汽车工程 ›› 2023, Vol. 45 ›› Issue (7): 1112-1122.doi: 10.19562/j.chinasae.qcgc.2023.07.002
所属专题: 智能网联汽车技术专题-感知&HMI&测评2023年
赵东宇,赵树恩( )
)
收稿日期:2022-12-14
修回日期:2023-01-24
出版日期:2023-07-25
发布日期:2023-07-25
通讯作者:
赵树恩
E-mail:zse0916@163.com
基金资助:
Dongyu Zhao,Shuen Zhao()
Received:2022-12-14
Revised:2023-01-24
Online:2023-07-25
Published:2023-07-25
Contact:
Shuen Zhao
E-mail:zse0916@163.com
摘要:
针对图像和原始点云三维目标检测方法中存在特征信息残缺及点云搜索量过大的问题,以截体点网(frustum PointNet, F-PointNet)结构为基础,融合自动驾驶周围场景RGB图像信息与点云信息,提出一种基于级联YOLOv7的三维目标检测算法。首先构建基于YOLOv7的截体估计模型,将RGB图像目标感兴趣区域(region of interest, RoI)纵向扩展到三维空间,然后采用PointNet++对截体内目标点云与背景点云进行分割。最终利用非模态边界估计网络输出目标长宽高、航向等信息,对目标间的自然位置关系进行解释。在KITTI公开数据集上测试结果与消融实验表明,级联YOLOv7模型相较基准网络,推理耗时缩短40 ms/帧,对于在遮挡程度为中等、困难级别的目标检测平均精度值提升了8.77%、9.81%。
赵东宇, 赵树恩. 基于级联YOLOv7的自动驾驶三维目标检测[J]. 汽车工程, 2023, 45(7): 1112-1122.
Dongyu Zhao, Shuen Zhao. Autonomous Driving 3D Object Detection Based on Cascade YOLOv7[J]. Automotive Engineering, 2023, 45(7): 1112-1122.

图1
级联YOLOv7的三维目标检测框架"

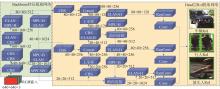
图2
基于YOLOv7的二维RoI提取流程"

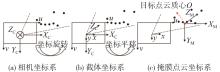
图3
截体估计模型坐标转换"
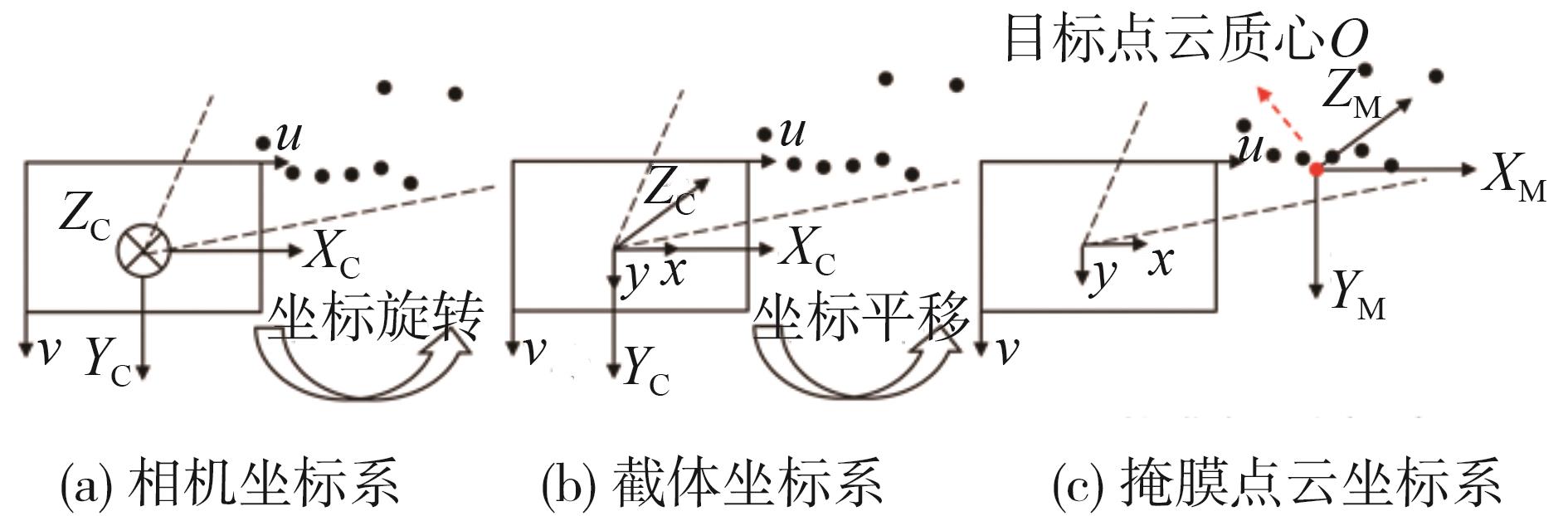
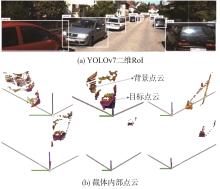
图4
目标点云提取结果"
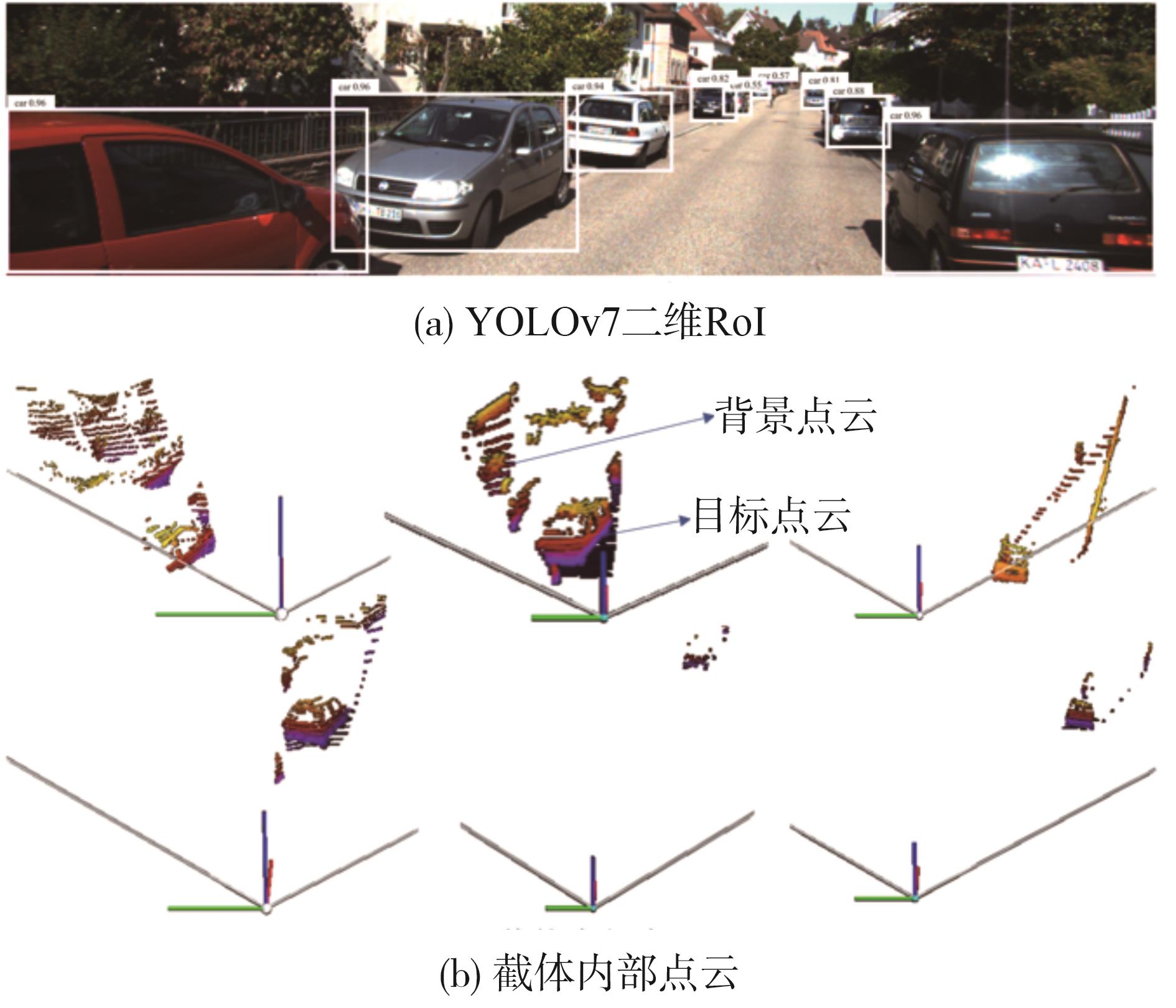
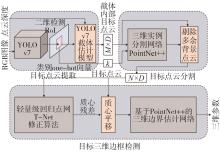
图5
级联YOLOv7的三维目标检测算法架构"
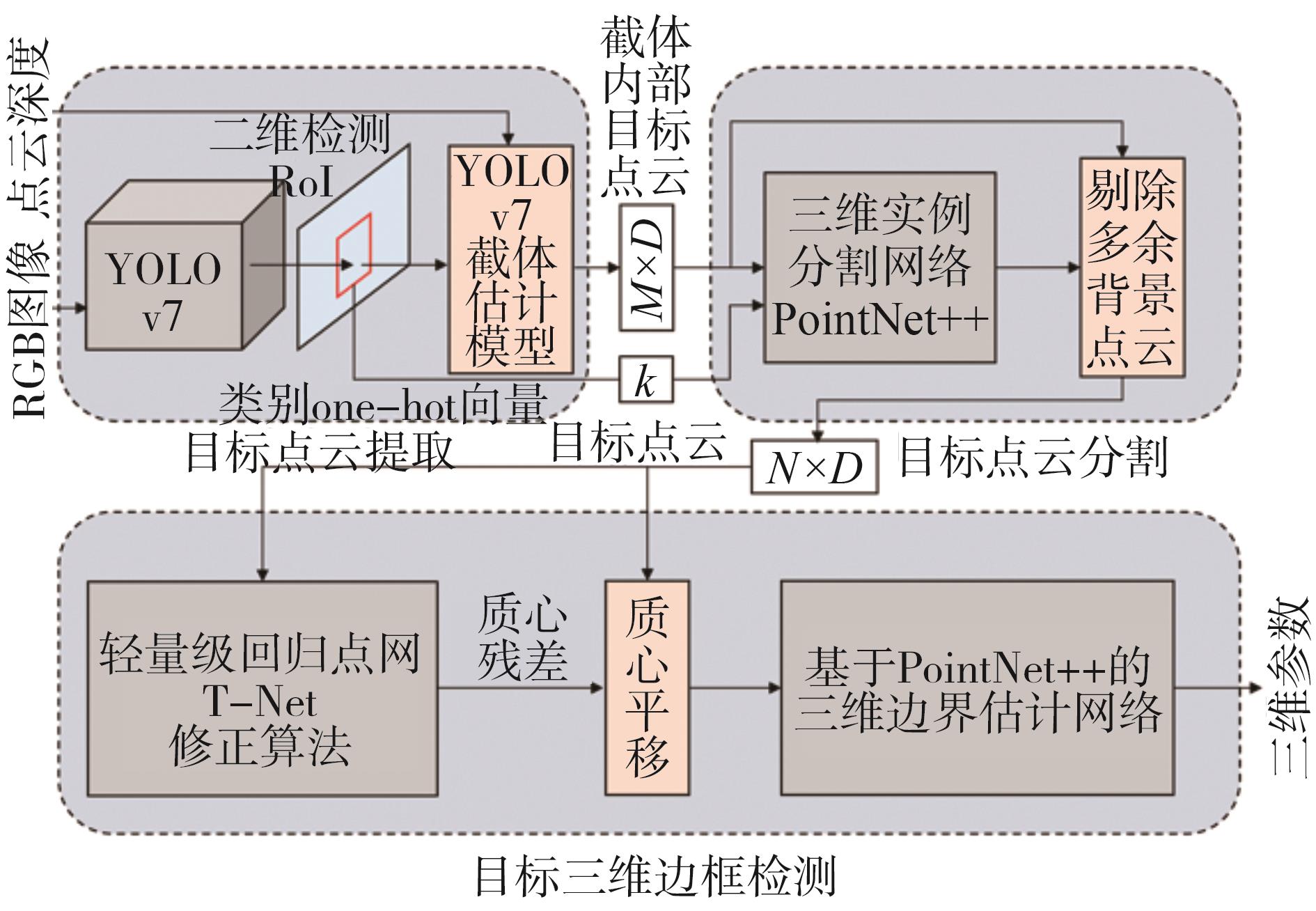
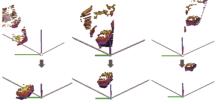
图6
目标点云分割结果"
