汽车工程 ›› 2023, Vol. 45 ›› Issue (10): 1791-1802.doi: 10.19562/j.chinasae.qcgc.2023.10.002
所属专题: 智能网联汽车技术专题-控制2023年
李捷1,吴晓东1( ),许敏1,刘永刚2
),许敏1,刘永刚2
收稿日期:2023-02-28
修回日期:2023-03-28
出版日期:2023-10-25
发布日期:2023-10-23
通讯作者:
吴晓东
E-mail:xiaodongwu@sjtu.edu.cn
基金资助:
Jie Li1,Xiaodong Wu1(),Min Xu1,Yonggang Liu2
Received:2023-02-28
Revised:2023-03-28
Online:2023-10-25
Published:2023-10-23
Contact:
Xiaodong Wu
E-mail:xiaodongwu@sjtu.edu.cn
摘要:
为了提高智能网联汽车在复杂城市交通环境下的乘坐体验,本文提出一种基于深度强化学习的考虑驾驶安全、能耗经济性、舒适性和行驶效率的多目标生态驾驶策略。首先,基于马尔可夫决策过程构造了生态驾驶策略的状态空间、动作空间与多目标奖励函数。其次,设计了跟车安全模型与交通灯安全模型,为生态驾驶策略给出安全速度建议。第三,提出了融合安全约束与塑形函数的复合多目标奖励函数设计方法,保证强化学习智能体训练收敛和优化性能。最后,通过硬件在环实验验证所提方法的有效性。结果表明,所提策略可以在真实的车载控制器中实时应用。与基于智能驾驶员模型的生态驾驶策略相比,所提策略在满足驾驶安全约束的前提下,改善了车辆的能源经济性、乘坐舒适性和出行效率。
李捷,吴晓东,许敏,刘永刚. 基于强化学习的城市场景多目标生态驾驶策略[J]. 汽车工程, 2023, 45(10): 1791-1802.
Jie Li,Xiaodong Wu,Min Xu,Yonggang Liu. Reinforcement Learning Based Multi-objective Eco-driving Strategy in Urban Scenarios[J]. Automotive Engineering, 2023, 45(10): 1791-1802.
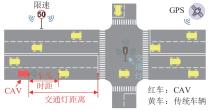
图1
智能网联场景示意图"
图2
基于深度强化学习的生态驾驶策略框架"
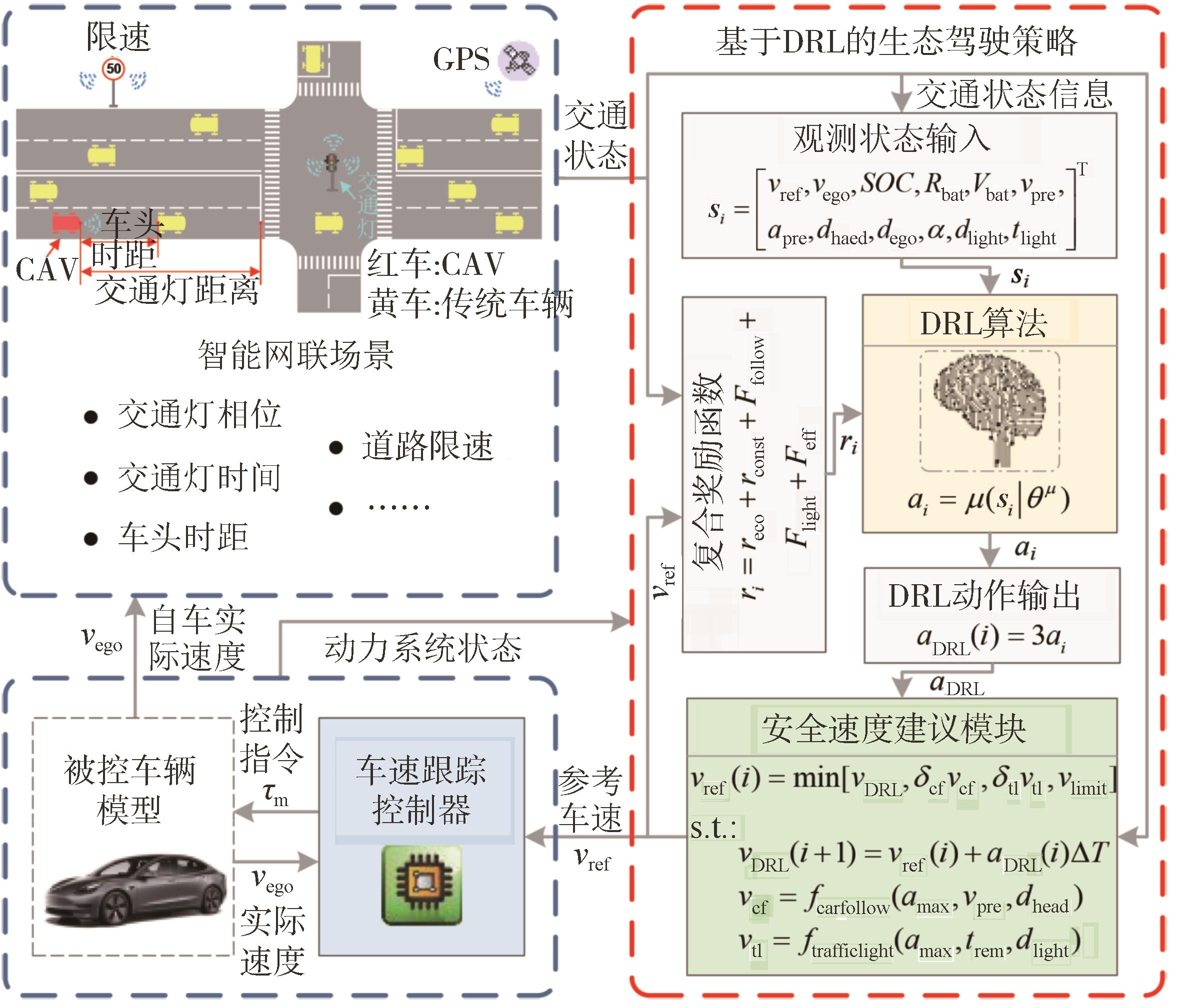
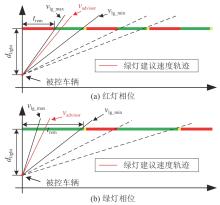
图3
绿灯通行建议速度计算示意图"
