汽车工程 ›› 2023, Vol. 45 ›› Issue (10): 1779-1790.doi: 10.19562/j.chinasae.qcgc.2023.10.001
所属专题: 智能网联汽车技术专题-感知&HMI&测评2023年
• • 下一篇
陈龙1,杨晨1,蔡英凤1( ),王海2,李祎承2
),王海2,李祎承2
收稿日期:2023-02-13
修回日期:2023-03-14
出版日期:2023-10-25
发布日期:2023-10-23
通讯作者:
蔡英凤
E-mail:caicaixiao0304@126.com
基金资助:
Long Chen1,Chen Yang1,Yingfeng Cai1(),Hai Wang2,Yicheng Li2
Received:2023-02-13
Revised:2023-03-14
Online:2023-10-25
Published:2023-10-23
Contact:
Yingfeng Cai
E-mail:caicaixiao0304@126.com
摘要:
行人行为预测是城市环境智能汽车决策规划系统面临的主要挑战之一,提升行人穿越意图的预测准确率对于行车安全意义重大。针对现有方法过度依赖行人的边界框位置信息,且很少考虑交通场景中环境信息及交通对象间的交互关系等问题,本文提出一种基于多模态特征融合的行人过街意图预测方法。首先结合多种注意力机制构建了一种新型全局场景上下文信息提取模块和局部场景时空特征提取模块来增强其提取车辆周边场景时空特征的能力,并依赖场景的语义解析结果来捕获行人与其周围环境之间的交互关系,解决了交通环境上下文信息与交通对象之间的交互信息应用不充分的问题。此外,本文设计了一种基于混合融合策略的多模态特征融合模块,根据不同信息源的复杂程度实现了对视觉特征和运动特征的联合推理,为行人穿越意图预测模块提供可靠信息。基于JAAD数据集的测试表明,所提出方法的预测Accuracy为0.84,较基线方法提升了10.5%,相比于现有的同类型模型,所提出方法的综合性能最佳,且具有更广泛的应用场景。
陈龙,杨晨,蔡英凤,王海,李祎承. 基于多模态特征融合的行人穿越意图预测方法[J]. 汽车工程, 2023, 45(10): 1779-1790.
Long Chen,Chen Yang,Yingfeng Cai,Hai Wang,Yicheng Li. Pedestrian Crossing Intention Prediction Method Based on Multimodal Feature Fusion[J]. Automotive Engineering, 2023, 45(10): 1779-1790.

图1
本文所提算法的整体架构图"


图2
GRU结构简图"
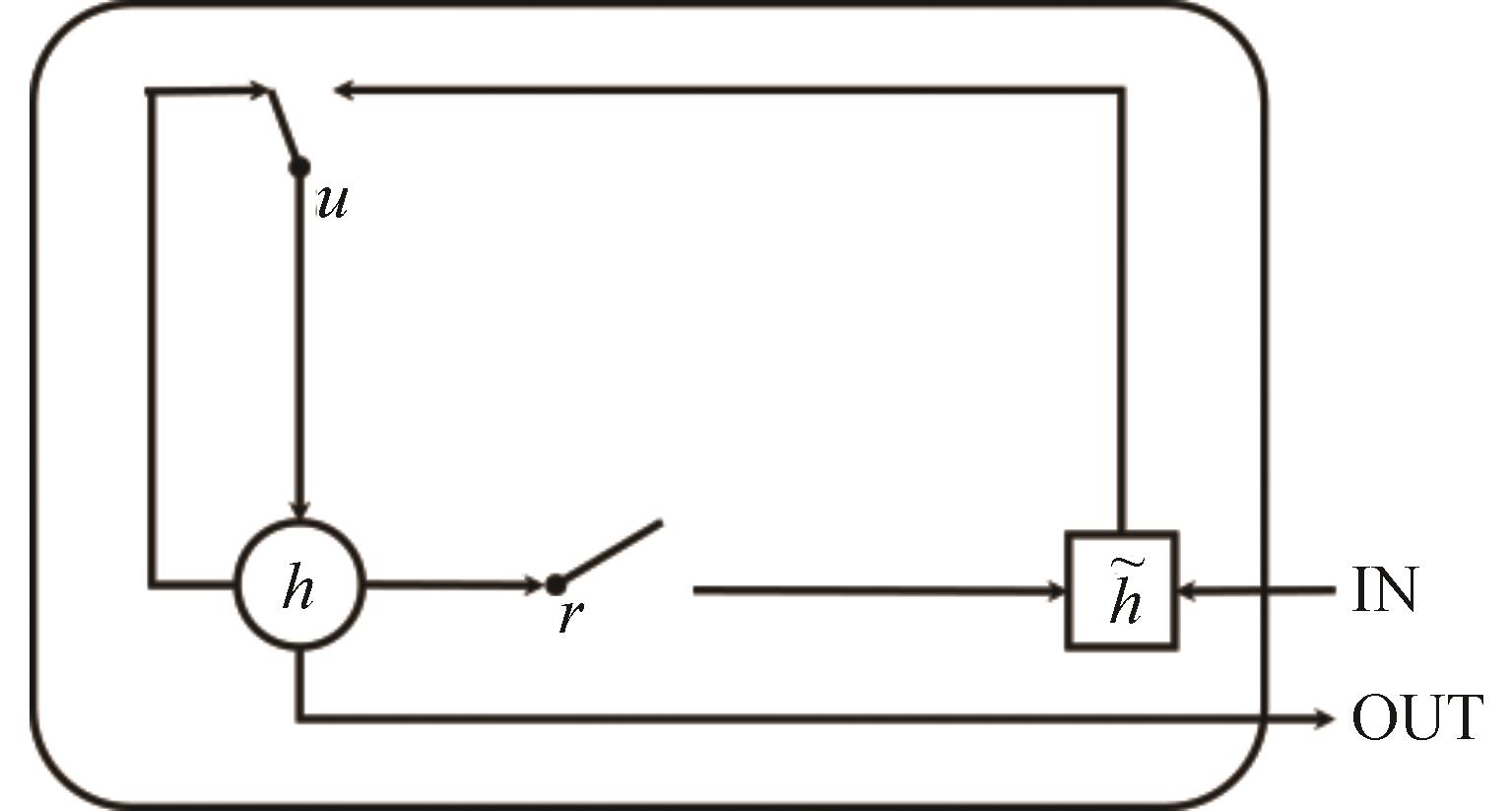
图3
AUGRU结构简图"
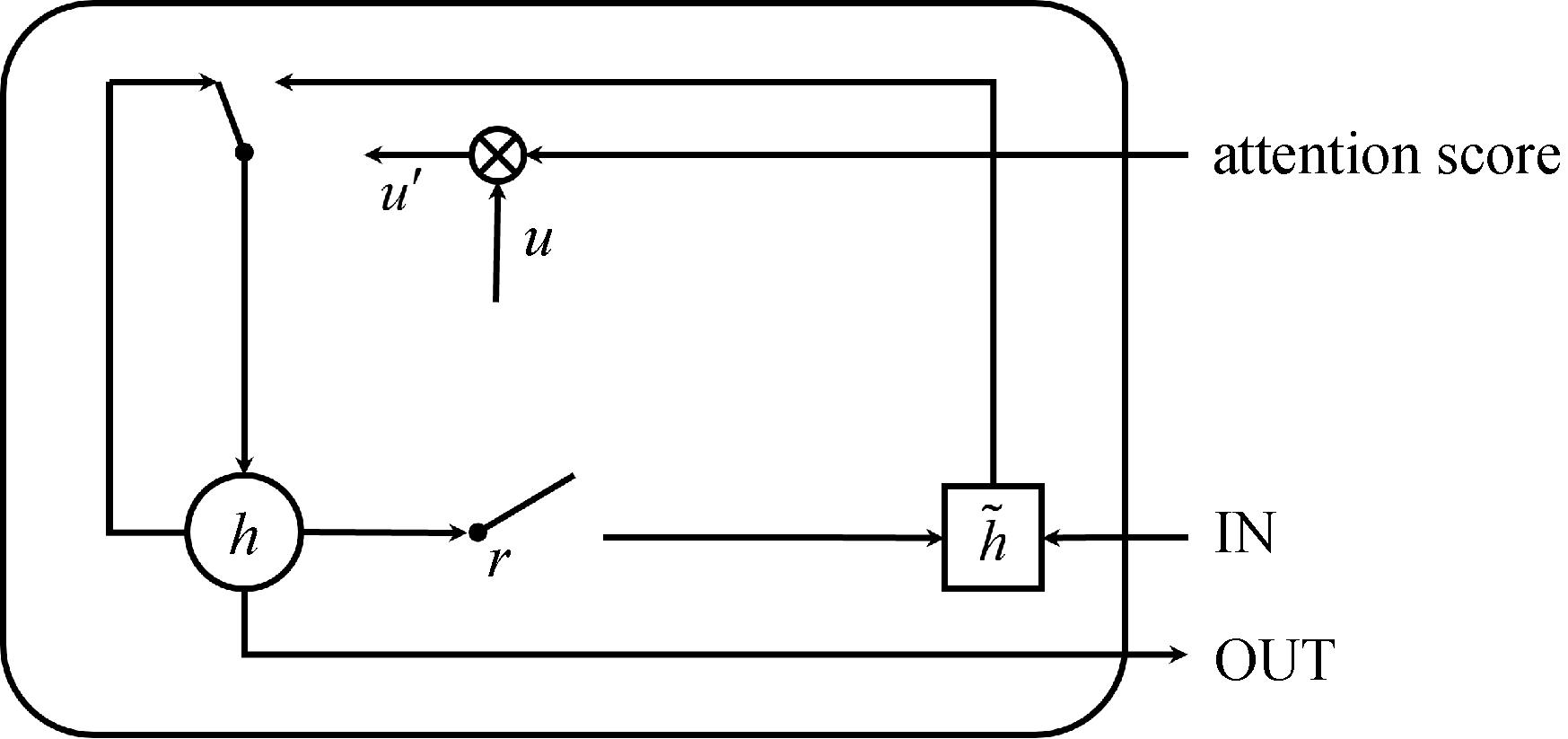

图4
全局场景上下文交互信息提取模块"
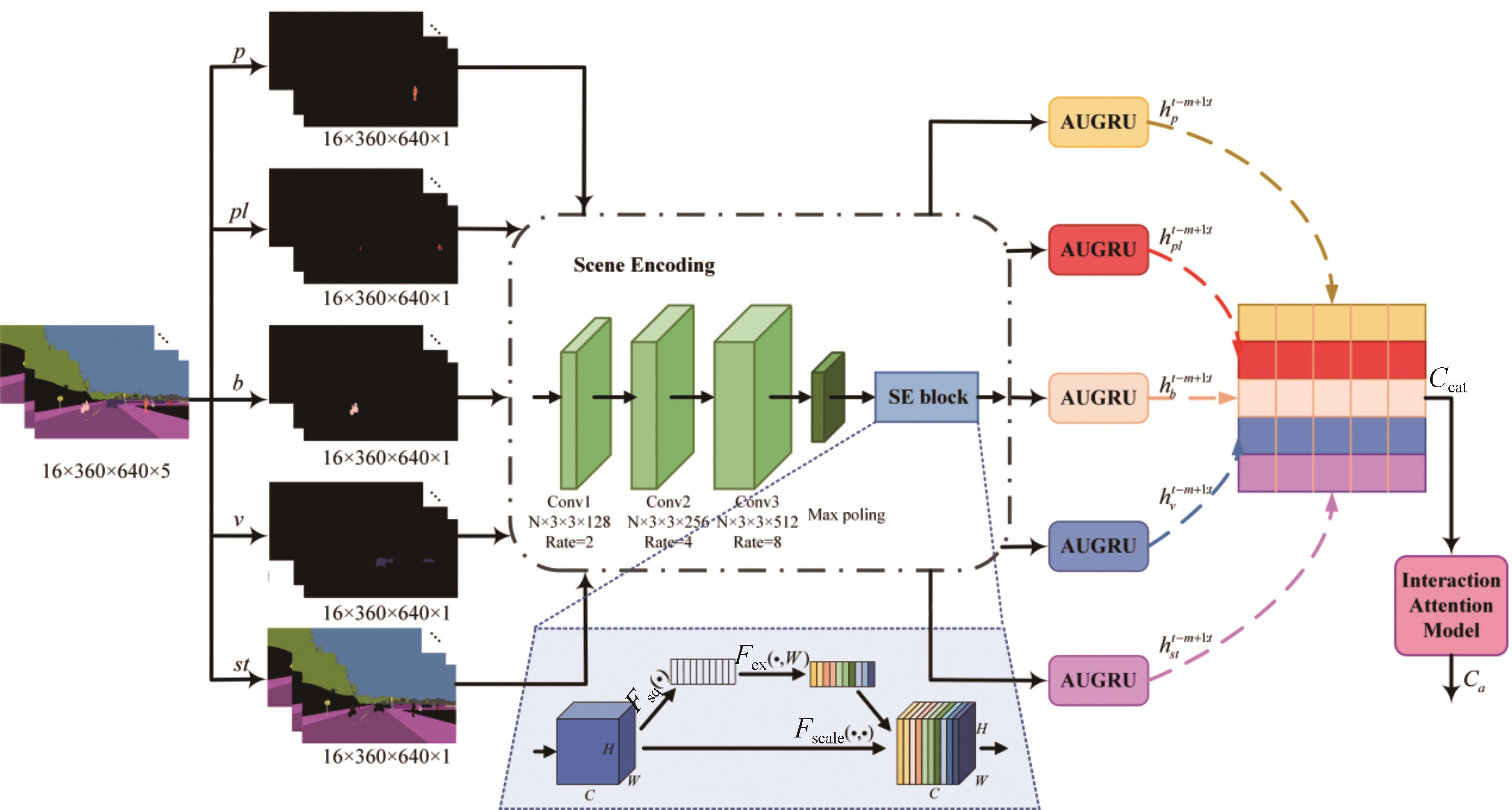

图5
局部场景时空特征提取模块"
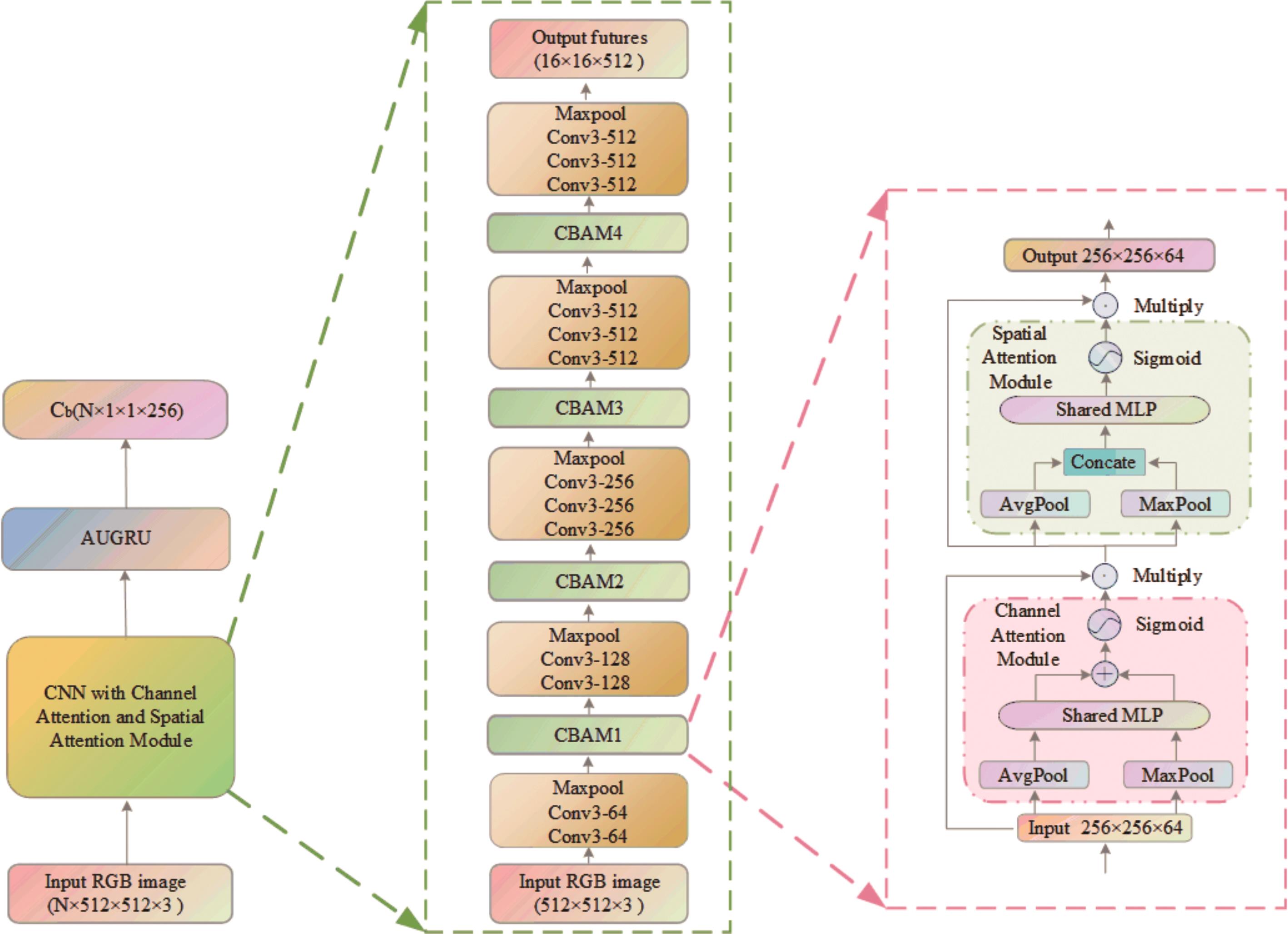