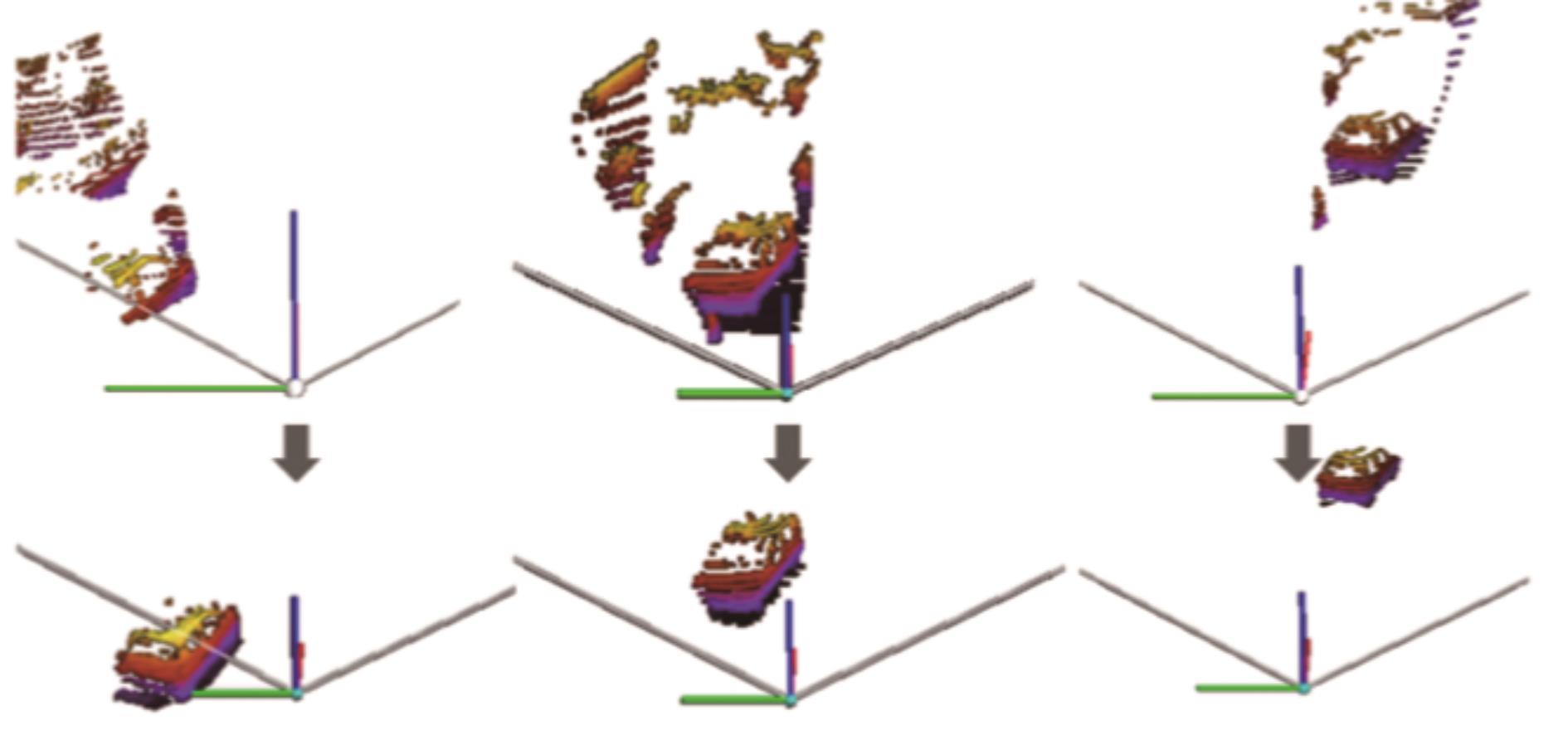
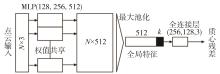
图7
轻量级回归点网T-Net"
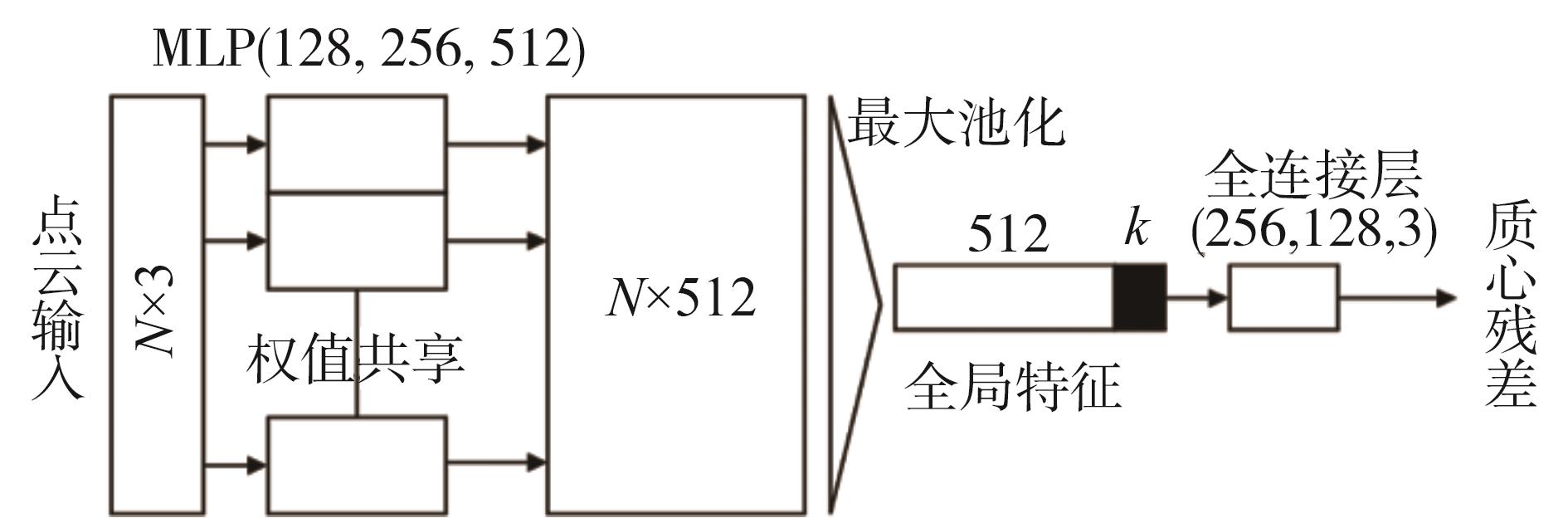
图8
T-Net坐标修正"
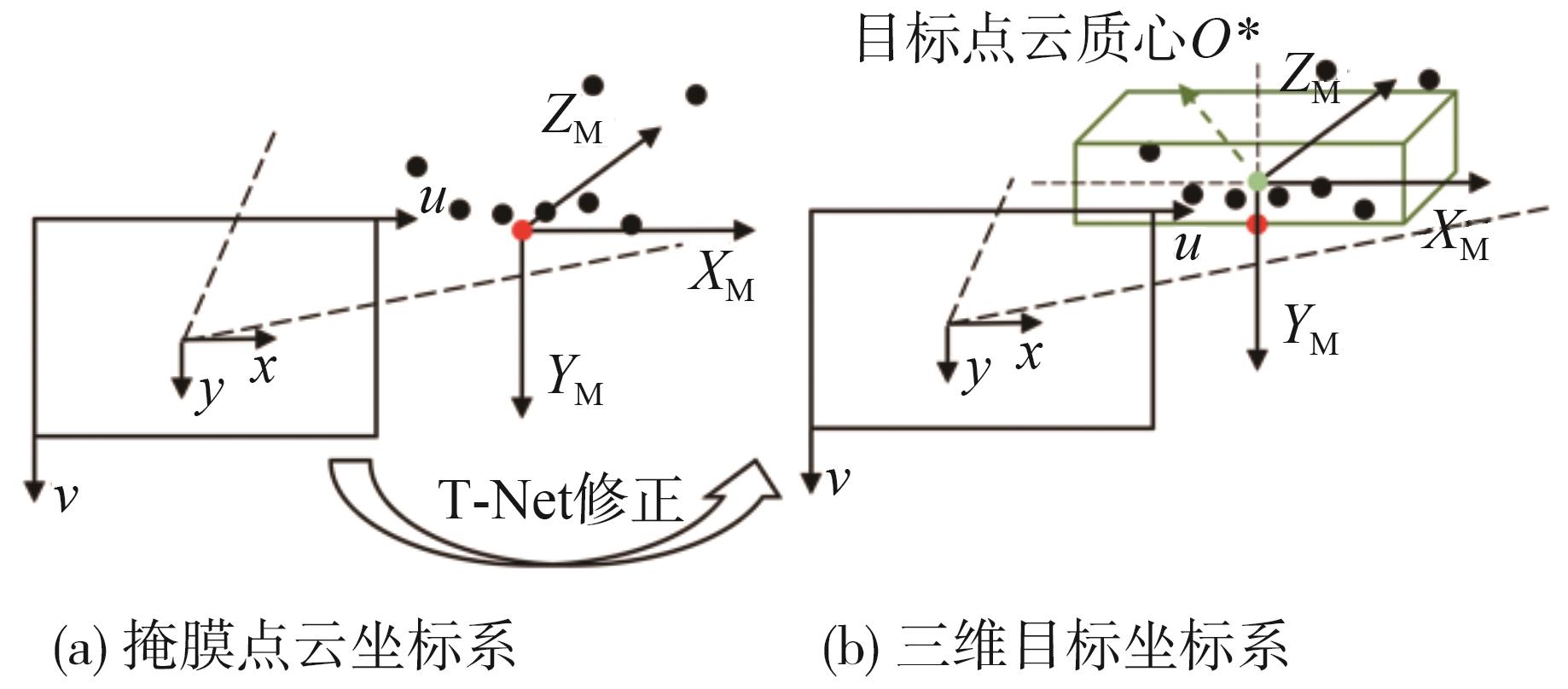
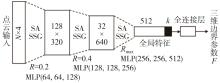
图9
非模态三维边界估计网络"

图10
级联YOLOv7三维检测模型输出过程注:绿色边界为真实边界;白色边界为预测边界。"
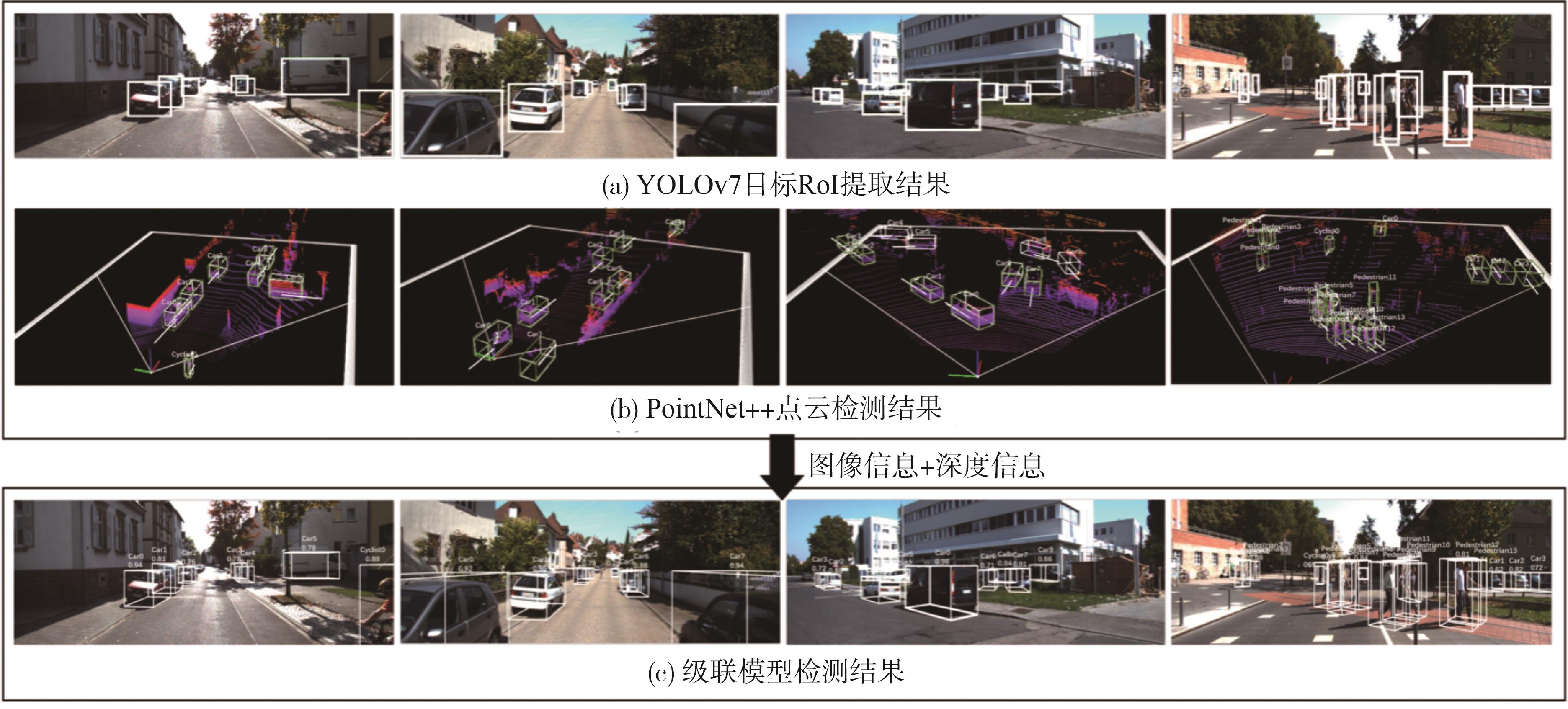

图11
级联模型检测结果P-R曲线"
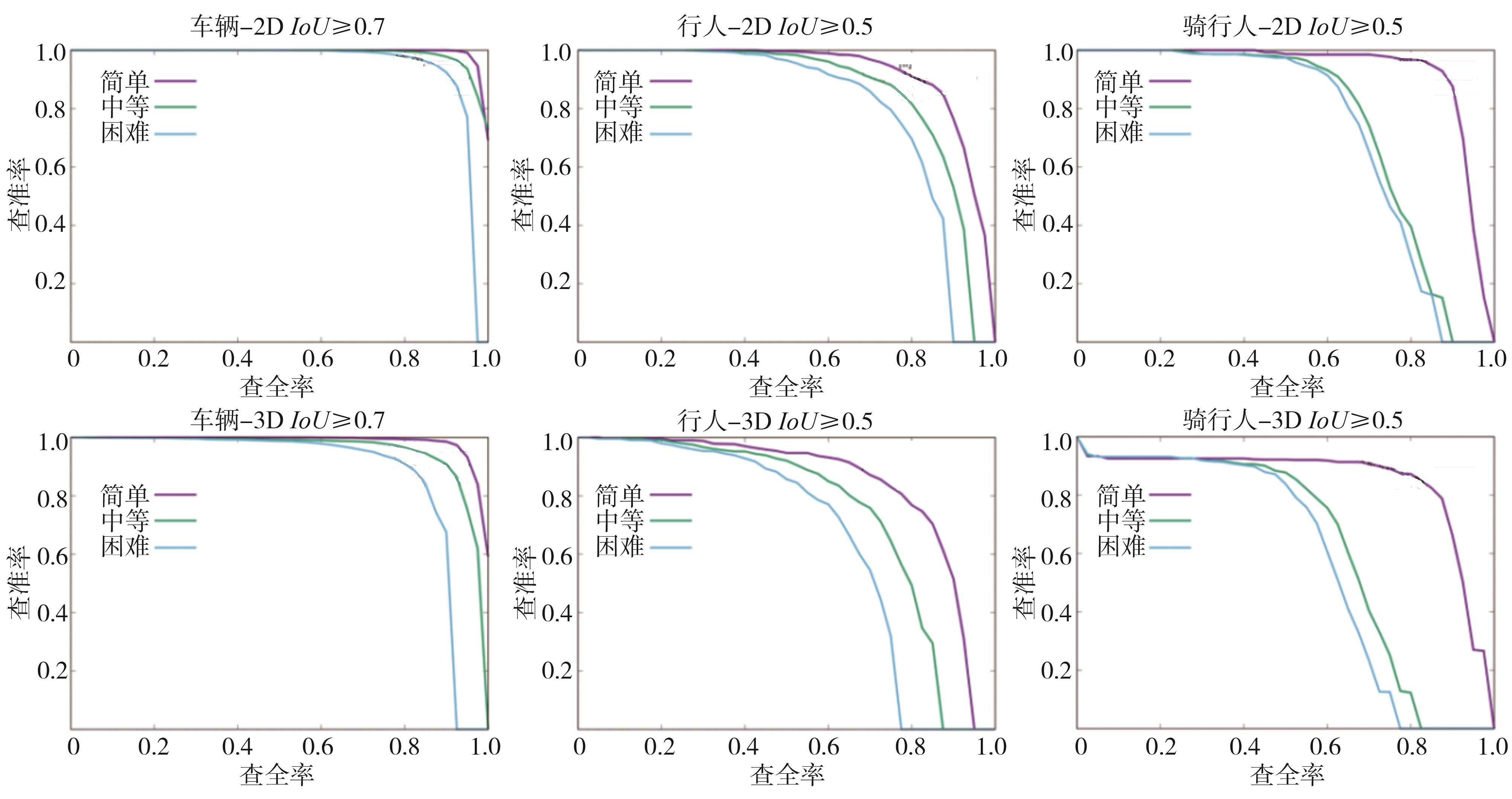
表1
不同算法在KITTI验证集中的三维检测精度"
| 算法 | 图像 | 点云 | 鸟瞰图 | 耗时/(ms·帧-1) | 检测精度AP/% 车辆 IoU≥0.7 行人/骑车人 IoU≥0.5 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 车辆 | 行人 | 骑车人 | |||||||||||
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | |||||
| PointGNN[ | ? | 500 | 87.89 | 78.34 | 77.38 | ||||||||
| Voxelnet[ | ? | 33 | 81.97 | 65.46 | 62.85 | 57.86 | 53.42 | 48.87 | 67.17 | 47.65 | 45.11 | ||
| SECOND[ | ? | 40 | 83.13 | 73.26 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 | ||
| F-PointNet v1 | ? | ? | 66 | 84.33 | 71.38 | 63.43 | 65.83 | 56.16 | 49.61 | 74.22 | 55.99 | 52.61 | |
| F-PointNet v2 | ? | ? | 131 | 85.76 | 71.92 | 63.65 | 70.00 | 61.32 | 53.59 | 77.15 | 56.49 | 53.37 | |
| MV3D[ | ? | ? | 302 | 71.29 | 62.68 | 56.56 | |||||||
| 文献[ | ? | ? | 102 | 83.38 | 74.65 | 63.44 | |||||||
| 文献[ | ? | 45 | 90.29 | 84.61 | 80.34 | ||||||||
| 文献[ | ? | ? | 203 | 82.95 | 67.48 | 64.22 | 58.90 | 55.33 | 50.16 | 68.42 | 48.53 | 46.08 | |
| 文献[ | ? | ? | 93 | 88.27 | 78.53 | 77.75 | |||||||
