汽车工程 ›› 2024, Vol. 46 ›› Issue (12): 2290-2302.doi: 10.19562/j.chinasae.qcgc.2024.12.015
祝琴1,2,韩沈阳2,曾明如2( ),赖平红3,吴垂茂2,胡玮轶2
),赖平红3,吴垂茂2,胡玮轶2
收稿日期:2024-04-26
修回日期:2024-06-12
出版日期:2024-12-25
发布日期:2024-12-20
通讯作者:
曾明如
E-mail:zeng_mr@163.com
基金资助:
Qin Zhu1,2,Shenyang Han2,Mingru Zeng2(),Pinghong Lai3,Chuimao Wu2,Weiyi Hu2
Received:2024-04-26
Revised:2024-06-12
Online:2024-12-25
Published:2024-12-20
Contact:
Mingru Zeng
E-mail:zeng_mr@163.com
摘要:
针对复杂交通监控场景中视频车辆检测模型难以提取丰富的目标特征的问题,本文从充分利用视频图像时空特征信息的角度,新建时空特征融合模块SF-Module,运用Transformer模型中的多头自注意力机制实现视频车辆图像当前帧和历史帧时空特征信息的提取和融合,丰富目标的特征信息;在此基础上,基于YOLOv8网络,在其颈部网络融合新建的时空特征融合模块SF-Module,挖掘视频图像序列的时空特征信息;同时,引入WIoU损失函数作为预测框回归损失,减少低质量标注框产生的有害梯度,设计SFW-YOLOv8视频车辆检测模型。最后,新建的SFW-YOLOv8复杂场景视频车辆检测模型在UA-DETRAC数据集上进行实验,对数据集中的部分图片进行了模拟雨天和雾天的数据增强,提高车辆检测模型的泛化性。实验结果表明,SFW-YOLOv8视频车辆检测模型的MAP50和MAP50:5:95值为79.1%和63.6%,较YOLOv8模型分别提高了1.7%和3.3%,推理速度为11 ms/帧,具有较为优秀的检测性能。
祝琴,韩沈阳,曾明如,赖平红,吴垂茂,胡玮轶. SFW-YOLOv8复杂场景视频车辆检测模型[J]. 汽车工程, 2024, 46(12): 2290-2302.
Qin Zhu,Shenyang Han,Mingru Zeng,Pinghong Lai,Chuimao Wu,Weiyi Hu. SFW-YOLOv8 Complex Scene Video Vehicle Detection Model[J]. Automotive Engineering, 2024, 46(12): 2290-2302.

图1
SFW-YOLOv8训练流程图"


图2
UA-DETRAC数据集中忽略区域的展示"


图3
UA-DETRAC数据集忽略区域黑化效果图"


图4
YOLOv8图像增强部分展示"


图5
UA-DETRAC数据集模拟雾天雨天的效果图"


图6
YOLOv8和SFW-YOLOv8的数据增强流程"

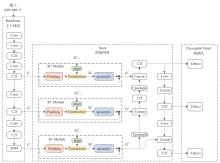
图7
SFW-YOLOv8模型网络结构图"
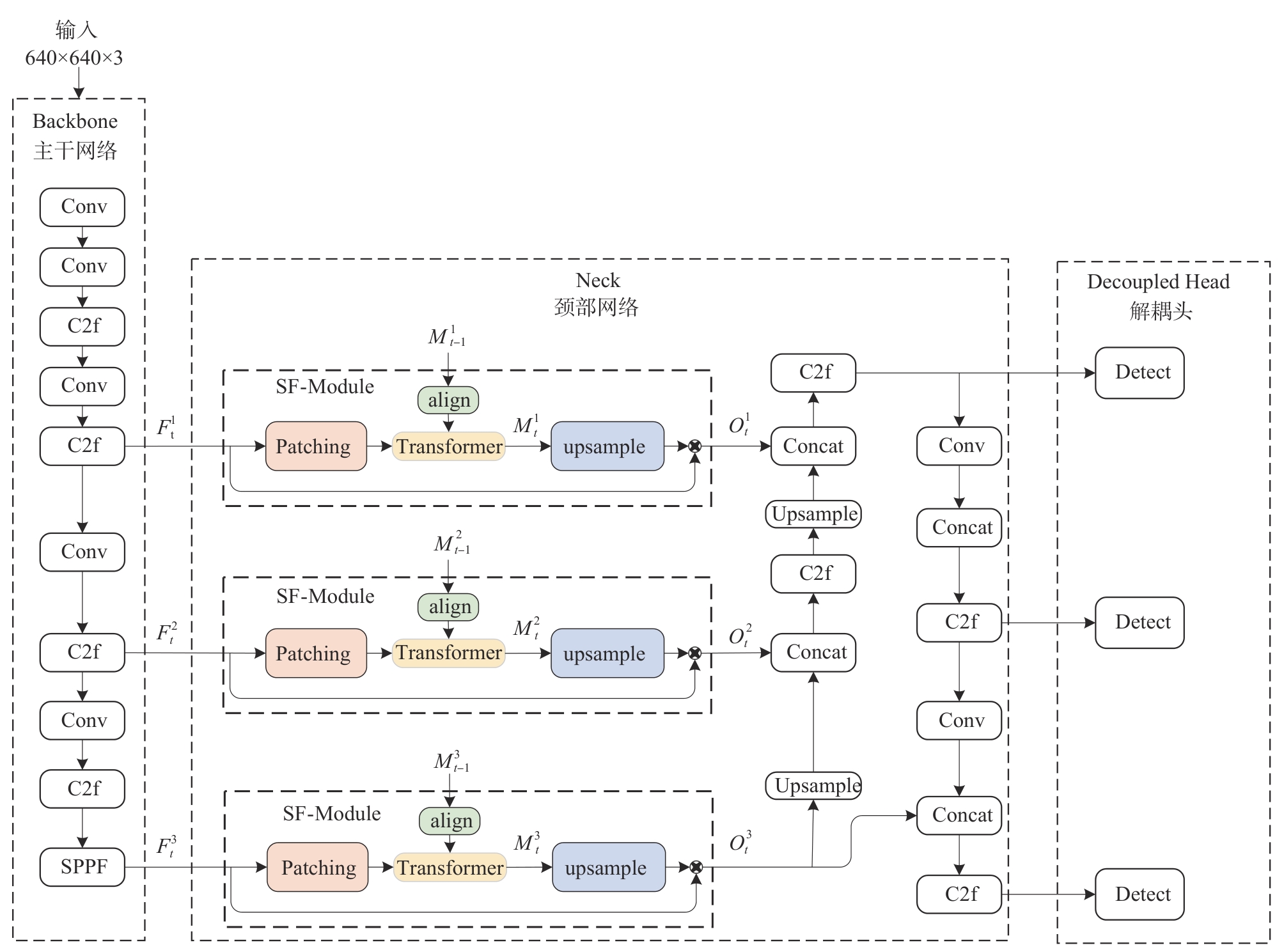
图8
SF-Module时空特征融合模块结构图"
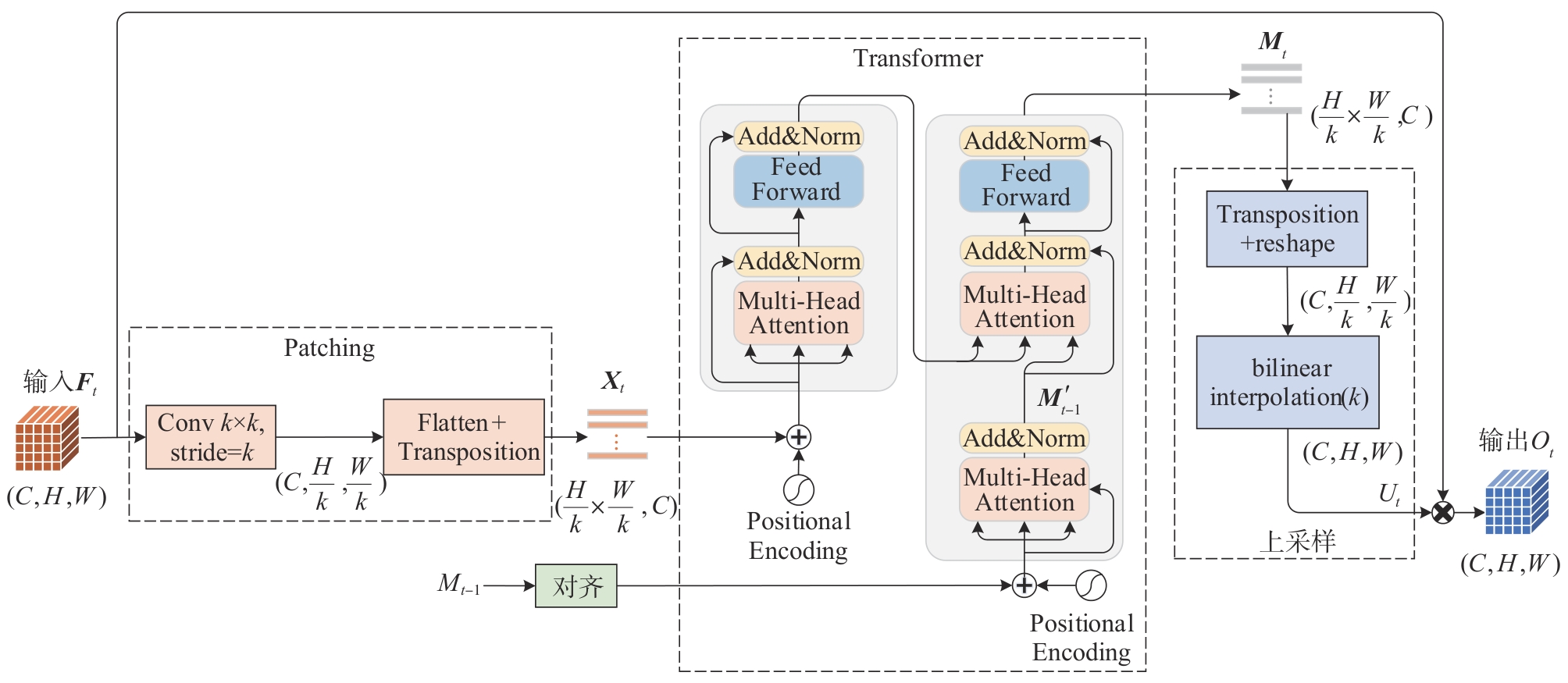
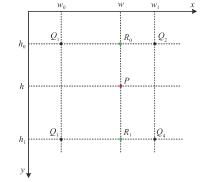
图9
双线性插值示意图"


图10
低质量标注框示意图"

表1
