汽车工程 ›› 2023, Vol. 45 ›› Issue (12): 2280-2290.doi: 10.19562/j.chinasae.qcgc.2023.12.010
所属专题: 智能网联汽车技术专题-感知&HMI&测评2023年
李琳辉1,2,张鑫亮1,付一帆1,连静1,2( ),马家旭1
),马家旭1
Linhui Li1,2,Xinliang Zhang1,Yifan Fu1,Jing Lian1,2(),Jiaxu Ma1
摘要:
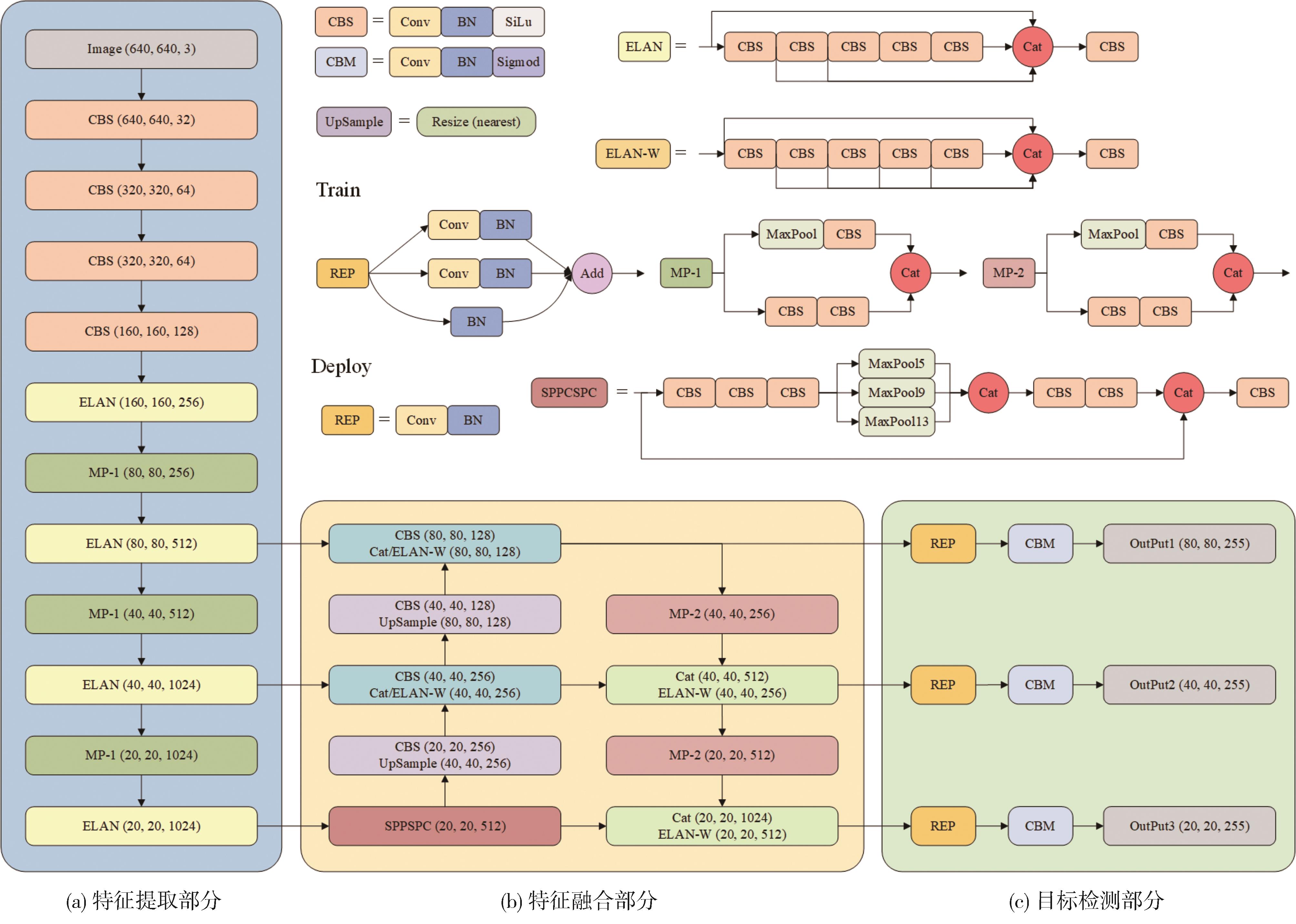
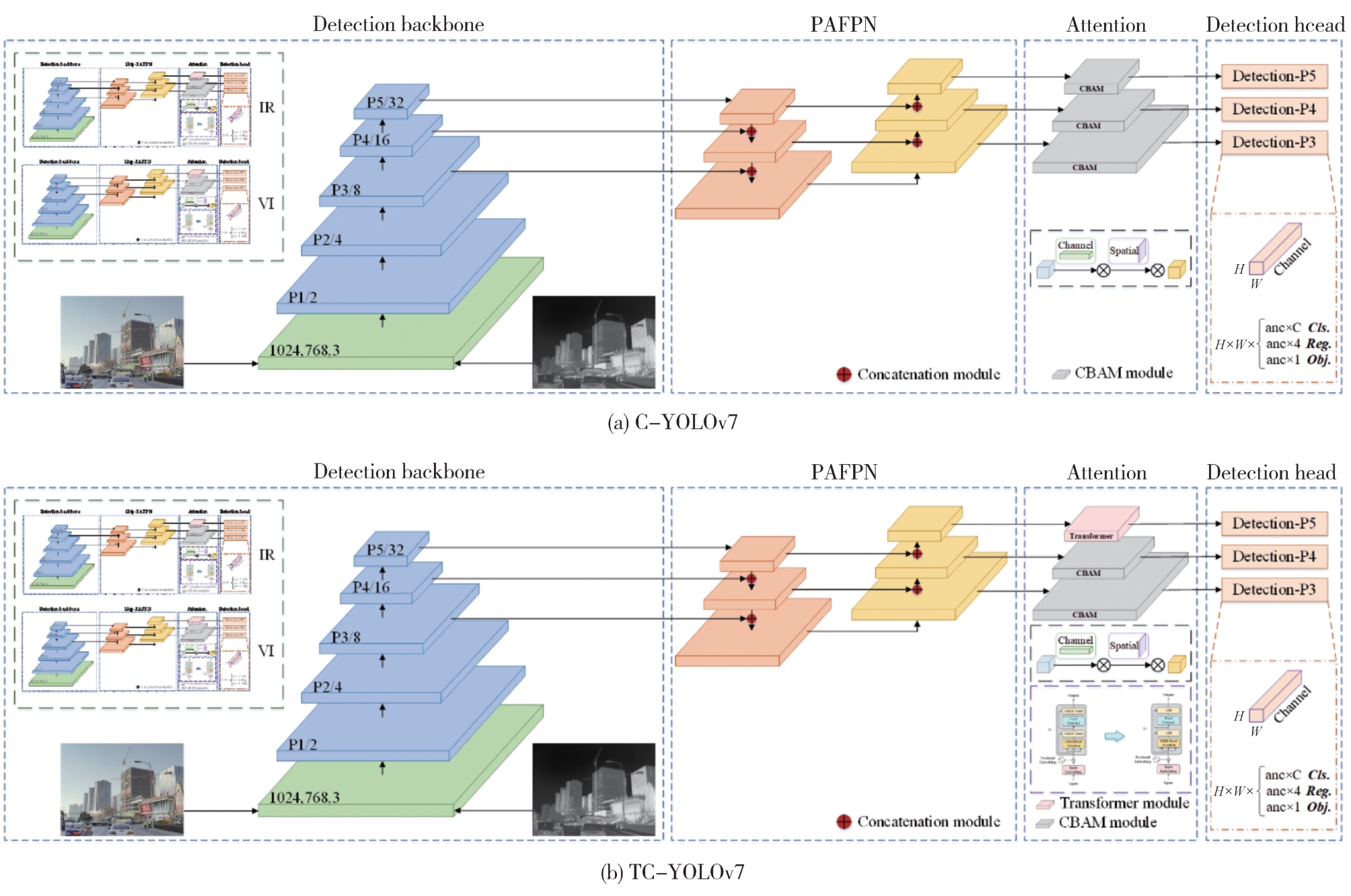
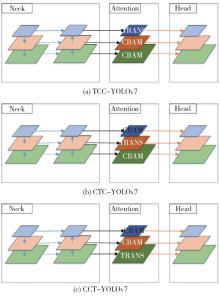
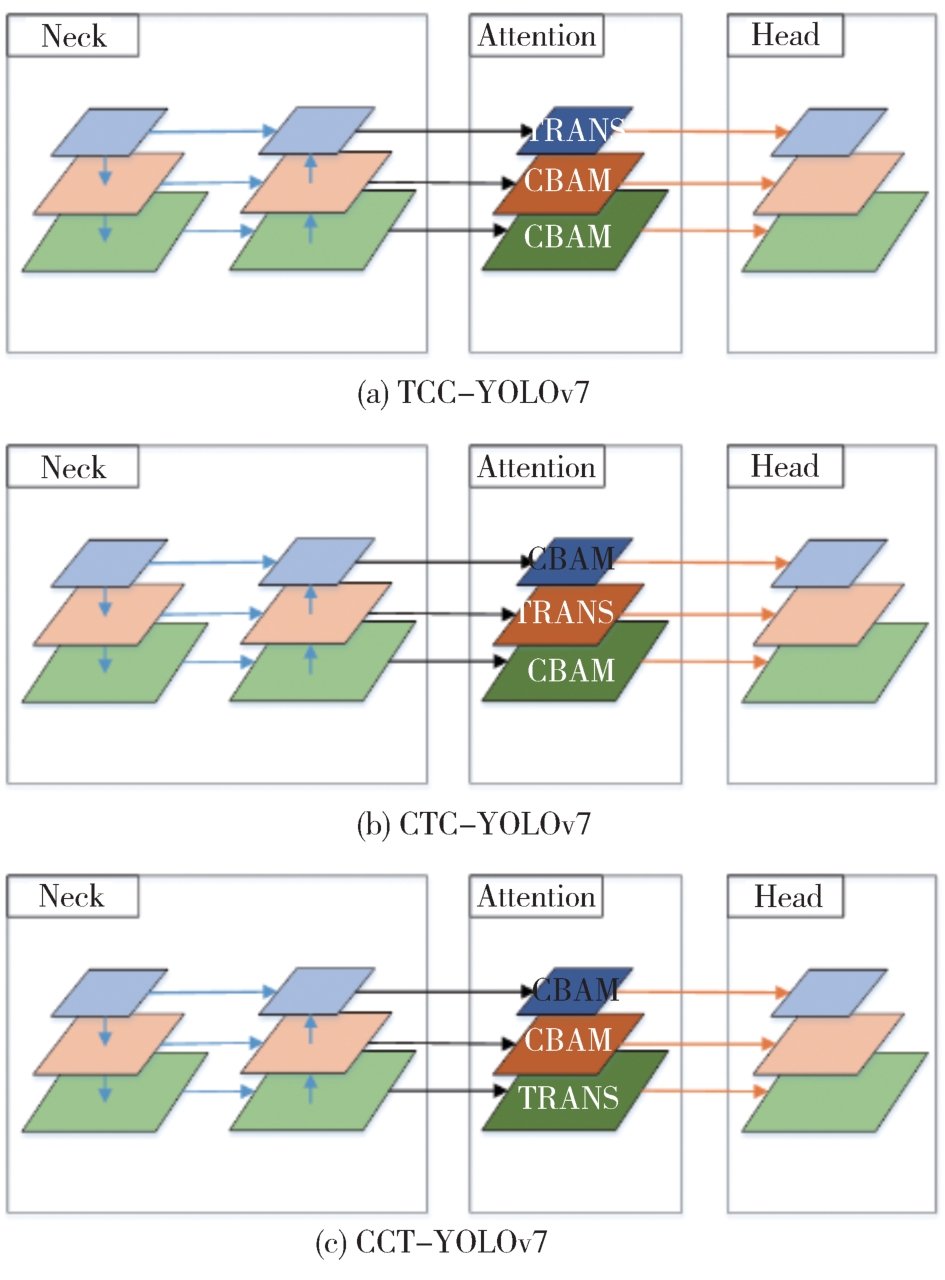