| 级联模型 | ? | ? | 91 | 92.08 | 84.70 | 81.32 | 76.67 | 69.08 | 60.92 | 76.68 | 62.27 | 57.82 | |
表2
级联模型在KITTI验证集中的消融对比"
| 算法 | 点云分割 网络 | 目标 | 检测精度AP/% | 耗时/ (ms·帧-1) | ||
|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | ||||
级联 模型 | PointNet | 车辆(IoU≥0.7) | 88.21 | 83.60 | 72.58 | 46 |
| 行人(IoU≥0.5) | 74.42 | 67.91 | 58.66 | |||
| 骑车人(IoU≥0.5) | 75.23 | 60.06 | 55.34 | |||
级联 模型 | PointNet++ | 车辆(IoU≥0.7) | 92.08 | 84.70 | 81.32 | 91 |
| 行人(IoU≥0.5) | 76.67 | 69.08 | 60.92 | |||
| 骑车人(IoU≥0.5) | 76.68 | 62.27 | 57.82 | |||
表3
T-Net结构对模型的精度影响"
| 算法结构 | 目标 | 检测精度AP/% | ||
|---|---|---|---|---|
| 简单 | 中等 | 困难 | ||
不引入 T-Net | 车辆(IoU≥0.7) | 90.12 | 82.12 | 78.91 |
| 行人(IoU≥0.5) | 74.22 | 67.34 | 58.66 | |
| 骑车人(IoU≥0.5) | 75.02 | 60.53 | 55.30 | |
引入 T-Net | 车辆(IoU≥0.7) | 92.08 | 84.70 | 81.32 |
| 行人(IoU≥0.5) | 76.67 | 69.08 | 60.92 | |
| 骑车人(IoU≥0.5) | 76.68 | 62.27 | 57.82 | |
表4
二维RoI提取方法消融实验"
| 网络结构 | 分割精度 mAP/% | 检测精度 mAP/% | 分割耗时/(ms·帧-1) | 总耗时/(ms·帧-1) |
|---|---|---|---|---|
| YOLOv5&PointNet++ | 56.82 | 71.71 | 80 | 184 |
| DETR[ | 52.65 | 66.93 | 86 | 408 |
| ConvNeXts[ | 58.93 | 72.68 | 83 | 493 |
| YOLOv7&PointNet++ | 59.35 | 73.51 | 78 | 91 |
表5
不同算法在KITTI验证集中的BEV\AOS检测精度"
| 指标 | 算法 | 车辆IoU≥0.7 | 行人IoU≥0.5 | 骑车人IoU≥0.5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||
| BEV检测精度AP/% | Voxelnet | 89.60 | 84.81 | 78.57 | 65.95 | 61.05 | 56.98 | 74.41 | 52.18 | 50.49 |