实验环境准备"
| 实验环境 | 环境配置 |
|---|---|
| 操作系统 | Ubuntu |
| GPU | NVIDIA GeForce RTX 2080 Ti |
| 显存 | 12 GB |
| 编程语言 | Python3.7 |
| 深度学习框架 | PyTorch1.8.0 |
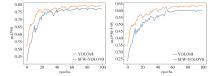
图11
YOLOv8和SFW-YOLOv8训练时mAP值曲线图"
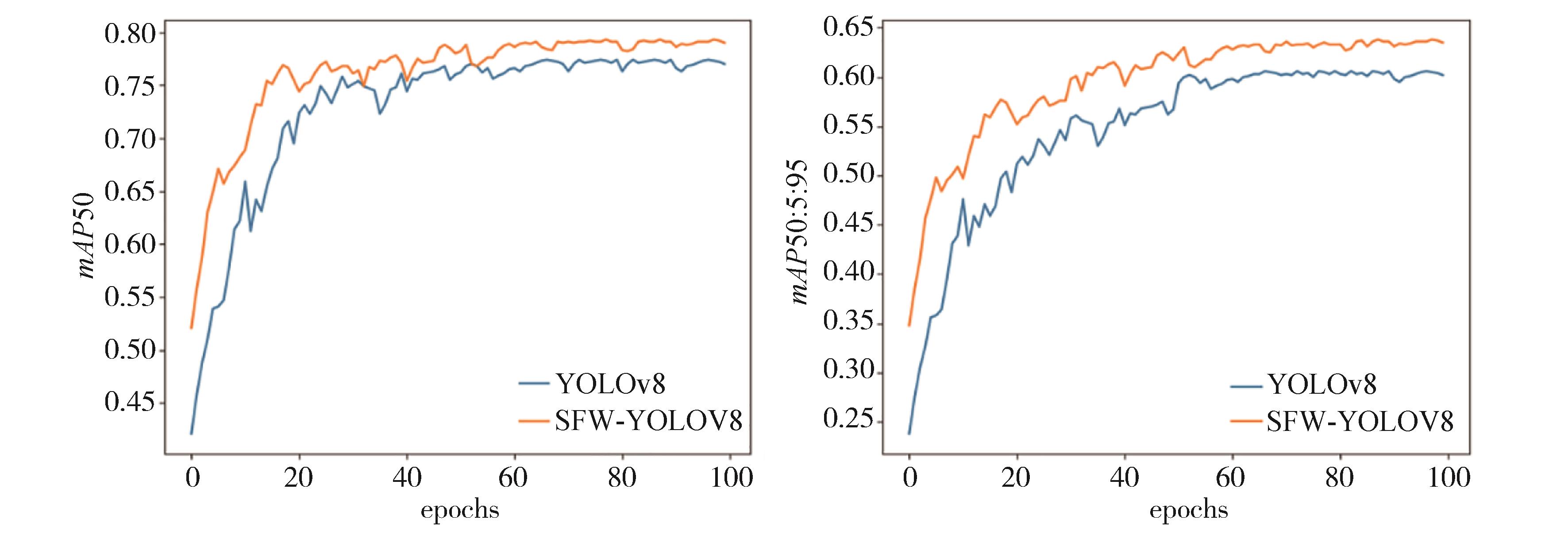
表2
SF-Module的有效性对比"
| 方法 | mAP50/% | mAP50:5:95/% | 推理速度/(ms·帧-1) |
|---|---|---|---|
| YOLOv8 | 77.4 | 60.3 | 9.3 |
| +convGRU[ | 77.8 | 61.3 | 9.8 |
| +SF-Module | 78.2 | 62.4 | 10.9 |
表3
各模块的有效性实验"
| 方法 | SF-Module | WIoU | mAP50/% | mAP50:5:95/% | 推理速度/(ms·帧-1) |
|---|---|---|---|---|---|
| YOLOv8 | 77.4 | 60.3 | 9.3 | ||
| A | √ | 78.2 | 62.5 | 10.9 | |
| B | √ | 78.4 | 61.8 | 9.4 | |
| C | √ | √ | 79.5 | 63.6 | 11.2 |
表4
不同跟踪算法实验对比结果"
| 方法 | mAP50/% | mAP50:5:95/% | 推理速度/(ms·帧-1) |
|---|---|---|---|
| Faster R-CNN[ | 67.1 | 50.1 | 88.5 |
| SSD[ | 70.2 | 51.8 | 53.8 |
| RetinaNet[ | 72.4 | 53.1 | 50.4 |
| YOLOv5 | 76.3 | 58.1 | 11.3 |
| YOLOX[ | 75.9 | 56.9 | 15.5 |
| YOLOv7[ | 76.7 | 58.4 | 10.4 |
| YOLOv8 | 77.4 | 60.3 | 9.3 |
| SFW-YOLOv8 | 79.5 | 63.6 | 11.2 |
表5
BDD100K数据集真实雨雾场景实验对比结果"
| 方法 | mAP50/% | mAP50:5:95/% | 推理速度/(ms·帧-1) |
|---|---|---|---|
| YOLOv8 | 76.5 | 59.2 | 10.3 |
| SFW-YOLOv8 | 77.6 | 61.1 | 11.9 |
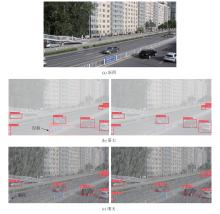
图12
不同恶劣天气场景可视化结果对比图"

| 1 | TSAI D,LAI S.Independent component analysis-based background subtraction for indoor surveillance[J].IEEE Transactions on Image Processing, 2009, 18(1): 158-167. |
| 2 | LEE D S.Effective gaussian mixture learning for video background subtraction[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 827-832. |