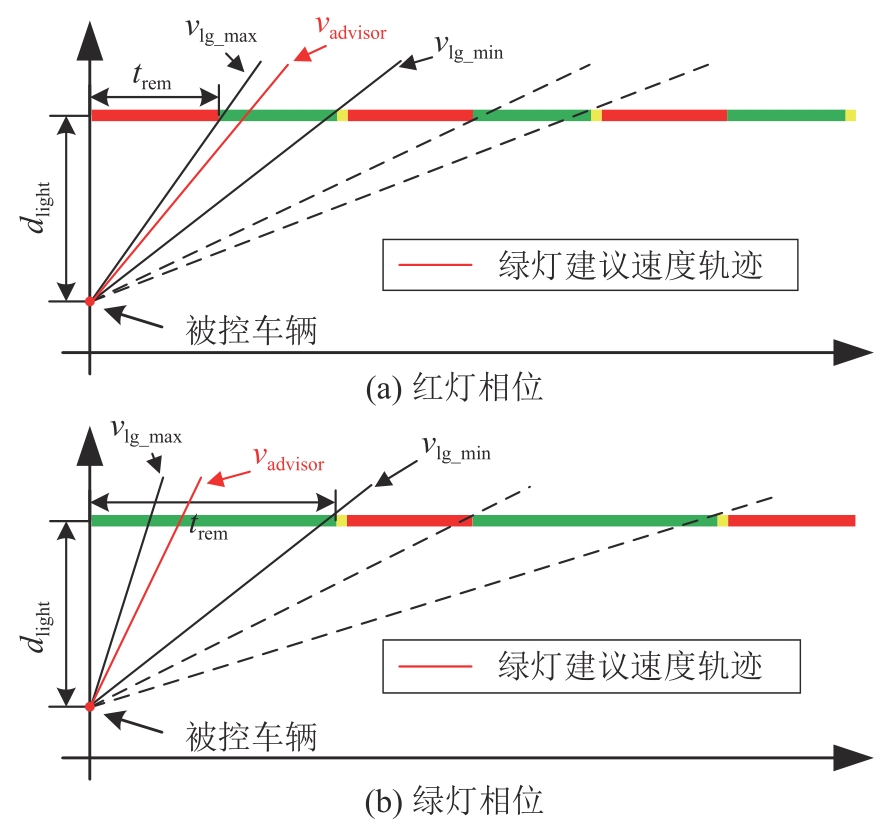
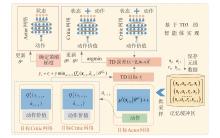
图4
基于TD3的生态驾驶智能体实现"
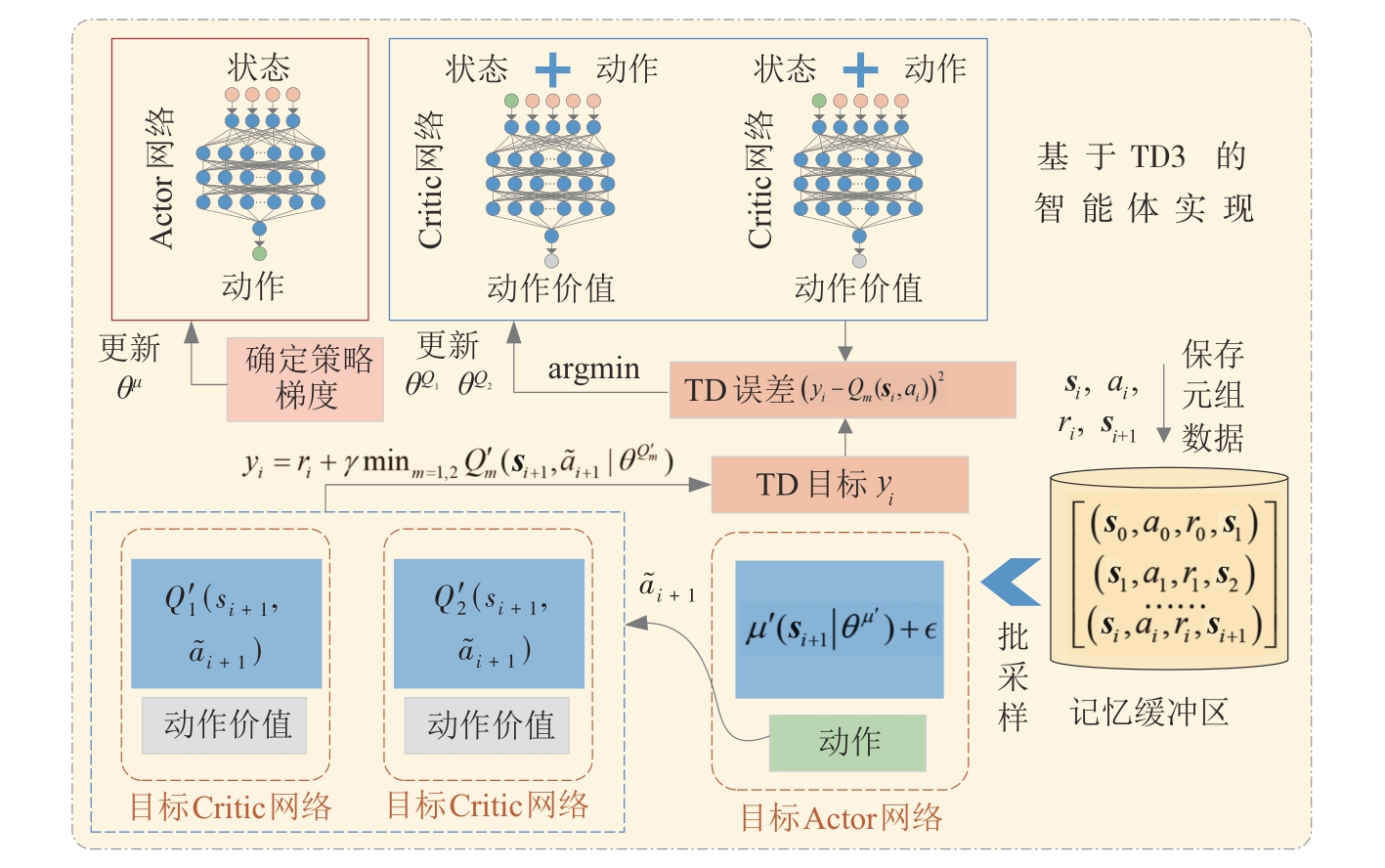
表1
TD3智能体超参数与网络结构"
| 超参数 | 数值 | |||
|---|---|---|---|---|
| 记忆缓冲区容量 | 221 | |||
| 高斯探索噪声标准差 | 0.8 | |||
| 批采样大小 | 256 | |||
| 折扣因子 | 0.99 | |||
| Actor网络学习率 | 0.000 1 | |||
| Critic网络学习率 | 0.000 15 | |||
| 目标网络更新率 | 0.005 | |||
| Critic网络更新噪声标准差 | 0.2 | |||
| 策略更新延迟的频率 | 4 | |||
| Critic网络更新噪声范围 | 0.5 | |||
| 网络结构 | Actor网络 | Critic网络1和2 | ||
| 节点 | 激活函数 | 节点 | 激活函数 | |
| 输入层 | 12 | ReLU | 13 | ReLU |
| 隐藏层 | 128 | 128 | ||
| 隐藏层 | 128 | 128 | ||
| 隐藏层 | 128 | 128 | ||
| 隐藏层 | 64 | 64 | ||
| 隐藏层 | 64 | 64 | ||
| 输出层 | 1 | tanh | 1 | |

图5
底层车速跟踪控制框架"
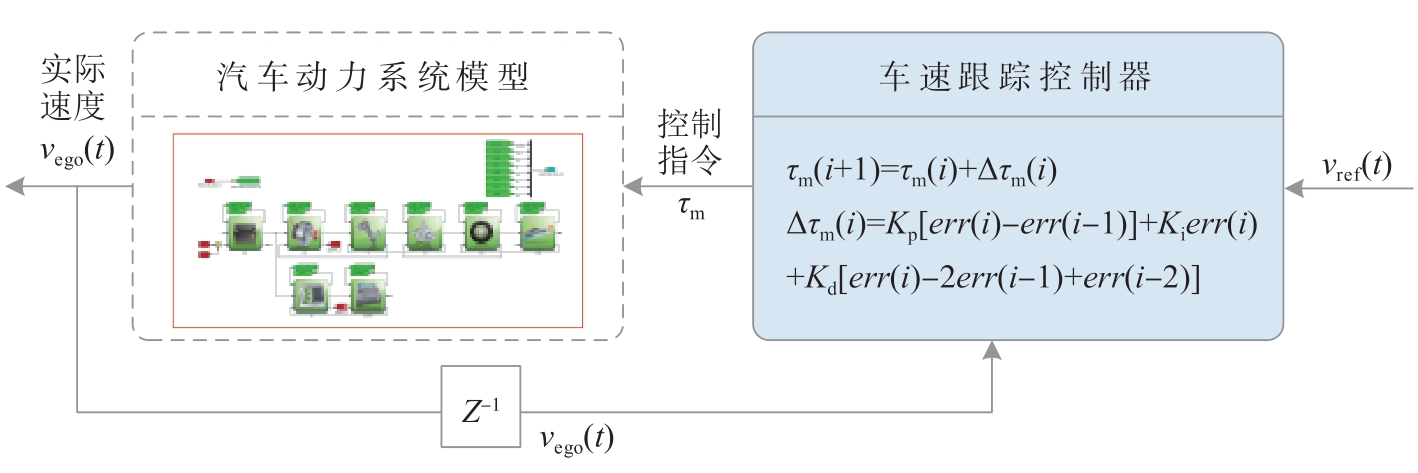
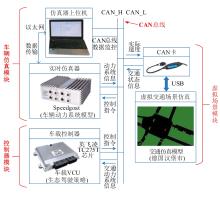
图6
HIL实验平台原理图"
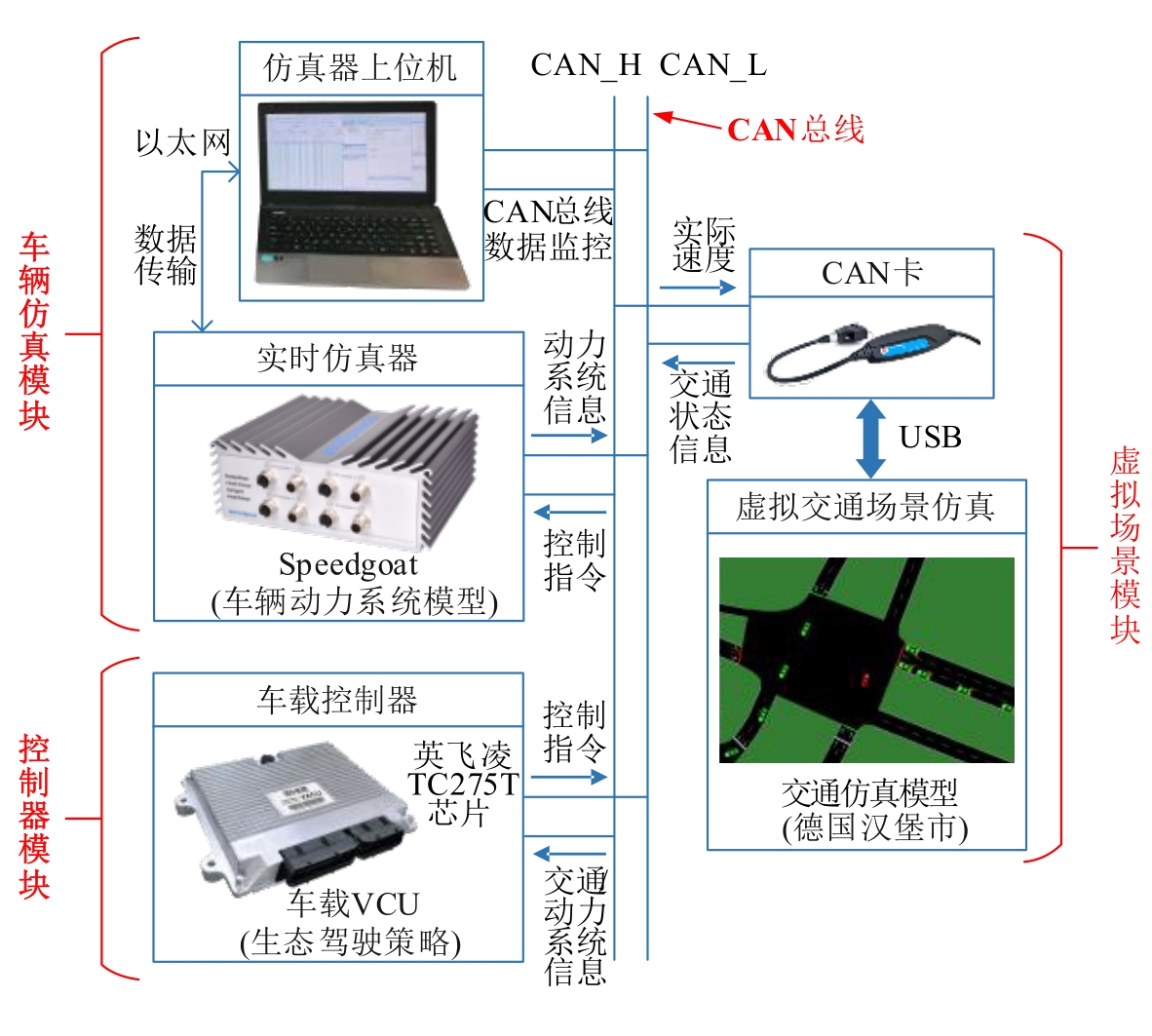
表2
车辆动力系统参数"
| 车辆参数 | 数值 | 单位 |
|---|---|---|
| 车辆质量 | 1 835 | kg |
| 电机峰值转矩 | 386 | N·m |
| 电机峰值功率 | 202 | kW |
| 电池电压 | 345.6 | V |
| 电池容量 | 173.5 | A·h |
| 主减速器传动比 | 9.1 | |
| 轮胎半径 | 0.344 | m |
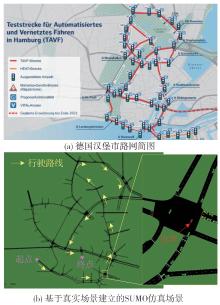
图7
虚拟交通场景"
图8
所提算法总奖励曲线"
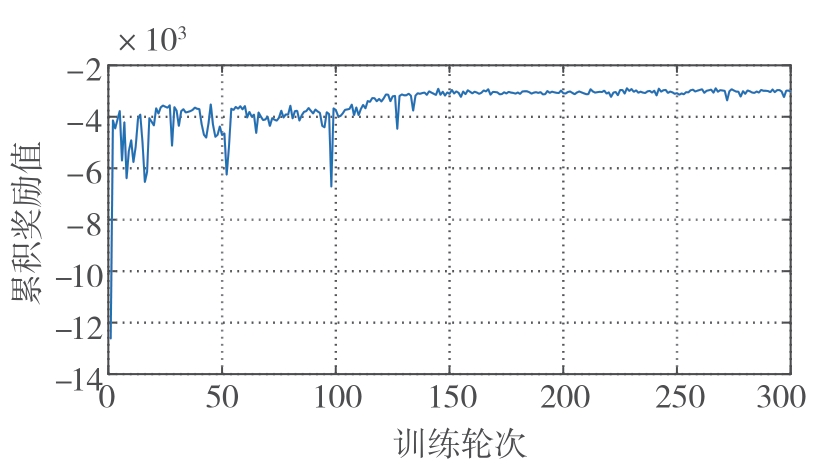
图9
基于IDM的生态驾驶策略框架"
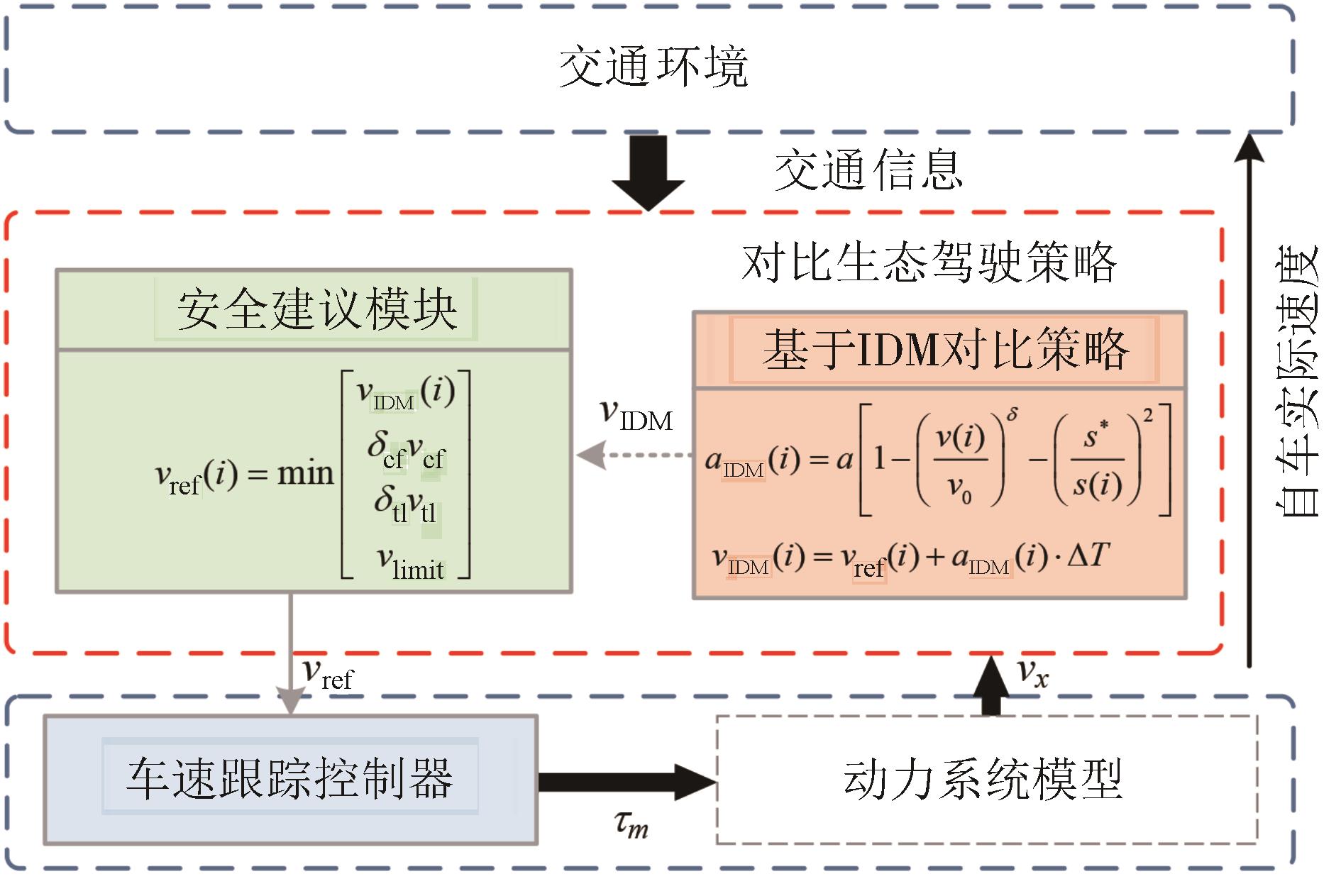