图6
4种融合策略对应示意图"

表1
JAADall上采用不同融合策略的模型对比试验"
| Fusion strategy | Acc | AUC | F1 | Pre | Recall |
|---|---|---|---|---|---|
| early-fusion | 0.740 | 0.788 | 0.537 | 0.590 | 0.861 |
| late-fusion | 0.750 | 0.788 | 0.541 | 0.631 | 0.844 |
| hierarchical-fusion | 0.812 | 0.806 | 0.591 | 0.567 | 0.846 |
| hiybrid-fusion | 0.836 | 0.825 | 0.633 | 0.620 | 0.808 |
表2
JAADbeh上采用不同融合策略的模型对比试验"
| Fusion strategy | Acc | AUC | F1 | Pre | Recall |
|---|---|---|---|---|---|
| early-fusion | 0.617 | 0.550 | 0.727 | 0.656 | 0.814 |
| late-fusion | 0.622 | 0.547 | 0.730 | 0.647 | 0.837 |
| hierarchical-fusion | 0.542 | 0.513 | 0.643 | 0.634 | 0.691 |
| hiybrid-fusion | 0.619 | 0.566 | 0.731 | 0.683 | 0.779 |
表3
多模态输入行人意图预测模型正交试验因素水平表"
| levels | ||||
|---|---|---|---|---|
| 1 | A1=Input | B1=Input | C1=Input | D1=Input |
| 2 | A2=Not Input | B2= Not Input | C2= Not Input | D2= Not Input |
表4
基于正交试验的行人意图预测试验数据分析计算表"
| Factors | A | B | C | D | Accuracy (JAADall) | Accuracy (JAADbeh) |
|---|---|---|---|---|---|---|
| Numbers | 1 | 2 | 3 | 4 | ||
| 1 | A1 | B1 | C1 | D1 | 0.836 | 0.619 |
| 2 | A1 | B1 | C1 | D2 | 0.824 | 0.622 |
| 3 | A1 | B2 | C2 | D1 | 0.786 | 0.609 |
| 4 | A1 | B2 | C2 | D2 | 0.774 | 0.597 |
| 5 | A2 | B1 | C2 | D1 | 0.802 | 0.605 |
| 6 | A2 | B1 | C2 | D2 | 0.787 | 0.584 |
| 7 | A2 | B2 | C1 | D1 | 0.766 | 0.563 |
| 8 | A2 | B2 | C1 | D2 | 0.750 | 0.557 |