| 3 | HORN B K P, SCHUNCK B G. Determining optical flow[J].Artificial Intelligence, 1981, 17(1/3): 185-203. |
| 4 | XU Z H, HUANG W Q, WANG W. Multi-category vehicle detection in surveillance video based on deep learning[J]. Journal of Computer Applications, 2019, 39(3): 700-705. |
| 5 | 江屾. 基于改进YOLOv5的车辆检测及跟踪方法研究[D]. 重庆:重庆交通大学,2023. |
| JIANG Shen. Research on vehicle detection and tracking methods based on improved YOLOv5 [D]. Chongqing: Chongqing Jiaotong University,2023. | |
| 6 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. Computer Vision and Pattern Recognition. USA: IEEE, 2014: 580-587. |
| 7 | HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015,37(9): 1904-1916. |
| 8 | GIRSHICK R. Fast R-CNN[C]. Proceedings of IEEE International Conference on Computer Vision, USA: IEEE, 2015: 1440-1448. |
| 9 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149. |
| 10 | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]. Proceedings of the IEEE International Conference on Computer Vision, 2017: 2961-2969. |
| 11 | FAN Q, BROWN L, SMITH J. A closer look at faster R-CNN for vehicle detection[C]. 2016 IEEE intelligent vehicles symposium (IV). IEEE, 2016: 124-129. |
| 12 | XU Y, YU G, WANG Y, et al. Car detection from low-altitude UAV imagery with the faster R-CNN[J]. Journal of Advanced Transportation, 2017, 2017. |
| 13 | 朱茂桃,张鸿翔,方瑞华. 基于RCNN的车辆检测方法研究[J]. 机电工程,2018,35(8):880-885. |
| ZHU Maotao, ZHANG Hongxiang, FANG Ruihua. Research on vehicle detection method based on RCNN [J]. Mechanical and Electrical Engineering,2018,35(8):880-885. | |
