汽车工程 ›› 2023, Vol. 45 ›› Issue (9): 1637-1645.doi: 10.19562/j.chinasae.qcgc.2023.09.012
所属专题: 智能网联汽车技术专题-控制2023年
刘卫国1,2( ),项志宇1,刘伟平2,齐道新2,王子旭2
),项志宇1,刘伟平2,齐道新2,王子旭2
Weiguo Liu1,2(),Zhiyu Xiang1,Weiping Liu2,Daoxin Qi2,Zixu Wang2
摘要:
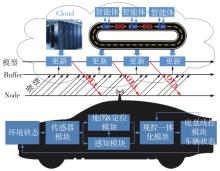
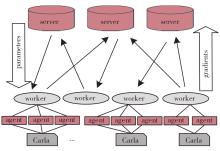
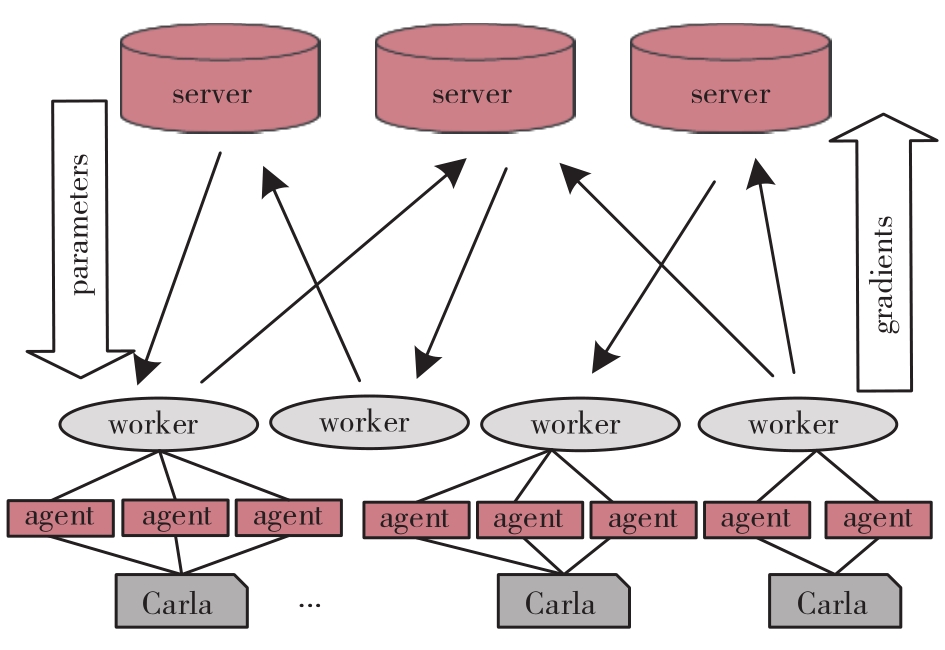
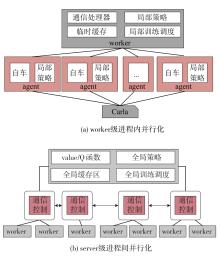
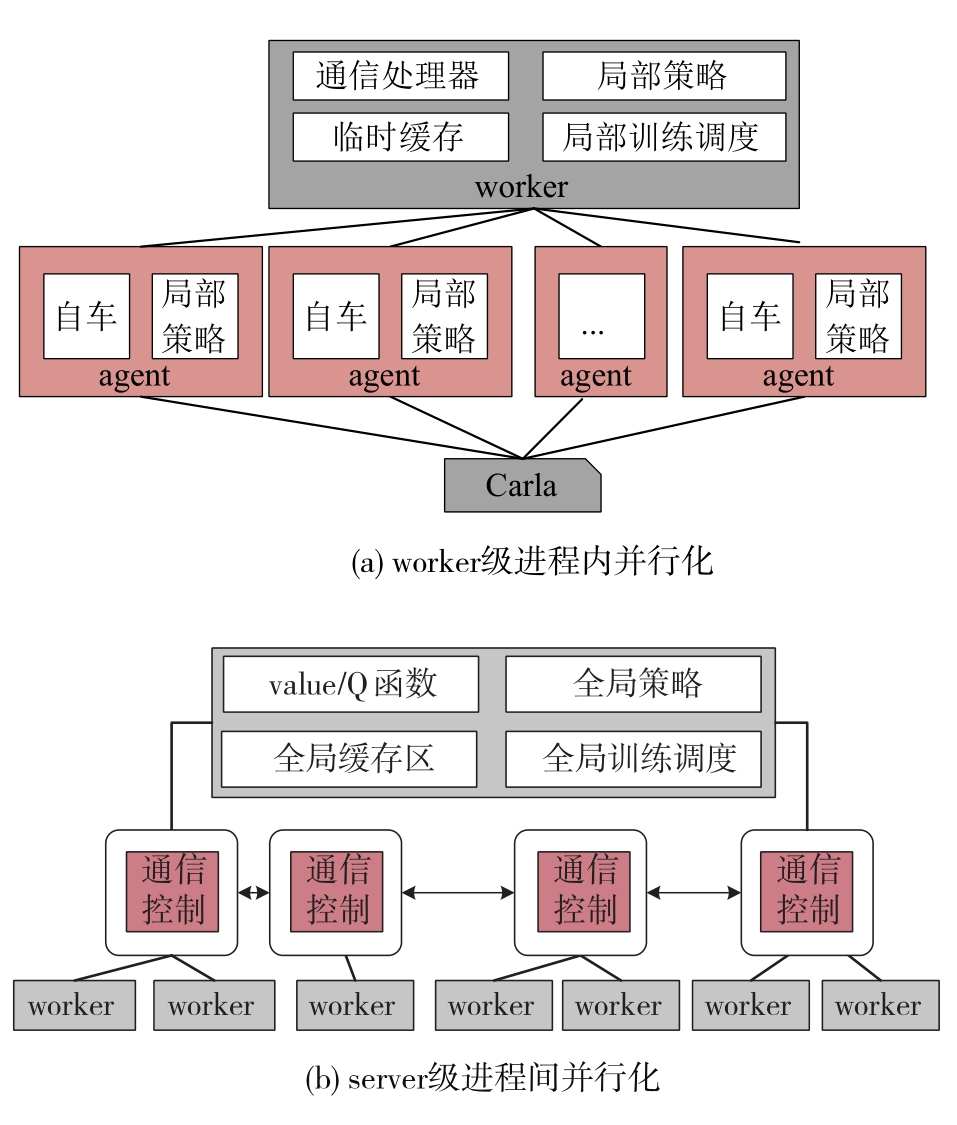
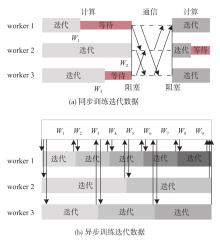
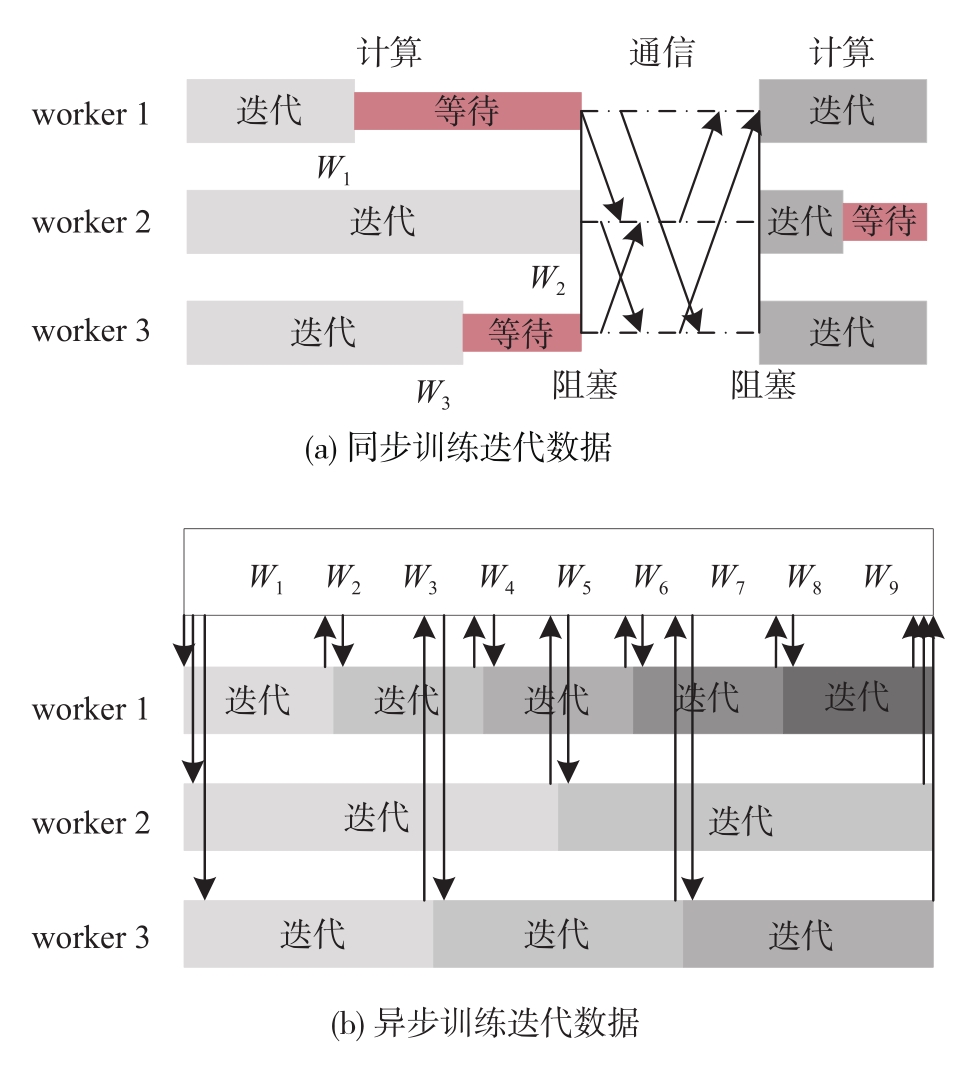