| MV3D | 86.55 | 78.10 | 76.67 | |||||||
| SECOND | 89.96 | 87.07 | 79.66 | |||||||
| PointGNN | 89.82 | 88.31 | 87.16 | |||||||
| PointPillars[ | 90.07 | 86.56 | 82.81 | 59.78 | 52.38 | 50.12 | 79.90 | 62.73 | 55.58 | |
| F-PointNe v2 | 88.16 | 84.02 | 76.44 | 72.38 | 66.39 | 59.57 | 81.82 | 60.03 | 56.32 | |
| 级联模型 | 96.22 | 89.75 | 86.81 | 83.22 | 73.87 | 65.49 | 83.19 | 64.41 | 59.81 | |
| 平均航向相似度AOS/% | 3DOP[ | 91.58 | 86.80 | 76.80 | 61.57 | 54.79 | 51.12 | 73.94 | 55.59 | 53.00 |
| Mono3D[ | 91.90 | 86.28 | 77.09 | 62.20 | 55.77 | 51.78 | 71.95 | 53.10 | 51.32 | |
| 文献[ | 87.21 | 81.47 | 74.64 | |||||||
| 级联模型 | 92.21 | 86.24 | 77.28 | 56.35 | 54.85 | 50.60 | 73.24 | 56.84 | 55.58 | |
| 1 | LI B, OUYANG W, SHENG L, et al. Gs3D: an efficient 3D object detection framework for autonomous driving[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2019: 1019-1028. |
| 2 | GIRSHICK R. Fast R-CNN[C]. Proceedings of the IEEE International Conference on Computer Vision. IEEE, 2015: 1440-1448. |
| 3 | LI P, CHEN X, SHEN S. Stereo R-CNN based 3D object detection for autonomous driving[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2019: 7644-7652. |
| 4 | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]. Proceedings of the IEEE International Conference on Computer Vision. IEEE, 2017: 2961-2969. |