| 14 | HSU S C, HUANG C L, CHUANG C H. Vehicle detection using simplified fast R-CNN[C]. 2018 International Workshop on Advanced Image Technology (IWAIT). IEEE, 2018: 1-3. |
| 15 | 陈玉敏,李淼,房晓丽. 基于时空融合加速的Fast RCNN运动车辆检测算法[J]. 电子测量技术,2020,43(3):139-145. |
| CHEN Yumin, LI Miao, FANG Xiaoli. Fast RCNN moving vehicle detection algorithm based on spatiotemporal fusion acceleration [J]. Electronic Measurement Technology, 2019,43(3):139-145. | |
| 16 | 李松江,吴宁,王鹏,等. 基于改进Cascade RCNN的车辆目标检测方法[J]. 计算机工程与应用,2021,57(5):123-130. |
| LI Songjiang, WU Ning, WANG Peng, et al. Vehicle target detection method based on improved cascade RCNN [J]. Computer Engineering and Applications, 2019,57(5):123-130. | |
| 17 | 柳杰,金积德,郑庆祥. 基于改进Mask RCNN的夜间车辆检测方法[J]. 交通信息与安全,2023,41(2):59-66. |
| LIU Jie, JIN Jide, ZHENG Qingxiang. Vehicle detection method at night based on improved mask RCNN [J]. Traffic Information and Safety, 2019,41(2):59-66. | |
| 18 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016: 779-788. |
| 19 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]. European Conference on Computer Vision. Springer, Cham, 2016: 21-37. |
| 20 | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99): 2999-3007. |
| 21 | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]. IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2017: 6517-6525. |
| 22 | REDMON J, FARHADI A. YOLOv3: an incremental improvement[J]. arXiv e-prints, 2018. |