| Ⅰ1 | 0.805 | 0.812 | 0.794 | 0.797 | T1=0.791 | T2=0.595 |
| Ⅱ1 | 0.776 | 0.769 | 0.787 | 0.784 | ||
| Range | 0.029 | 0.043 | 0.007 | 0.013 | ||
| Order | B、A、D、C | |||||
| Ⅰ2 | 0.612 | 0.608 | 0.590 | 0.599 | ||
| Ⅱ2 | 0.577 | 0.582 | 0.599 | 0.590 | ||
| Range | 0.035 | 0.026 | 0.009 | 0.009 | ||
| Order | A、B、C、D | |||||
表5
JAADall数据集上的定量结果"
| Models | Visual Encoder | Inputs | Main Fusion Approach | Accuracy | AUC | F1Score | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| SF-GRU | VGG+GRU | Box+BCD | hierarchical fusion | 0.76 | 0.77 | 0.53 | 0.40 | 0.79 |
| PCPA | 3DCNN | Box+BCD | later-fusion | 0.76 | 0.79 | 0.55 | 0.41 | 0.83 |
| Ours1 | VGG+GRU | Box+BCD | hierarchical-fusion | 0.80 | 0.81 | 0.59 | 0.49 | 0.81 |
| Ours2 | VGG+AUGRU | Box+BCD | hierarchical-fusion | 0.81 | 0.82 | 0.61 | 0.50 | 0.80 |
| Ours3 | VGG+AUGRU | Box+ABCD | hiybrid-fusion | 0.84 | 0.83 | 0.63 | 0.52 | 0.81 |
表6
JAADbeh数据集上的定量结果"
| Models | Visual Encoder | Inputs | Main Fusion Approach | Accuracy | AUC | F1Score | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| SF-GRU | VGG+GRU | Box+BCD | hierarchical-fusion | 0.58 | 0.56 | 0.65 | 0.68 | 0.62 |
| PCPA | 3DCNN | Box+BCD | later-fusion | 0.53 | 0.53 | 0.59 | 0.66 | 0.53 |
| Ours1 | VGG+GRU | Box+BCD | hierarchical-fusion | 0.60 | 0.56 | 0.71 | 0.67 | 0.81 |
| Ours4 | VGG+AUGRU | Box+BCD | hierarchical-fusion | 0.61 | 0.57 | 0.73 | 0.67 | 0.76 |