| 5 | BEWLEY A, SUN P, MENSINK T, et al. Range conditioned dilated convolutions for scale invariant 3D object detection[J]. arXiv preprint arXiv: , 2020. |
| 6 | 李悄, 李垚辰, 张玉龙, 等. 采用稀疏3D卷积的单阶段点云三维目标检测方法[J]. 西安交通大学学报, 2022, 56(9): 112-122. |
| LI Q, LI Y C, ZHANG Y L, et al. A single-stage point cloud 3D object detection method using sparse 3D convolution[J]. Journal of Xi’an Jiaotong University, 2022, 56(9): 112-122. | |
| 7 | CAESAR H, BANKITI V, LANG A H, et al. Nuscenes: a multimodal dataset for autonomous driving[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2020: 11621-11631. |
| 8 | HU J S K, KUAI T, WASLANDER S L. Point density-aware voxels for lidar 3D object detection[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2022: 8469-8478. |
| 9 | 张名芳, 吴禹峰, 王力,等. 基于金字塔特征融合的二阶段三维点云车辆检测[J]. 交通运输系统工程与信息, 2022, 22(5): 107-116. |
| ZHANG M F, WU Y F, WANG L, et al. Pyramid-feature-fusion-based two stage vehicle detection via 3D point cloud[J]. Journal of Transportation Systems Engineering and Information Technology, 2022, 22(5): 107-116. | |
| 10 | SHI S, WANG X, LI H. PointRCNN: 3D object proposal generation and detection from point cloud[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2019: 770-779. |
| 11 | QI C R, SU H, MO K, et al. Pointnet: deep learning on point sets for 3D classification and segmentation[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2017: 652-660. |