| 23 | BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOV4: optimal speed and accuracy of object detection[J]. arXiv preprint arXiv: , 2020. |
| 24 | GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021[J]. arXiv preprint arXiv: , 2021. |
| 25 | LI C, LI L, JIANG H, et al. YOLOv6: a single-stage object detection framework for industrial applications[J]. arXiv preprint arXiv:, 2022. |
| 26 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 7464-7475. |
| 27 | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]. European Conference on Computer Vision, 2020: 213-229. |
| 28 | 李珣,刘瑶,李鹏飞,等. 基于Darknet框架下YOLO v2算法的车辆多目标检测方法[J]. 交通运输工程学报,2018,18(6):142-158. |
| LI Xun, LIU Yao, LI Pengfei, et al. Vehicle multi-target detection method based on YOLOv2 algorithm in darknet framework [J]. Journal of Traffic and Transportation Engineering,2018,18(6):142-158. | |
| 29 | CHEN S, LIN W. Embedded system real-time vehicle detection based on improved YOLO network[C]. 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC). IEEE, 2019: 1400-1403. |
| 30 | 徐浩,杨德刚,蒋倩倩,等. 基于SSD的轻量级车辆检测网络改进[J]. 计算机工程与应用,2022,58(12):209-217. |
| XU Hao, YANG Degang, JIANG Qianqian, et al. Improvement of lightweight vehicle detection network based on SSD [J]. Computer Engineering and Applications,2022,58(12):209-217. | |
| 31 | ZHANG Y, GUO Z, WU J, et al. Real-time vehicle detection based on improved YOLOv5[J]. Sustainability, 2022, 14(19): 12274. |
| 32 | 蔡刘畅,杨培峰,张秋仪. 基于YOLOv7的道路监控车辆检测方法[J]. 陕西科技大学学报,2023,41(6):155-161,175. |
| WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 7464-7475. | |