| Ours5 | VGG+AUGRU | Box+ABC | hiybrid-fusion | 0.62 | 0.57 | 0.73 | 0.69 | 0.78 |

图7
JAADall数据集上定量试验的ROC曲线"

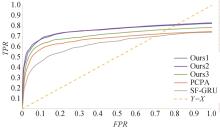
图8
JAADbeh数据集上定量试验的ROC曲线"
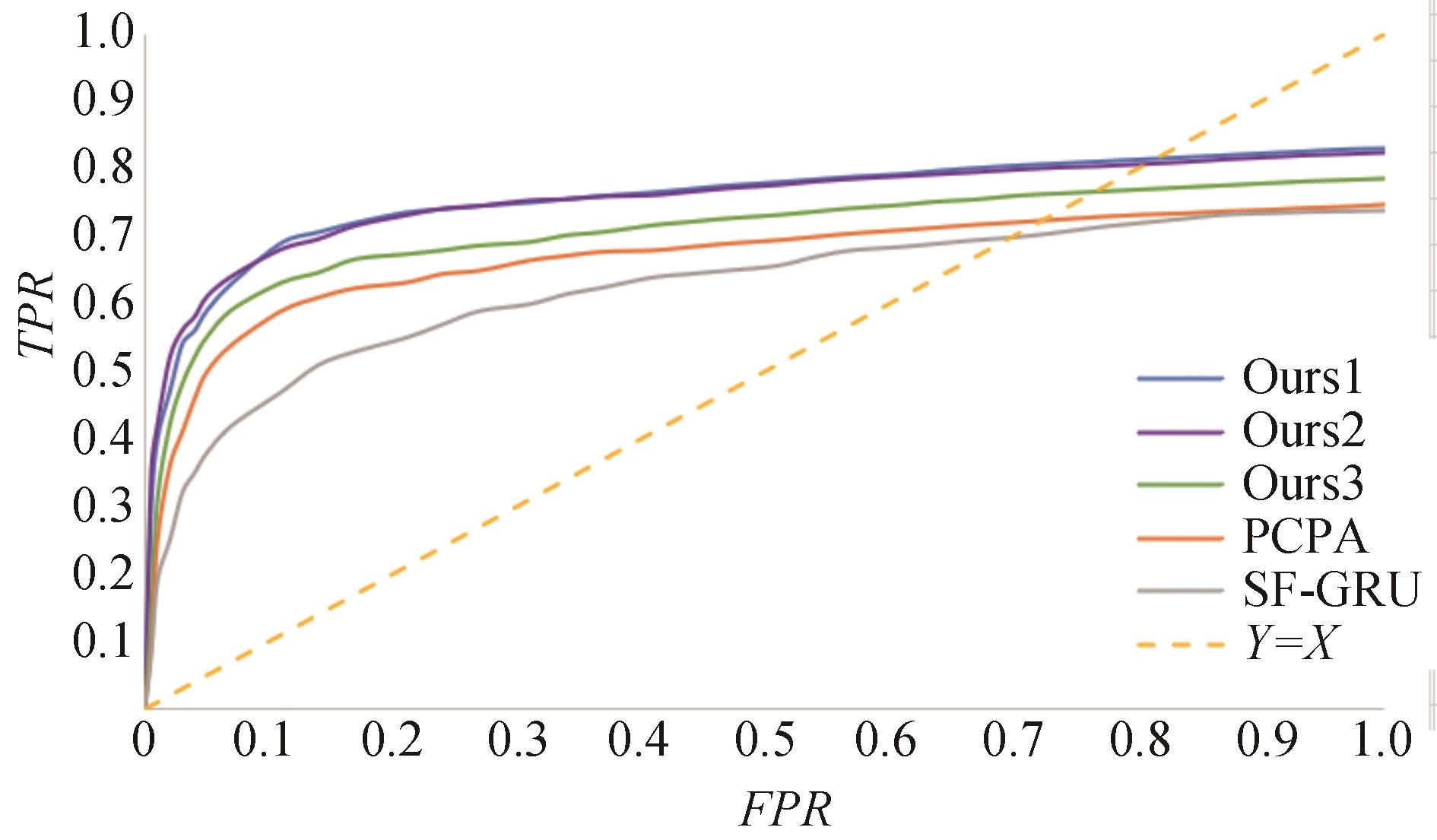

图9
该模型在JAAD数据集上的定性结果"

| 1 | 张亚丽.世界卫生组织发布《2018年全球道路安全现状报告》[J].中华灾害救援医学,2019, 7 (2): 100. |
| ZHANG Y. World health organization released “global road safety status report 2018” [J]. China Disaster Relief Medicine, 2019, 7(2): 100. | |
| 2 | 王辉. 行人过街时人-车交互特性分析与过街行为预测建模[D]. 西安: 长安大学,2021. |
| WANG H. Analysis of human-vehicle interaction characteristics and predictive modeling of crossing behavior when pedestrians cross the street [D]. Xi'an: Chang'an University, 2021. | |
| 3 | ALAHI A, GOEL K, RAMANATHAN V, et al. Social LSTM: human trajectory prediction in crowded spaces[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016: 961-971. |
| 4 | GUPTA A, JOHNSON J, FEI-FEI L, et al. Social GAN: socially acceptable trajectories with generative adversarial networks[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018: 2255-2264. |
| 5 | KOSARAJU V, SADEGHIAN A, MARTÍN-MARTÍN R, et al.Social-BiGAT: multimodal trajectory forecasting using bicycle-gan and graph attention networks[J]. Advances in Neural Information Processing Systems,2019, 32. |