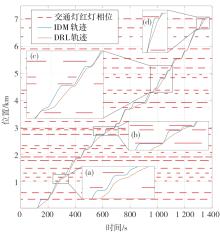
图10
两种策略车辆行驶轨迹时空图"
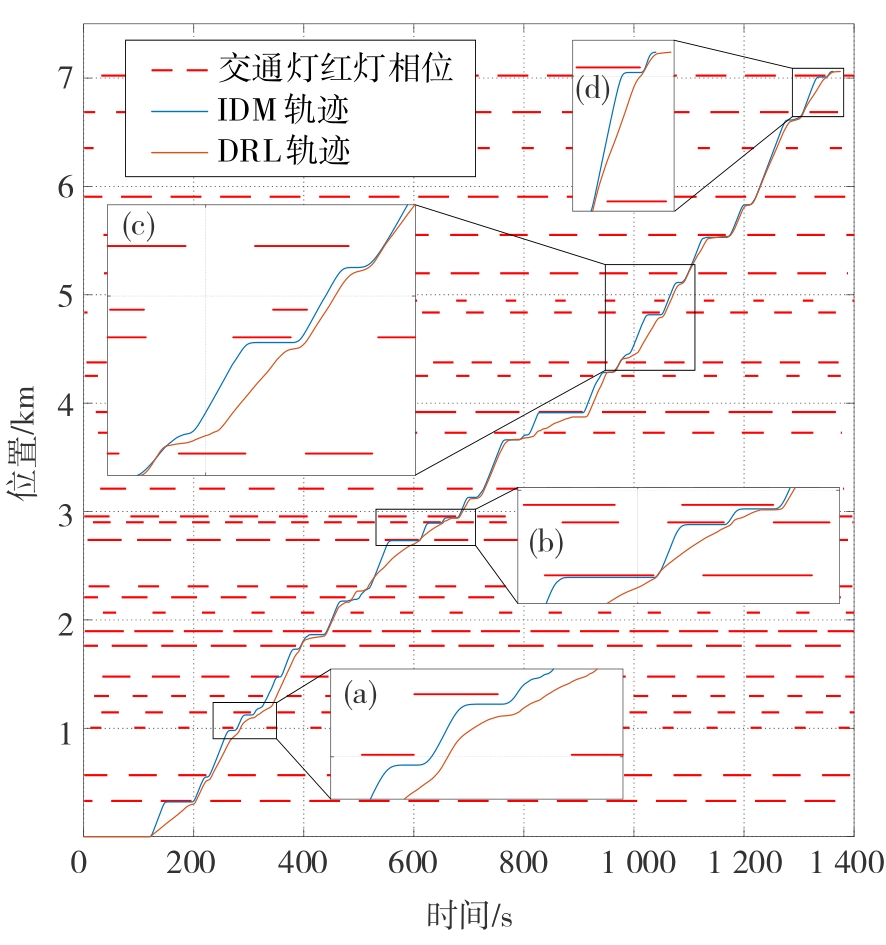
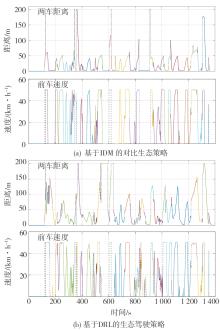
图11
虚拟交通场景中自车与前车的距离信息以及前车的车速信息"
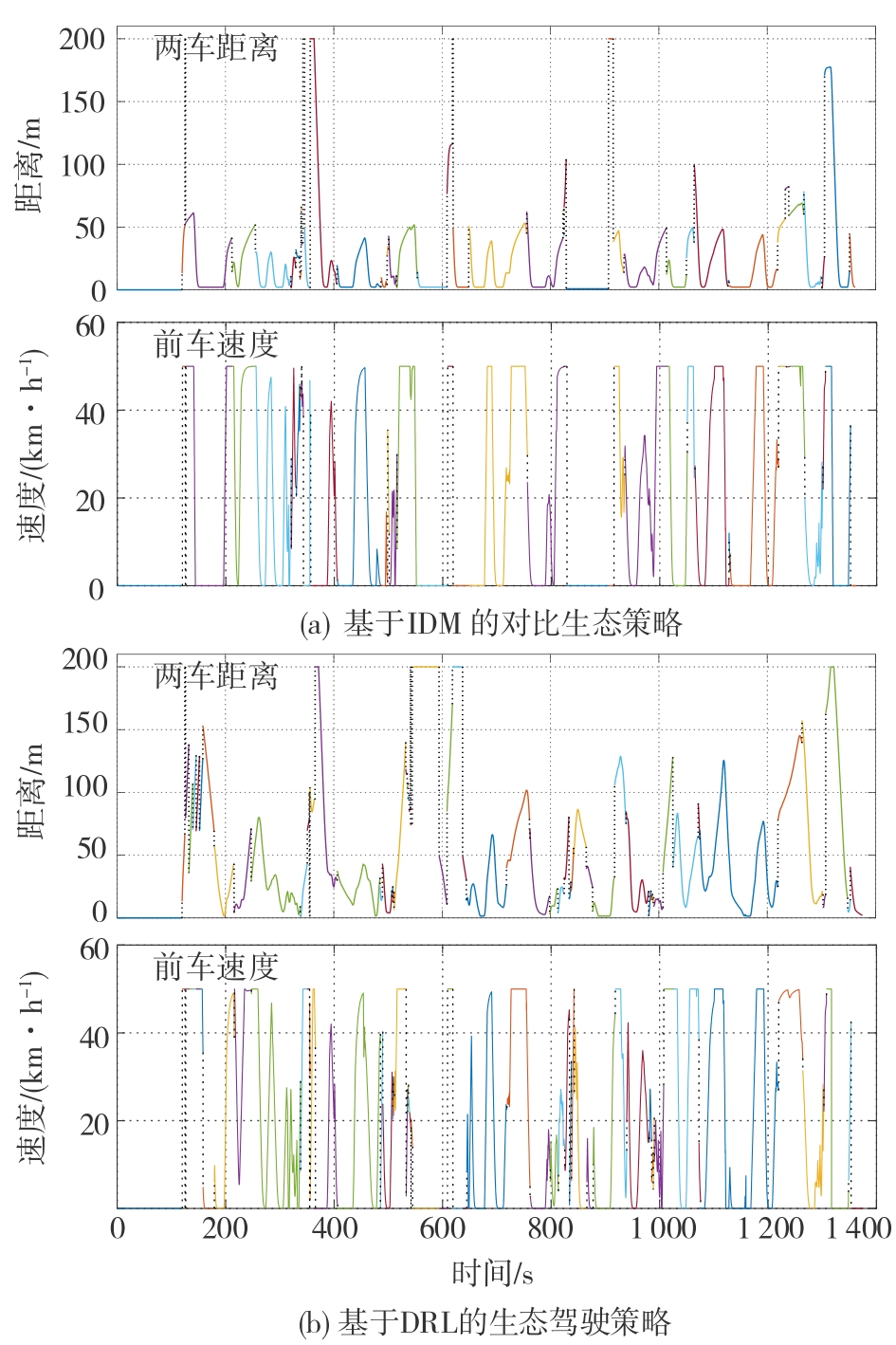
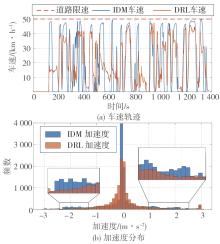
图12
两种策略的车速轨迹与加速度分布"

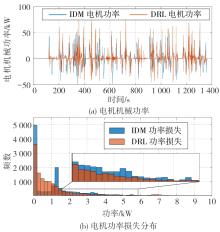
图13
两种策略的电机机械功率与电机功率损失分布"
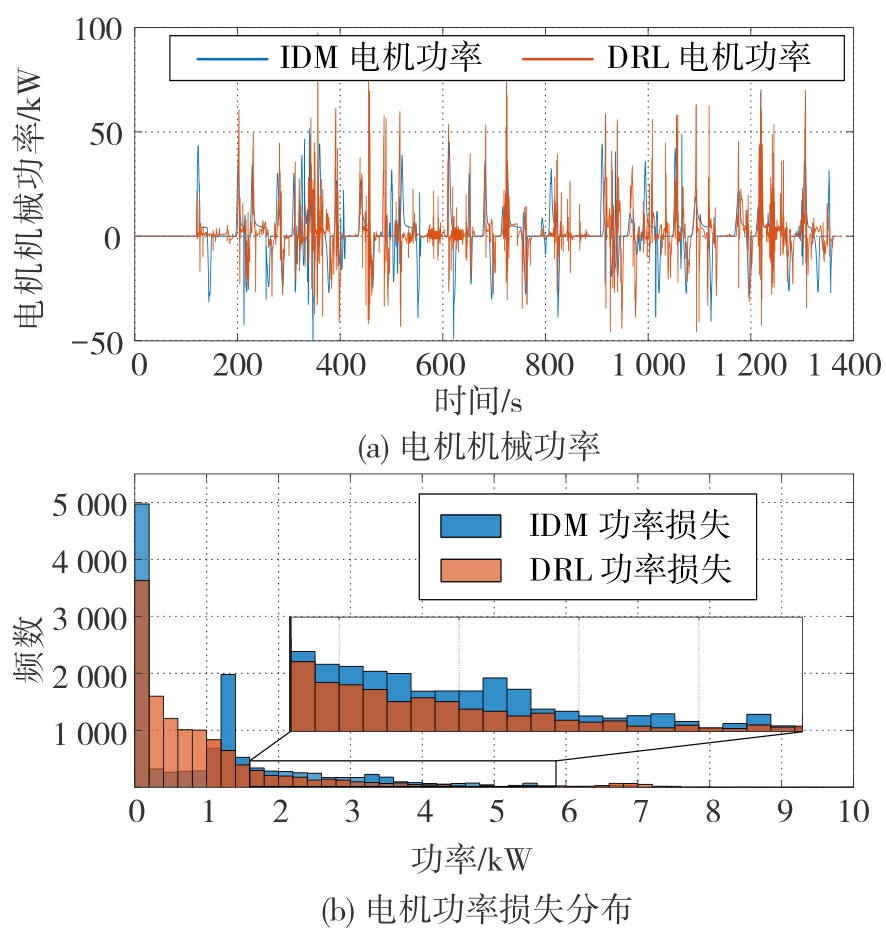
表3
实验结果对比"
| 参数 | IDM | DRL | 数值对比 |
|---|---|---|---|
| 前车最小距离/m | 0.884 7 | 0.976 8 | +10.41 % |
| 加速度绝对值平均/(m·s-2) | 0.551 7 | 0.495 0 | -10.28 % |
| 电池电耗/% | 1.644 | 1.464 | -10.94 % |
| 电机损失电能/kJ | 1 445 | 1 287 | -10.93 % |
| 总行驶时间/s | 1 242 | 1 255 | +1.047 % |
| 累积红灯停车时间/s | 337 | 56 | -83.38 % |
| 1 | HUANG Y, NG E C, ZHOU J L, et al. Eco-driving technology for sustainable road transport: a review[J]. Renewable and Sustainable Energy Reviews, 2018, 93: 596-609. |
| 2 | ZHANG F, HU X, LANGARI R, et al. Energy management strategies of connected HEVs and PHEVs: recent progress and outlook[J]. Progress in Energy and Combustion Science, 2019, 73: 235-256. |
| 3 | 钱立军, 陈健, 吴冰, 等. 考虑驾驶员操作误差的混合动力汽车队列生态驾驶控制[J]. 汽车工程, 2021, 43(7). |