| 33 | 许晓阳,高重阳. 改进YOLOv7-tiny的轻量级红外车辆目标检测算法[J]. 计算机工程与应用,2024,60(1):74-83. |
| XU Xiaoyang, GAO Chongyang. Improved lightweight infrared vehicle target detection algorithm based on YOLOv7-tiny [J]. Computer Engineering and Applications, 2024,60(1):74-83. | |
| 34 | 周飞,郭杜杜,王洋,等. 基于改进YOLOv8的交通监控车辆检测算法[J]. 计算机工程与应用,2024,60(6):110-120. |
| ZHOU Fei, GUO Dudu, WANG Yang, et al. Vehicle detection algorithm for traffic monitoring based on improved YOLOv8 [J]. Computer Engineering and Applications, 2024,60(6):110-120. | |
| 35 | KANG K, OUYANG W L, LI H S, et al. Object detection from video tubelets with convolutional neural networks[C]. Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 817-825. |
| 36 | FEICHTENHOFER C, PINZ A, ZISSERMAN A. Detect to track and track to detect[C]. Proceedings of the 2017 IEEE International Conference on Computer Vision, 2017: 3057-3065. |
| 37 | XIAO F Y, LEE Y J. Video object detection with an aligned spatial-temporal memory[C]. Proceedings of the 15th European Conference on Computer Vision, 2018: 494-510. |
| 38 | GONG T, CHEN K, WANG X,et al. Temporal RoI align for video object recognition[J]. arXiv:,2021. |
| 39 | 程稳,陈忠碧,李庆庆,等. 时空特征对齐的多目标跟踪算法[J]. 光电工程,2023,50(6):66-79. |
| CHENG Wen, CHEN Zhongbi, LI Qingqing, et al. Multi-target tracking algorithm with spatiotemporal feature alignment [J]. Opto-electronic Engineering,2023,50(6):66-79. | |
| 40 | WEN L, DU D, CAI Z, et al. UA-DETRAC: a new benchmark and protocol for multi-object detection and tracking[J]. Computer Vision and Image Understanding, 2020, 193: 102907. |