| 6 | MOHAMED A, QIAN K, ELHOSEINY M, et al. Social-STGCNN: a social spatio-temporal graph convolutional neural network for human trajectory prediction[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2020: 14424-14432. |
| 7 | YAGI T, MANGALAM K, YONETANI R, et al. Future person localization in first-person videos[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018: 7593-7602. |
| 8 | QUINTERO R, PARRA I, LORENZO J, et al. Pedestrian intention recognition by means of a hidden markov model and body language[C]. 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC),2017: 1-7. |
| 9 | YU F, CHEN H, WANG X, et al. Bdd100k: a diverse driving dataset for heterogeneous multitask learning[C].Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2020: 2636-2645. |
| 10 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation,1997, 9 (8): 1735-1780. |
| 11 | FANG Z, LÓPEZ A M. Intention recognition of pedestrians and cyclists by 2D pose estimation[J].IEEE Transactions on Intelligent Transportation Systems,2019, 21 (11): 4773-4783. |
| 12 | ZHANG S, LIU X, XIAO J. On geometric features for skeleton-based action recognition using multilayer lstm networks[C].2017 IEEE Winter Conference on Applications of Computer Vision (WACV),2017: 148-157. |
| 13 | CADENA P R G, YANG M, QIAN Y, et al. Pedestrian graph: pedestrian crossing prediction based on 2D pose estimation and graph convolutional networks[C].2019 IEEE Intelligent Transportation Systems Conference (ITSC),2019: 2000-2005. |