| QIAN L, CHEN J, WU B, et al. Eco⁃driving control for hybrid electric vehicle platoon with consideration of driver operation error[J]. Automotive Engineering, 2021, 43(7). | |
| 4 | 魏小栋, 刘波, 冷江昊, 等. 基于凸优化的燃料电池汽车节能驾驶研究[J]. 汽车工程, 2022, 44(6). |
| WEI X, LIU B, LENG J, et al. Research on eco-driving of fuel cell vehicles via convex optimization[J]. Automotive Engineering, 2022, 44(6). | |
| 5 | KIM J, AHN C. Real-time speed trajectory planning for minimum fuel consumption of a ground vehicle[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(6): 2324-2338. |
| 6 | LI S E, PENG H, LI K, et al. Minimum fuel control strategy in automated car-following scenarios[J]. IEEE Transactions on Vehicular Technology, 2012, 61(3): 998-1007. |
| 7 | KAMALANATHSHARMA R K, RAKHA H A. Leveraging connected vehicle technology and telematics to enhance vehicle fuel efficiency in the vicinity of signalized intersections[J]. Journal of Intelligent Transportation Systems, 2014, 20(1): 1-12. |
| 8 | WU J, ZOU Y, ZHANG X, et al. A hierarchical energy management for hybrid electric tracked vehicle considering velocity planning with pseudospectral method[J]. IEEE Transactions on Transportation Electrification, 2020, 6(2): 703-716. |