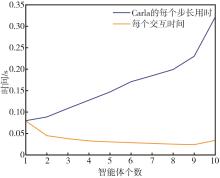
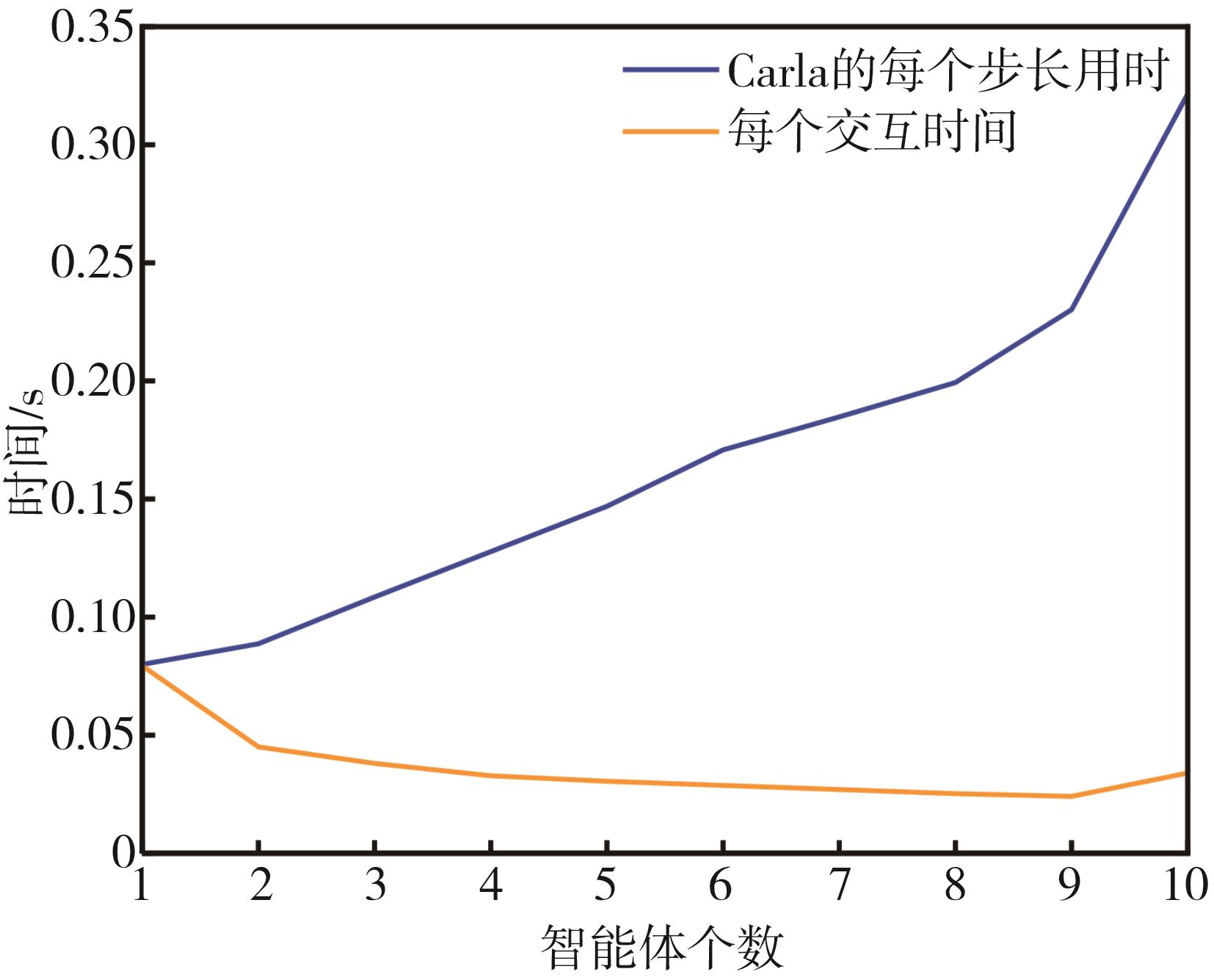
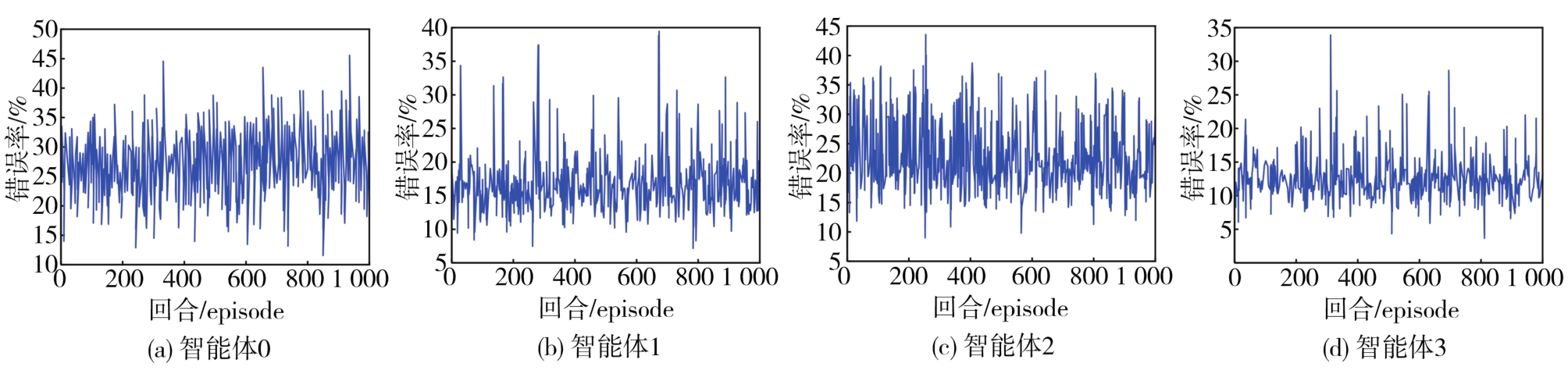
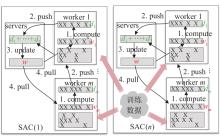
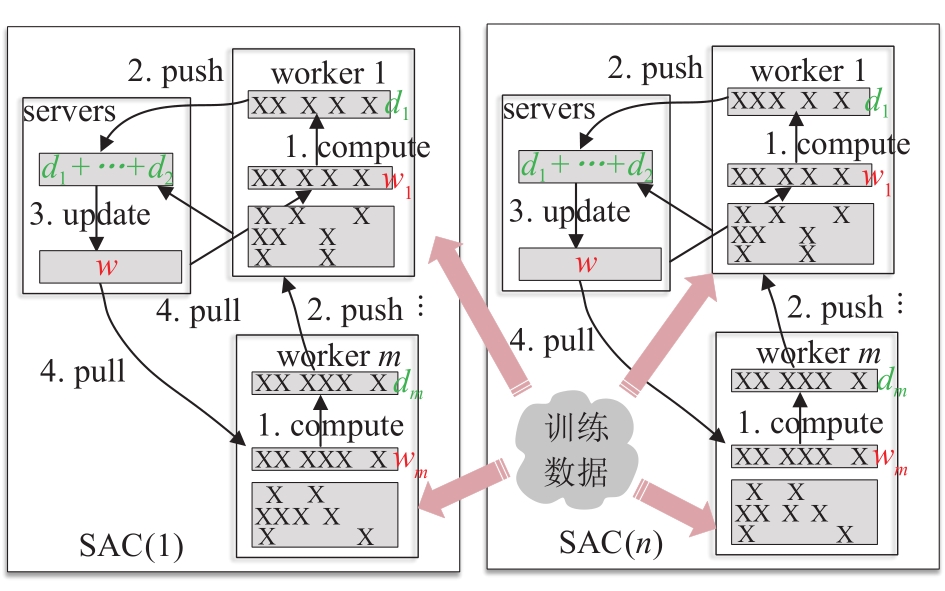
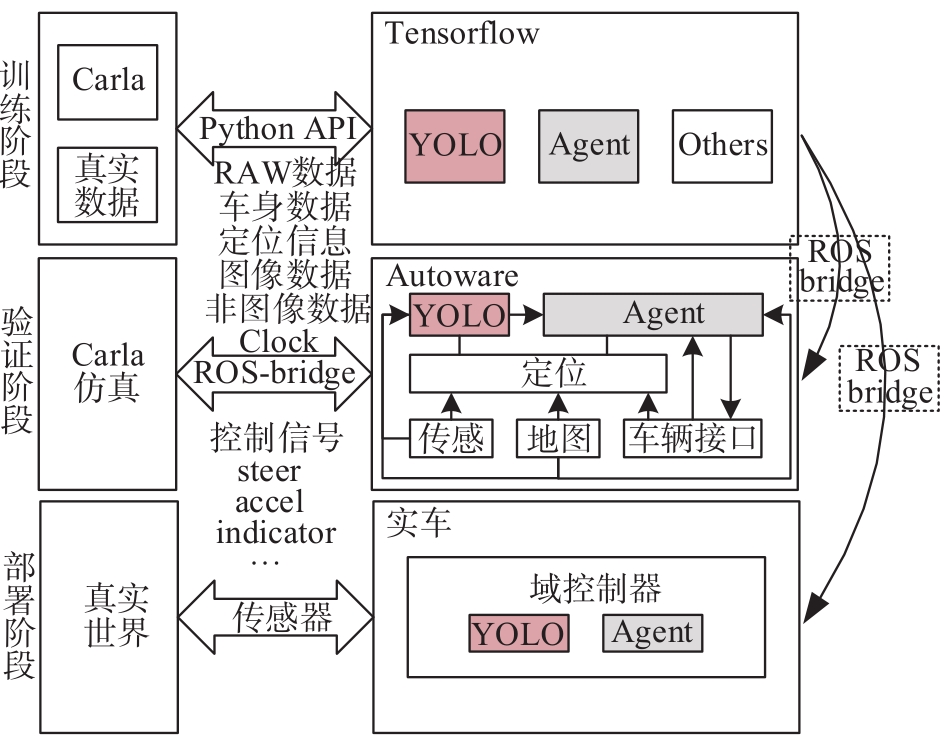
端到端自动驾驶算法的开发现已成为当前自动驾驶技术研发的热点。经典的强化学习算法利用车辆状态、环境反馈等信息训练车辆行驶,通过试错学习获得最佳策略,实现了端到端的自动驾驶算法开发,但仍存在开发效率低下的问题。为解决虚拟仿真环境下训练强化学习算法的低效性和高复杂度问题,本文提出了一种异步分布式强化学习框架,并建立了进程间和进程内的多智能体并行柔性动作-评价(soft actor-critic, SAC)分布式训练框架,加速了Carla模拟器上的在线强化学习训练。同时,为进一步实现模型的快速训练和部署,本文提出了一种基于Cloud-OTA的分布式模型快速训练和部署系统架构,系统框架主要由空中下载技术(over-the-air technology, OTA)平台、云分布式训练平台和车端计算平台组成。在此基础上,本文为了提高模型的可复用性并降低迁移部署成本,搭建了基于ROS的Autoware-Carla集成验证框架。实验结果表明,本文方法与多种主流自动驾驶方法定性相比训练速度更快,能有效地应对密集交通流道路工况,提高了端到端自动驾驶策略对未知场景的适应性,减少在实际环境中进行实验所需的时间和资源。