| 41 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30. |
| 42 | ZHANG H, WANG Y, DAYOUB F, et al. Varifocalnet: an iou-aware dense object detector[C].Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 8514-8523. |
| 43 | LI X, WANG W, WU L, et al. Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection[J]. Advances in Neural Information Processing Systems, 2020, 33: 21002-21012. |
| 44 | TONG Z, CHEN Y, XU Z, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism[J]. arXiv preprint arXiv:, 2023. |
| [1] | 罗玉涛,郭丰瑞. 基于注意力融合特征增强的座舱表情识别模型[J]. 汽车工程, 2024, 46(9): 1697-1706. |
| [2] | 周亦威,夏莫,朱冰. 城市道路场景下考虑多类交通参与者的多模态车辆轨迹预测方法研究[J]. 汽车工程, 2024, 46(3): 396-406. |
| [3] | 赵健,李文旭,朱冰,张培兴,汤瑞,李嘉胜. 面向智能驾驶测试的可变跟驰特性交通车建模方法[J]. 汽车工程, 2024, 46(11): 1952-1961. |
| [4] | 胡杰,陈琳,王志红,卿海华,王浩杰. 基于Transformer的纯电动汽车充电时间预测[J]. 汽车工程, 2024, 46(11): 2059-2067. |
| [5] | 李勇滔,孙晨旭,郑伟光,许恩永,李育方,王善超. 基于毫米波雷达与视觉融合的碰撞预警[J]. 汽车工程, 2023, 45(9): 1666-1676. |
| [6] | 赵霞,李朝,付锐,葛振振,王畅. 基于深度卷积-Tokens降维优化视觉Transformer的分心驾驶行为实时检测[J]. 汽车工程, 2023, 45(6): 974-988. |
| [7] | 李琳辉,张鑫亮,付一帆,连静,马家旭. 基于TC-YOLOv7算法的可见光与红外后融合检测研究[J]. 汽车工程, 2023, 45(12): 2280-2290. |
| [8] | 陈龙,杨晨,蔡英凤,王海,李祎承. 基于多模态特征融合的行人穿越意图预测方法[J]. 汽车工程, 2023, 45(10): 1779-1790. |
| [9] | 张小俊,奚敬哲,史延雷,袁安录. 面向路侧视角目标检测的轻量级YOLOv7-R算法[J]. 汽车工程, 2023, 45(10): 1833-1844. |
| [10] | 王大方,尚海,曹江,王涛,夏祥腾,韩雨霖. 基于自注意力机制的自动驾驶场景点云语义分割方法[J]. 汽车工程, 2022, 44(11): 1656-1664. |
| [11] | 刘军,陈岚磊,李汉冰. 基于类人视觉的多任务交通目标实时检测模型[J]. 汽车工程, 2021, 43(1): 50-58. |
| [12] | 蔡英凤, 邰康盛, 王海, 李祎承, 陈龙. 无人驾驶汽车周边车辆行为识别算法研究*[J]. 汽车工程, 2020, 42(11): 1464-1472. |
|