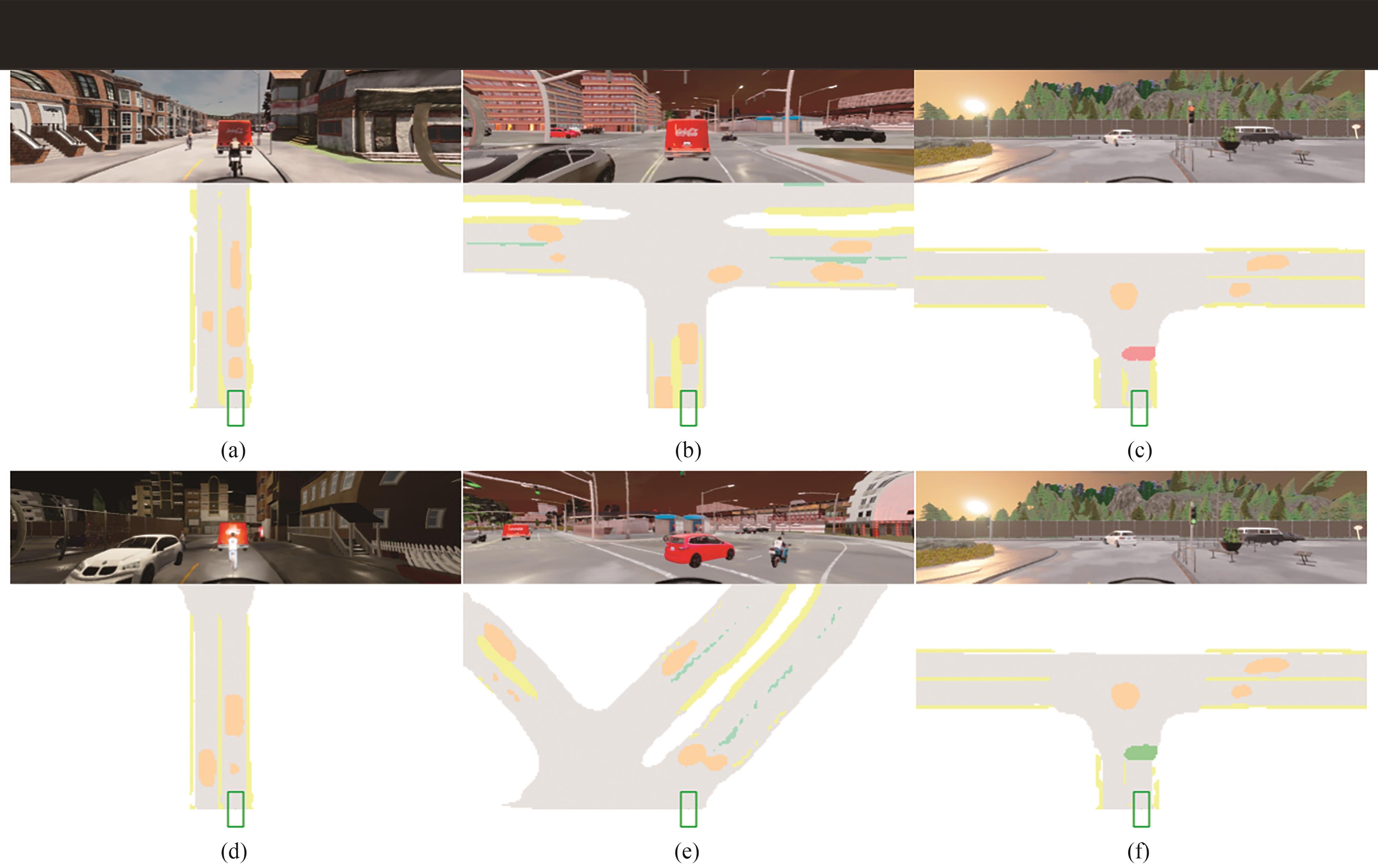
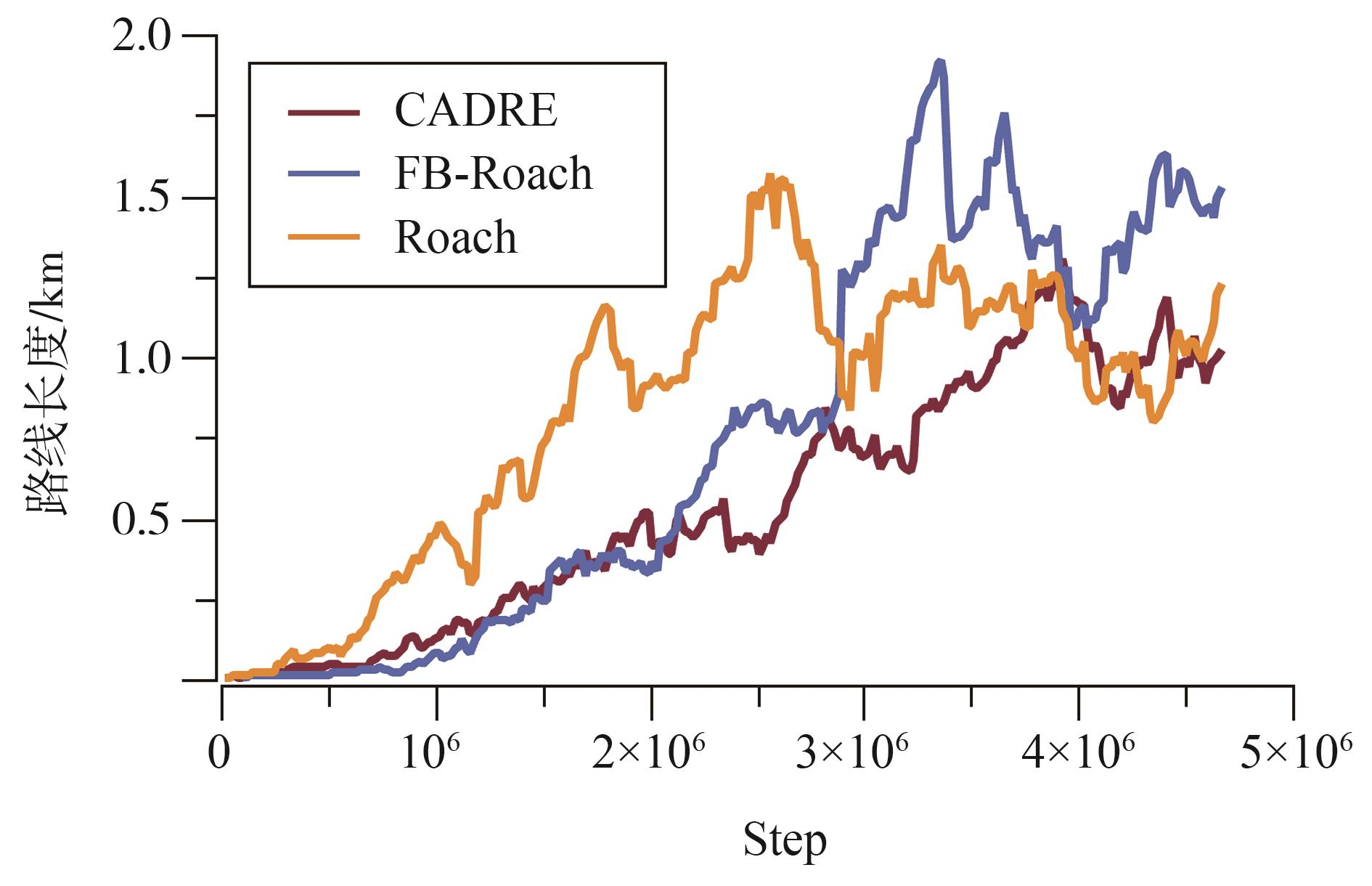
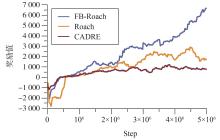