| 12 | QI C R, YI L, SU H, et al. Pointnet++: deep hierarchical feature learning on point sets in a metric space[J]. arXiv preprint arXiv: , 2017. |
| 13 | YANG Z, SUN Y, LIU S, et al. 3DSSD: point-based 3D single stage object detector[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2020: 11040-11048. |
| 14 | 谢德胜, 徐友春, 陆峰, 等. 基于多传感器信息融合的3维目标实时检测[J]. 汽车工程, 2022, 44(3): 340-349. |
| XIE D X, XU Y C, LU F, et al. Real-time detection of 3D objects based on multi-sensor information fusion[J]. Automotive Engineering, 2022, 44(3): 340-349. | |
| 15 | WU X, PENG L, YANG H, et al. Sparse fuse dense: towards high quality 3D detection with depth completion[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2022: 5418-5427. |
| 16 | 徐晨, 倪蓉蓉, 赵耀. 融合稀疏点云补全的3D目标检测算法[J]. 图学学报, 2021, 42(1): 37-43. |
| XU C, NI R R, ZHAO Y. 3D object detection algorithm combined with sparse point cloud completion[J]. Journal of Graphics, 2021, 42(1): 37-43. | |
| 17 | QI C R, LIU W, WU C, et al. Frustum pointnets for 3D object detection from rgb-d data[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 918-927. |
| 18 | 张旭豪. 面向动车场景的三维目标检测[D]. 成都: 电子科技大学, 2022. |
| ZHANG X H. 3D object detection in electric multiple units scene[D]. Chengdu: University of Electronic Science and Technology of China, 2022. | |
| 19 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[J]. arXiv preprint arXiv: , 2022. |