| 9 | SHAO Y, SUN Z. Eco-approach with traffic prediction and experimental validation for connected and autonomous vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(3): 1562-1572. |
| 10 | LI L, WANG X, SONG J. Fuel consumption optimization for smart hybrid electric vehicle during a car-following process[J]. Mechanical Systems and Signal Processing, 2017, 87: 17-29. |
| 11 | SUTTON R S, BARTO A G. Reinforcement learning: an introduction[M]. MIT Press, 2018. |
| 12 | 唐小林, 陈佳信, 刘腾, 等. 基于深度强化学习的混合动力汽车智能跟车控制与能量管理策略研究[J]. 机械工程学报, 2021, 57(22): 237-246. |
| TANG X, CHEN J, LIU T, et al. Research on deep reinforcement learning-based intelligent car-following control and energy management strategy for hybrid electric vehicles[J]. Journal of Mechanical Engineering, 2021, 57(22): 237-246. | |
| 13 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. |
| 14 | FUJIMOTO S, HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[C]. International Conference on Machine Learning, 2018: 1587-1596. |
| 15 | LIU B, SUN C, WANG B, et al. Adaptive speed planning of connected and automated vehicles using multi-light trained deep reinforcement learning[J]. IEEE Transactions on Vehicular Technology, 2022, 71(4): 3533-3546. |