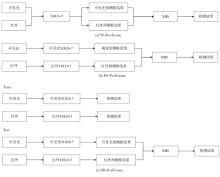
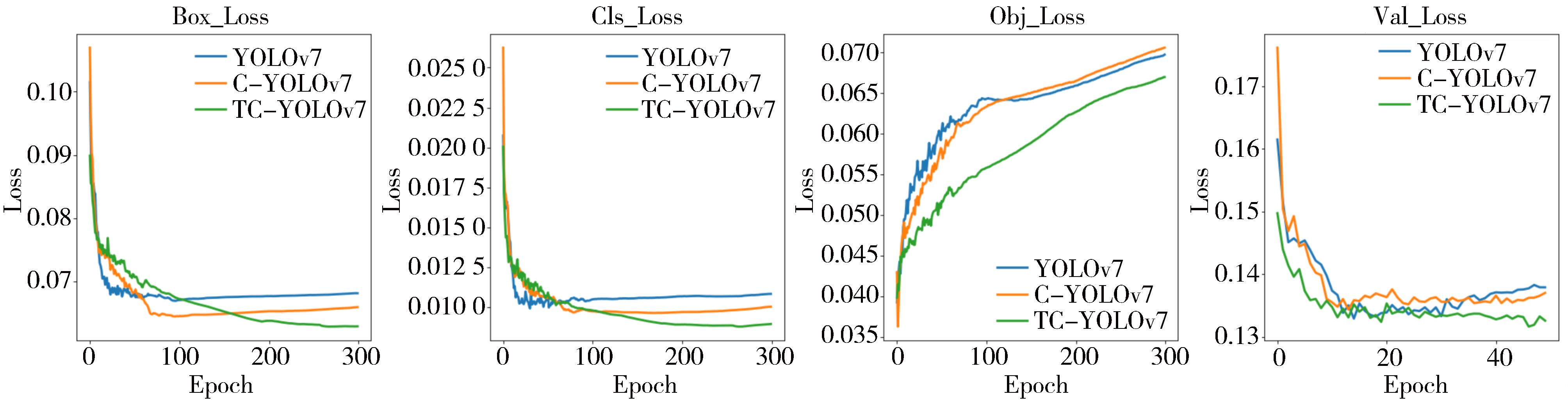
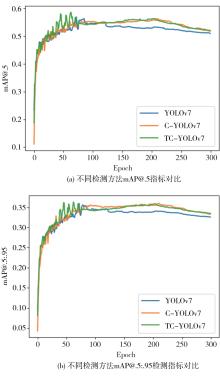
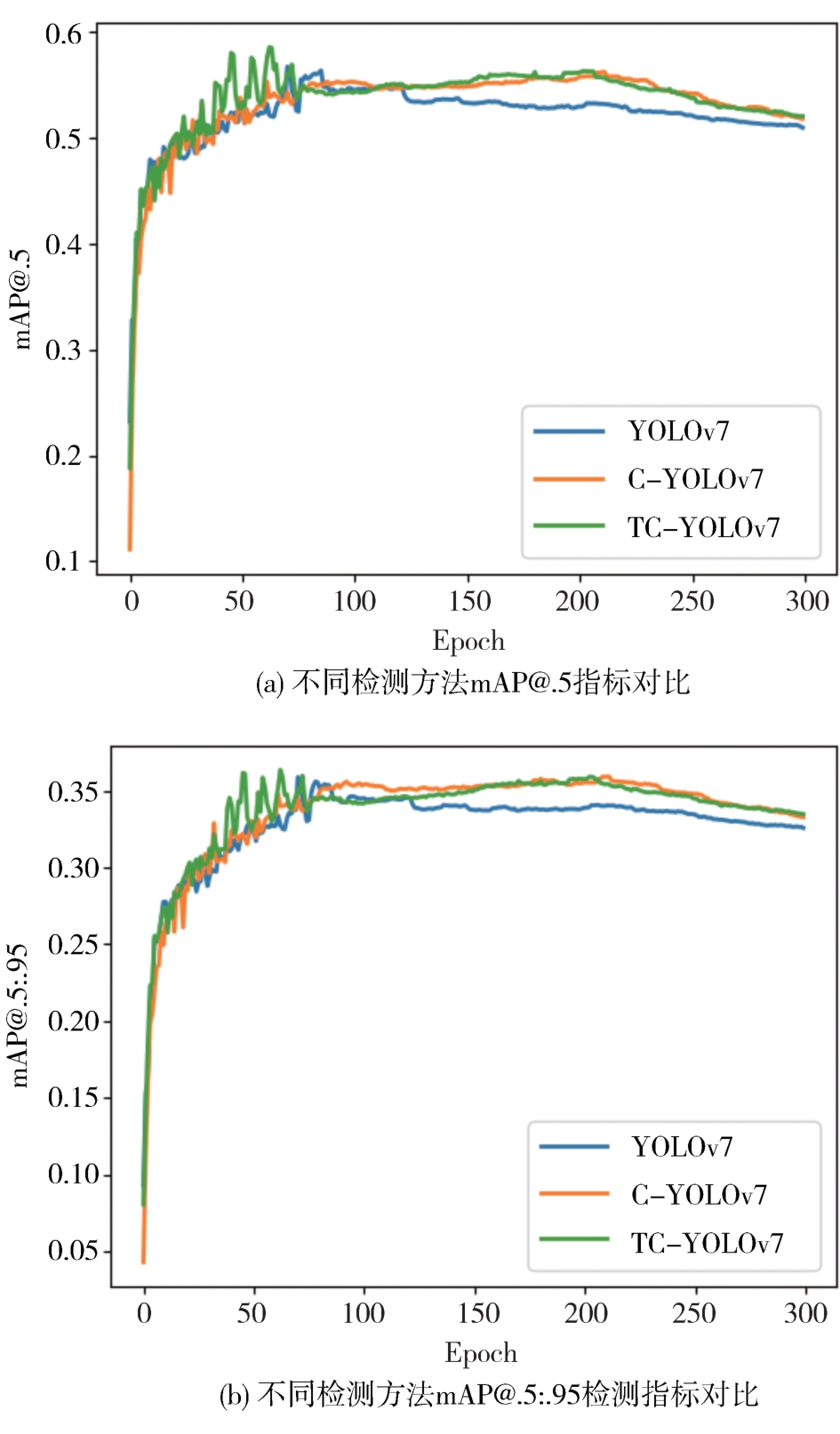
针对自动驾驶复杂场景下的视觉目标难以实现快速准确检测的问题,提出一种基于注意力机制的TC-YOLOv7检测算法,应用于可见光与红外以及后融合场景。首先,基于CBAM和Transformer注意力机制模块改进YOLOv7基准检测模型,并利用多场景数据集进行可见光和红外检测效果验证。其次,构建并验证SS-PostFusion、DS-PostFusion、DD-PostFusion 3种不同非极大值抑制后融合方法的检测效果。最后,结合TC-YOLOv7与DD-PostFusion方法,与单传感器检测结果进行对比。结果表明,在晴天、夜间、雾、雨、雪可见光和红外场景下,TC-YOLOv7相比基准YOLOv7 mAP@.5均有3%以上精度提升;在综合场景测试集中,使用TC-YOLOv7后融合方法相比可见光检测精度提升4.5%,相比红外检测精度提升11.1%,相比YOLOv7后融合方法提升0.6%,且TC-YOLOv7后融合方法的推理速度为39 fps,满足自动驾驶场景实时性要求。