| 20 | SHI W, RAJKUMAR R. Point-GNN: graph neural network for 3D object detection in a point cloud[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1711-1719. |
| 21 | ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 4490-4499. |
| 22 | CHEN X, MA H, WAN J, et al. Multi-view 3D object detection network for autonomous driving[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2017: 1907-1915. |
| 23 | 刘通, 高思洁, 聂为之. 基于多模态信息融合的多目标检测算法[J]. 激光与光电子学进展, 2022, 59(8): 339-348. |
| LIU T, GAO S J, NIE W Z. Multitarget detection algorithm based on multimodal information fusion[J]. Laser and Optoelectronics Progress, 2022, 59(8): 339-348. | |
| 24 | XIE L, XIANG C, YU Z X, et al. PI-RCNN: an efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module[J]. Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, 2020, 34(7): 12460-12467. |
| 25 | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]. European Conference on Computer Vision. Springer. Cham, 2020: 213-229. |
| 26 | LIU Z, MAO H Z, WU C Y, et al. A ConvNet for the 2020s[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2022: 11976-11986. |
| 27 | LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2019: 12697-12705. |
| 28 | CHEN X, KUNDU K, ZHU Y, et al. 3D object proposals for accurate object class detection[C]. International Conference on Neural Information Processing Systems. MIT Press, 2015. |