| 16 | BAI Z, HAO P, SHANGGUAN W, et al. Hybrid reinforcement learning-based eco-driving strategy for connected and automated vehicles at signalized intersections[J]. IEEE Transactions on Intelligent Transportation Systems, 2022: 1-14. |
| 17 | 张健, 姜夏, 史晓宇, 等. 基于离线强化学习的交叉口生态驾驶控制[J]. 东南大学学报(自然科学版), 2022(4): 052. |
| ZHANG J, JIANG X, SHI X, et al. Offline reinforcement learning for eco-driving control at signalized intersections[J]. Journal of Southeast University (Natural Science Edition), 2022(4): 052. | |
| 18 | KRAUß S, WAGNER P, GAWRON C. Metastable states in a microscopic model of traffic flow[J]. Physical Review E, 1997, 55(5): 5597. |
| 19 | LI J, WU X, XU M, et al. Deep reinforcement learning and reward shaping based eco-driving control for automated HEVs among signalized intersections[J]. Energy, 2022, 251: 123924. |
| 20 | NG A Y, HARADA D, RUSSELL S. Policy invariance under reward transformations: theory and application to reward shaping[C]. Icml, 1999: 278-287. |
| 21 | DEVLIN S M, KUDENKO D. Dynamic potential-based reward shaping[C]. Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, 2012: 433-440. |