| 14 | HUYNH M, ALAGHBAND G. GPRAR: graph convolutional network based pose reconstruction and action recognition for human trajectory prediction[J].arXiv preprint arXiv:,2021. |
| 15 | ALIAKBARIAN M S, SALEH F S, SALZMANN M, et al. VIENA: a driving anticipation dataset[C].Computer Vision-ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part I,2019: 449-466. |
| 16 | RASOULI A, KOTSERUBA I, TSOTSOS J K. Are they going to cross? a benchmark dataset and baseline for pedestrian crosswalk behavior[C].Proceedings of the IEEE International Conference on Computer Vision Workshops,2017: 206-213. |
| 17 | RASOULI A, KOTSERUBA I, KUNIC T, et al. Pie: a large-scale dataset and models for pedestrian intention estimation and trajectory prediction[C].Proceedings of the IEEE/CVF International Conference on Computer Vision,2019: 6262-6271. |
| 18 | PICCOLI F, BALAKRISHNAN R, PEREZ M J, et al. Fussi-Net: fusion of spatio-temporal skeletons for intention prediction network[C].2020 54th Asilomar Conference on Signals, Systems, and Computers,2020: 68-72. |
| 19 | RASOULI A, KOTSERUBA I, TSOTSOS J K. Pedestrian action anticipation using contextual feature fusion in stacked rnns[J].arXiv preprint arXiv:,2020. |
| 20 | KOTSERUBA I, RASOULI A, TSOTSOS J K. Benchmark for evaluating pedestrian action prediction[C].Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision,2021: 1258-1268. |