| 29 | CHEN X, KUNDU K, ZHANG Z, et al. Monocular 3D object detection for autonomous driving[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2016: 2147-2156. |
| [1] | 付新科,蔡英凤,陈龙,王海,刘擎超. 不确定性环境下的自动驾驶汽车行为决策方法[J]. 汽车工程, 2024, 46(2): 211-221. |
| [2] | 赵晓聪,房世玉,李子睿,孙剑. 社会性驾驶交互关键效用析取与应用[J]. 汽车工程, 2024, 46(2): 230-240. |
| [3] | 马艳丽, 秦钦, 董方琦, 娄艺苧. 基于风险场的不同认知次任务下接管风险评估模型[J]. 汽车工程, 2024, 46(1): 9-17. |
| [4] | 刘卫国,项志宇,刘伟平,齐道新,王子旭. 基于分布式强化学习的车辆控制算法研究[J]. 汽车工程, 2023, 45(9): 1637-1645. |
| [5] | 王明,唐小林,杨凯,李国法,胡晓松. 考虑预测风险的自动驾驶车辆运动规划方法[J]. 汽车工程, 2023, 45(8): 1362-1372. |
| [6] | 朱向雷,吴志新,张宇飞,赵帅,李克秋,孙博华. 基于场景降维及采样方法的场景库优化方法研究[J]. 汽车工程, 2023, 45(8): 1408-1416. |
| [7] | 吴新政,邢星宇,刘力豪,沈勇,陈君毅. 基于错误注入的决策规划系统抗扰性测试与分析[J]. 汽车工程, 2023, 45(8): 1428-1437. |
| [8] | 高锋,冯德福,胡秋霞. 面向NMPC运动规划系统的数值优化加速技术[J]. 汽车工程, 2023, 45(8): 1438-1447. |
| [9] | 芦涛,金馨,廖毅霏,黄圣杰,杨依琳,谢国涛,秦晓辉. 基于雅克比域零空间边缘化的视觉SLAM[J]. 汽车工程, 2023, 45(8): 1457-1467. |
| [10] | 伍文广,田双岳,张志勇,张斌. 非铺装道路凹凸不平特征语义分割方法研究[J]. 汽车工程, 2023, 45(8): 1468-1478. |
| [11] | 林程, 汪博文, 吕沛原, 宫新乐, 于潇. 面向变曲率道路的自动驾驶汽车换道博弈运动规划与协同控制研究[J]. 汽车工程, 2023, 45(7): 1099-1111. |
| [12] | 李军, 周伟, 唐爽. 基于自适应拟合的智能车换道避障轨迹规划[J]. 汽车工程, 2023, 45(7): 1174-1183. |
| [13] | 赵嘉豪,齐志权,齐智峰,王皓,何磊. 基于轮胎特征点的并行大型车辆朝向角计算[J]. 汽车工程, 2023, 45(6): 1031-1039. |
| [14] | 金立生,韩广德,谢宪毅,郭柏苍,刘国峰,朱文涛. 基于强化学习的自动驾驶决策研究综述[J]. 汽车工程, 2023, 45(4): 527-540. |
| [15] | 陈妍妍,王海,蔡英凤,陈龙,李祎承. 基于检测的高效自动驾驶实例分割方法[J]. 汽车工程, 2023, 45(4): 541-550. |
|