| 22 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J]. arXiv preprint arXiv:, 2015. |
| 23 | SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]. International Conference on Machine Learning, 2014: 387-395. |
| 24 | Speedgoat real-time simulation and testing[EB/OL]. https://www.speedgoat.com/. |
| 25 | HALBACH S, SHARER P, PAGERIT S, et al. Model architecture, methods, and interfaces for efficient math-based design and simulation of automotive control systems[C]. SAE Paper 2010-01-0241. |
| 26 | We are TAVF[EB/OL]. https://tavf.hamburg/en/we-are-tavf. |
| 27 | TAVF-Hamburg Scenario on GitHub[EB/OL]. https://github.com/DLR-TS/sumo-scenarios/tree/main/TAVF-Hamburg. |
| 28 | 邹渊, 张涛, 张旭东, 等. 考虑车流影响的网联车辆节能驾驶研究[J]. 汽车工程, 2020, 42(10). |
| ZOU Y, ZHANG T, ZHANG X, et al. Research on eco-driving of connected vehicles considering the influence of traffic flow[J]. Automotive Engineering, 2020, 42(10). | |
| 29 | TREIBER M, HENNECKE A, HELBING D. Congested traffic states in empirical observations and microscopic simulations[J]. Physical Review E, 2000, 62(2): 1805. |
| [1] | 胡林,谷子逸,王丹琦,王方,邹铁方,黄晶. 汽车安全性测评规程现状及趋势展望[J]. 汽车工程, 2024, 46(2): 187-200. |
| [2] | 关书睿,李克强,周俊宇,石佳,孔伟伟,罗禹贡. 面向强制换道场景的智能网联汽车协同换道策略[J]. 汽车工程, 2024, 46(2): 201-210. |