| 21 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C].Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13,2014: 740-755. |
| 22 | SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation[C].Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019: 5693-5703. |
| 23 | CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016: 3213-3223. |
| 24 | CHEN L C, PAPANDREOU G, SCHROFF F, et al.Rethinking atrous convolution for semantic image segmentation[J].arXiv preprint arXiv:,2017. |
| 25 | ZHOU G, MOU N, FAN Y, et al. Deep interest evolution network for click-through rate prediction[C].Proceedings of the AAAI Conference on Artificial Intelligence, 2019: 5941-5948. |
| 26 | CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[J].arXiv preprint arXiv:,2014. |
| 27 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132-7141. |
| 28 | YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[J].arXiv preprint arXiv:,2015. |
| 29 | LUONG M T, PHAM H, MANNING C D. Effective approaches to attention-based neural machine translation[J].arXiv preprint arXiv:,2015. |
| 30 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J].arXiv preprint arXiv:,2014. |
| 31 | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C].Proceedings of the European Conference on Computer Vision (ECCV),2018: 3-19. |
| 32 | RASOULI A, KOTSERUBA I, TSOTSOS J K. It's not all about size: on the role of data properties in pedestrian detection[C].Proceedings of the European Conference on Computer Vision (ECCV) Workshops,2018. |
| [1] | 付新科,蔡英凤,陈龙,王海,刘擎超. 不确定性环境下的自动驾驶汽车行为决策方法[J]. 汽车工程, 2024, 46(2): 211-221. |
| [2] | 李勇滔,孙晨旭,郑伟光,许恩永,李育方,王善超. 基于毫米波雷达与视觉融合的碰撞预警[J]. 汽车工程, 2023, 45(9): 1666-1676. |
| [3] | 朱向雷,吴志新,张宇飞,赵帅,李克秋,孙博华. 基于场景降维及采样方法的场景库优化方法研究[J]. 汽车工程, 2023, 45(8): 1408-1416. |
| [4] | 林程, 汪博文, 吕沛原, 宫新乐, 于潇. 面向变曲率道路的自动驾驶汽车换道博弈运动规划与协同控制研究[J]. 汽车工程, 2023, 45(7): 1099-1111. |
| [5] | 赵霞,李朝,付锐,葛振振,王畅. 基于深度卷积-Tokens降维优化视觉Transformer的分心驾驶行为实时检测[J]. 汽车工程, 2023, 45(6): 974-988. |
| [6] | 李琳辉,张鑫亮,付一帆,连静,马家旭. 基于TC-YOLOv7算法的可见光与红外后融合检测研究[J]. 汽车工程, 2023, 45(12): 2280-2290. |
| [7] | 张小俊,奚敬哲,史延雷,袁安录. 面向路侧视角目标检测的轻量级YOLOv7-R算法[J]. 汽车工程, 2023, 45(10): 1833-1844. |
| [8] | 朱冰,孙宇航,赵健,张培兴,范天昕,宋东鉴. 自动驾驶汽车测试场景基元自动提取方法[J]. 汽车工程, 2022, 44(11): 1647-1655. |
| [9] | 王大方,尚海,曹江,王涛,夏祥腾,韩雨霖. 基于自注意力机制的自动驾驶场景点云语义分割方法[J]. 汽车工程, 2022, 44(11): 1656-1664. |
| [10] | 张志勇,龙凯,杜荣华,黄彩霞. 自动驾驶汽车高速超车轨迹跟踪协调控制[J]. 汽车工程, 2021, 43(7): 995-1004. |
| [11] | 徐向阳,胡文浩,董红磊,王琰,肖凌云,李鹏辉. 自动驾驶汽车测试场景构建关键技术综述[J]. 汽车工程, 2021, 43(4): 610-619. |
| [12] | 刘军,陈岚磊,李汉冰. 基于类人视觉的多任务交通目标实时检测模型[J]. 汽车工程, 2021, 43(1): 50-58. |
| [13] | 蔡英凤, 邰康盛, 王海, 李祎承, 陈龙. 无人驾驶汽车周边车辆行为识别算法研究*[J]. 汽车工程, 2020, 42(11): 1464-1472. |
| [14] | 蔡英凤,臧勇,孙晓强,陈龙,王海,江浩斌,何友国. 自动驾驶汽车横向可拓预瞄切换控制系统研究*[J]. 汽车工程, 2018, 40(9): 1032-1039. |
|