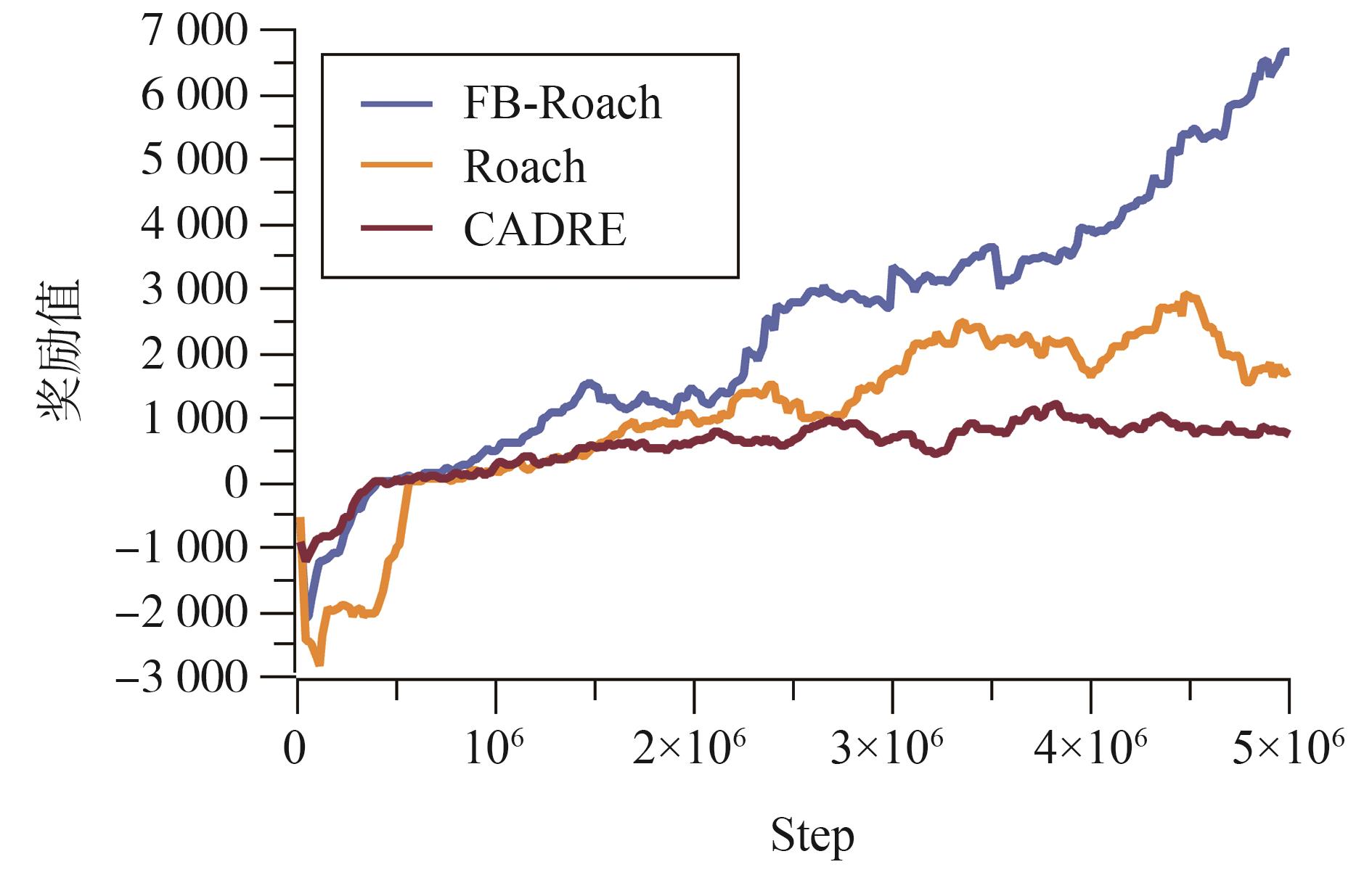
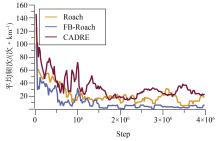
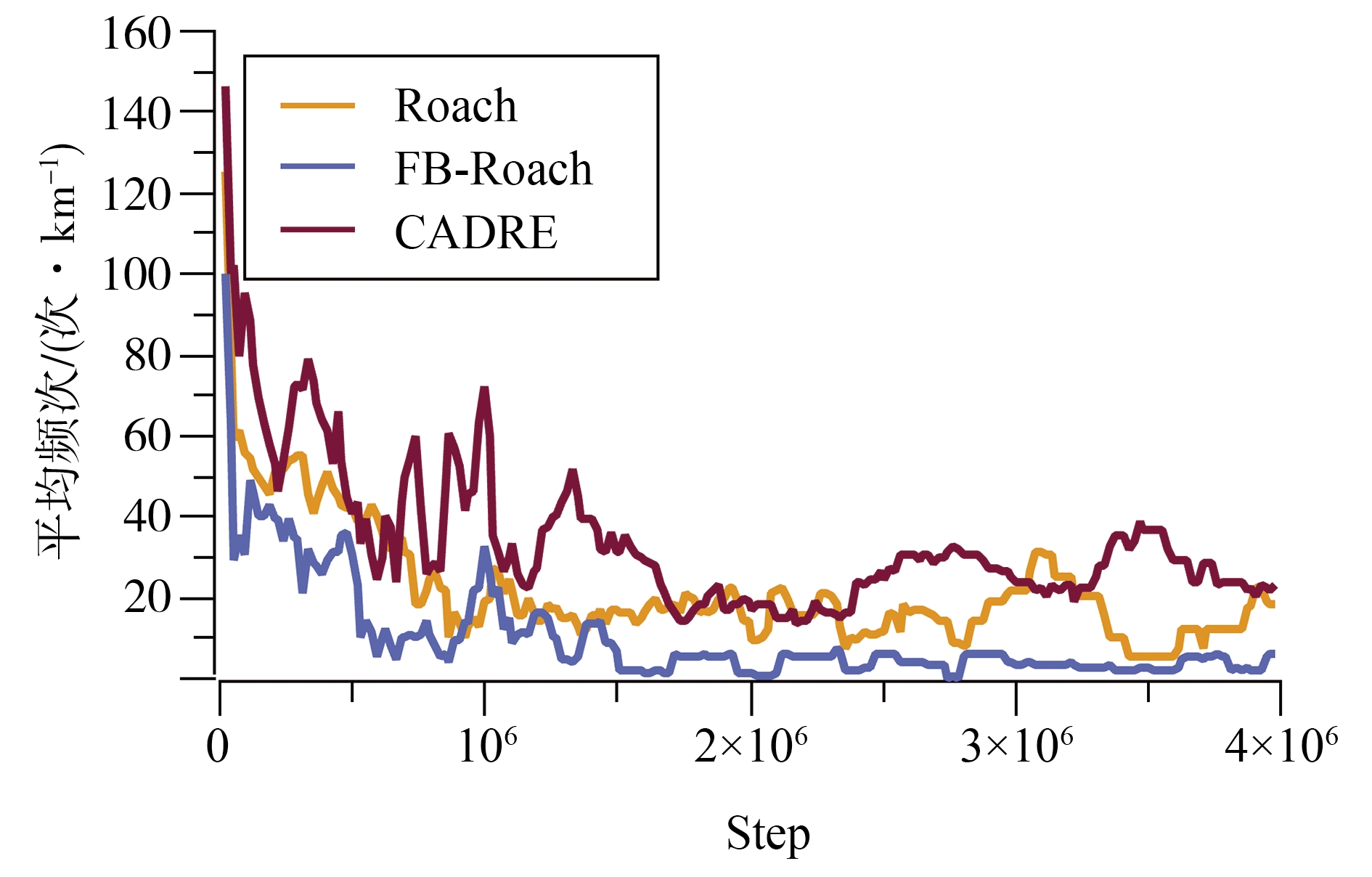