| [3] | 王庞伟,刘程,汪云峰,张名芳. 面向城市道路的智能网联汽车多车道轨迹优化方法[J]. 汽车工程, 2024, 46(2): 241-252. |
| [4] | 熊萌,张栋,尤国建,孙添飞,盛凯,魏学哲. 电动汽车无线充电高效高利用率磁芯的多目标优化设计[J]. 汽车工程, 2023, 45(9): 1740-1752. |
| [5] | 左政,王云鹏,麻斌,邹博松,曹耀光,杨世春. 基于AFC-TARA的车载网络组件风险率量化评估分析[J]. 汽车工程, 2023, 45(9): 1553-1562. |
| [6] | 李升波,占国建,蒋宇轩,兰志前,张宇航,邹文俊,陈晨,成波,李克强. 类脑学习型自动驾驶决控系统的关键技术[J]. 汽车工程, 2023, 45(9): 1499-1515. |
| [7] | 刘济铮,王震坡,孙逢春,张雷. 异构智能网联汽车编队延迟补偿控制研究[J]. 汽车工程, 2023, 45(9): 1573-1582. |
| [8] | 吴思宇,于文浩,邢星宇,张玉新,李楚照,李雪轲,古昕昱,李云巍,马小涵,路伟,王政,郝圳茂,王红,李骏. 基于关键场景的预期功能安全双闭环测试验证方法[J]. 汽车工程, 2023, 45(9): 1583-1607. |
| [9] | 边有钢,张田田,谢和平,秦洪懋,杨泽宇. 车辆队列抗扰抗内切协同路径跟踪控制[J]. 汽车工程, 2023, 45(8): 1320-1332. |
| [10] | 朱冰,姜泓屹,赵健,韩嘉懿,刘彦辰. 智能网联汽车协同感知信任度动态计算与评价方法[J]. 汽车工程, 2023, 45(8): 1383-1391. |
| [11] | 关宇昕,冀浩杰,崔哲,李贺,陈丽文. 智能网联汽车车载CAN网络入侵检测方法综述[J]. 汽车工程, 2023, 45(6): 922-935. |
| [12] | 邹渊,孙文景,张旭东,温雅,曹万科,张兆龙. 面向时间敏感网络的车载以太网网络架构多目标优化[J]. 汽车工程, 2023, 45(5): 746-758. |
| [13] | 李亚鹏,唐小林,胡晓松. 基于分层式控制的混合动力汽车生态驾驶研究[J]. 汽车工程, 2023, 45(4): 551-560. |
| [14] | 胡耘浩,李克强,向云丰,石佳,罗禹贡. 智能网联汽车通用跨平台实时仿真系统架构及应用[J]. 汽车工程, 2023, 45(3): 372-381. |
| [15] | 段志勇,马菁. 锂电池热管-液冷板式冷却结构多目标优化[J]. 汽车工程, 2023, 45(11): 2047-2057. |
|