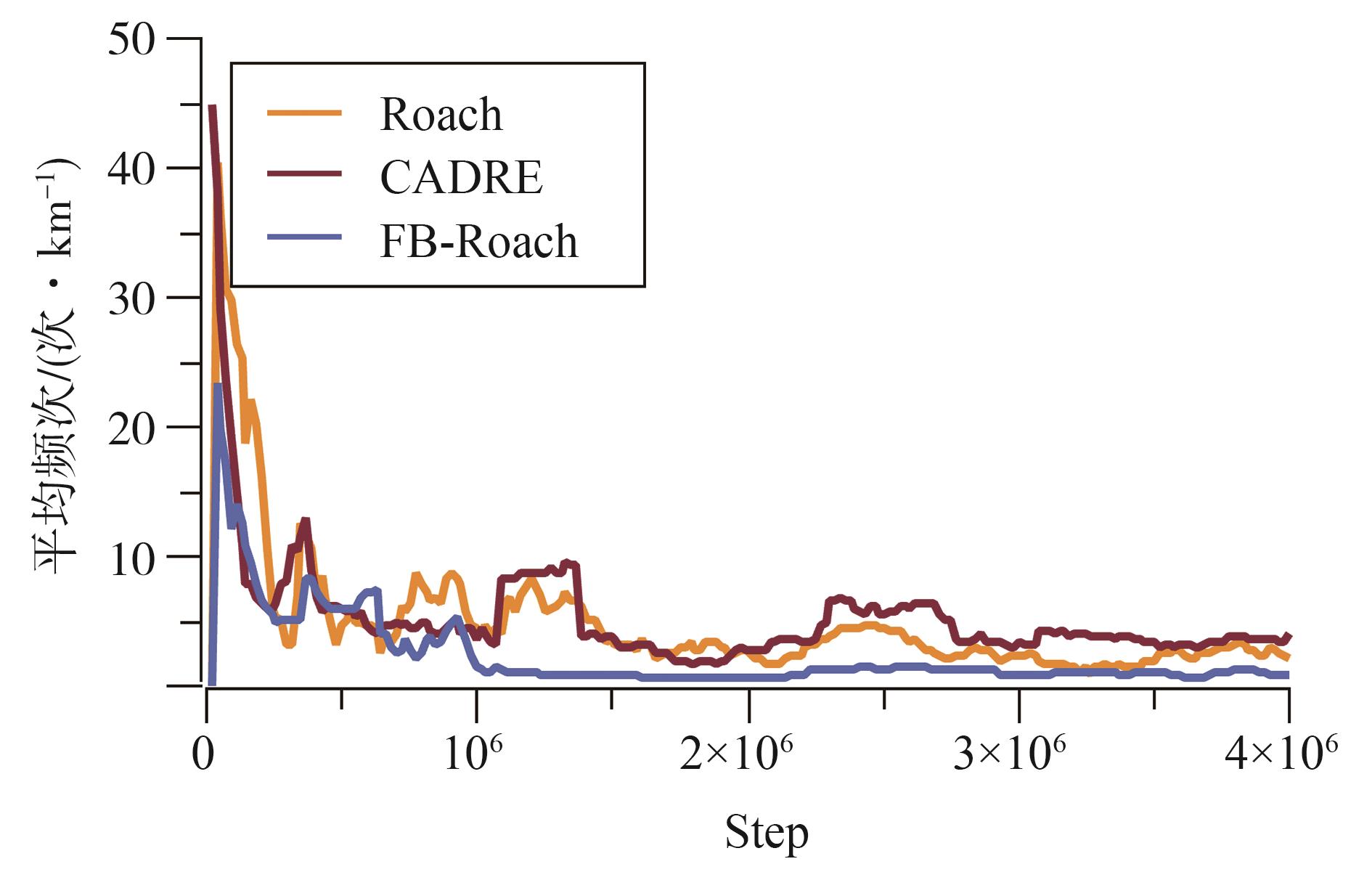
端到端自动驾驶决策规划模型是行业的热点研究方向,传感器信号与动作输出的空间、时序不统一以及端到端模型的收敛问题,极大制约了模型的实际应用效果。为此,本文提出一种融合鸟瞰图预测的端到端强化学习模型FB-Roach,通过鸟瞰图预测模型建立环境信息表征,设计了以静态查询表为核心的前向投影模块,以及融合时序信息、深度嵌入和语义嵌入的多任务后向投影模块,保证输入信号与输出动作的一致性;进一步结合注意力机制创新性地提出一种无循环的深度网络架构,有效融合鸟瞰图和车辆状态信息,并使用强化学习PPO算法优化模型的动作输出,实现自动驾驶车辆的智能决策控制。基于CARLA模拟器,构建了不同基准下多样性的量化评估指标。实验结果表明,所提出算法在模型收敛速度和驾驶决策安全性方面均优于目前主流算法。