汽车工程 ›› 2023, Vol. 45 ›› Issue (4): 527-540.doi: 10.19562/j.chinasae.qcgc.2023.04.001
所属专题: 智能网联汽车技术专题-规划&决策2023年
• • 下一篇
金立生,韩广德( ),谢宪毅,郭柏苍,刘国峰,朱文涛
),谢宪毅,郭柏苍,刘国峰,朱文涛
收稿日期:2022-10-10
修回日期:2022-11-15
出版日期:2023-04-25
发布日期:2023-04-19
通讯作者:
韩广德
E-mail:hangd@stumail.ysu.edu.cn
基金资助:
Lisheng Jin,Guangde Han(),Xianyi Xie,Baicang Guo,Guofeng Liu,Wentao Zhu
Received:2022-10-10
Revised:2022-11-15
Online:2023-04-25
Published:2023-04-19
Contact:
Guangde Han
E-mail:hangd@stumail.ysu.edu.cn
摘要:
强化学习的发展推动了自动驾驶决策技术的进步,智能决策技术已成为自动驾驶领域高度关注的要点问题。本文以强化学习算法发展为主线,综述该算法在单车自动驾驶决策领域的深入应用。对强化学习传统算法、经典算法和前沿算法从基本原理和理论建模等方面进行归纳总结与对比分析。针对不同场景的自动驾驶决策方法分类,分析环境状态可观测性对建模的影响,重点阐述了不同层次强化学习典型算法的应用技术路线,并对自动驾驶决策方法提出研究展望,以期为自动驾驶决策方案研究提供有益参考。
金立生,韩广德,谢宪毅,郭柏苍,刘国峰,朱文涛. 基于强化学习的自动驾驶决策研究综述[J]. 汽车工程, 2023, 45(4): 527-540.
Lisheng Jin,Guangde Han,Xianyi Xie,Baicang Guo,Guofeng Liu,Wentao Zhu. Review of Autonomous Driving Decision-Making Research Based on Reinforcement Learning[J]. Automotive Engineering, 2023, 45(4): 527-540.
表1
RL算法分类"
| 项目 | 基于模型 | 基于无模型 |
|---|---|---|
| 间接式 | DP, ADP, HDP, ADHDP, DHP, GDHP, ADGDHP, DGPI | MC, SARSA, TD, Q-learning, AC, A3C, DQN, GAE, DDQN, PER, Dueling DQN, C51, Rainbow, NAF |
| 直接式 | PILCO, GPS, 12A, MVE, STEVE | TRPO, PPO, DPG, DDPG, Off-PAC, ACER, REACTOR, IPG, TD3, SAC, Trust-PCL, SIL, APEX, IMPALA |
表2
DQN系列算法"
| 算法 | 主要思想 |
|---|---|
| DQN | Q函数神经网络化 |
| Double DQN[ | 双Q-learning |
| Dueling DQN[ | 对抗神经网络 |
| Prioritized DQN[ | 优先级经验 |
| Bootstrapped DQN[ | 深度探索 |
| Distributional DQN[ | 值函数分布 |
| Noisy DQN[ | 噪声网络 |
| Rainbow DQN[ | 6种改进方法融合 |
表3
MFRL典型算法更新"
| 算法 | 提出时间 | 算法类型 | 主要思想 | 适用场景 | 主要优缺点 |
|---|---|---|---|---|---|
| TRPO[ | 2015 | 基于策略 | 新旧策略增加策略参数变化约束 | 离散/连续 动作空间 | 优点:模型可靠度高,策略可以实现单调递增 缺点:算法过于复杂 |
| A3C[ | 2016 | 基于AC | 多个线程同步训练 | 离散/连续 动作空间 | 优点:可用CPU多线程,资源消耗少,降低交互数据相关性 缺点:各Agent为异步独立更新,其不同策略可能导致全局网络策略的更新效果并非最优 |
| A2C[ | 2017 | 基于AC | 优势函数 | 离散/连续 动作空间 | 优点:利用优势函数解决高方差问题 缺点:交互数据的相关性,影响收敛效果 |
| PPO[ | 2017 | 基于策略 | 设置目标函数限制更新幅度范围 | 离散/连续 动作空间 | 优点:实现简单,适用范围广 缺点:Actor和Critic网络均只包含两层全连接层,在高维状态空间的应用中学习能力易下降 |
| TD3[ | 2018 | 基于AC | double Q-Learning 融入DDPG | 连续 动作空间 | 优点:优化DDPG算法高估Q值的问题,训练更加稳定 缺点:训练时随机采样的数据质量残次不齐,效果受影响[ |
| SAC[ | 2018 | 基于AC | 熵正则化 soft策略迭代 | 连续 动作空间 | 优点:探索性和鲁棒性得到提升 缺点:等概率随机采样, 网络随机初始化,造成训练速度慢, 训练过程不稳定[ |
表4
车道保持任务State、Action等设置"
| 名称 | 参数 |
|---|---|
| State | 横向偏移量(车辆质心与车道中心线的相对距离) 相对偏航角(车辆中心线与道路中心的夹角) (可选)导航信息(参考路径、路径曲率等) (可选)地图信息 |
| Action | 前轮转角、车速 |
| Reward | 安全性(碰撞、相对偏航角、相对横向位置等) 效率(纵向车速、耗时等) 舒适性(横向加速度、横摆角速度等) |
表5
跟驰任务State、Action等设置"
| 名称 | 参数 |
|---|---|
| State | 前方车辆、主车、周车的基本信息(包含纵向加速度、纵向速度、相对速度、相对距离等参数) 导航信息(参考路径、路径曲率等) 地图信息 |
| Action | 车辆纵向控制量(加速踏板开度、制动踏板开度或最大驱动力矩、最大制动压力) 转向盘转角或前轮转角 |
| Reward | 安全性(车速、加减速逻辑、最小安全距离等) 效率(跟车间距) 舒适性(加/减速度、加速度变化率等) (可选)驾驶风险 (可选)个性化(驾驶特性拟人化) |
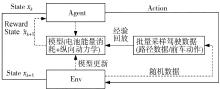
图1
考虑道路坡度与跟车距离的巡航速度策略"
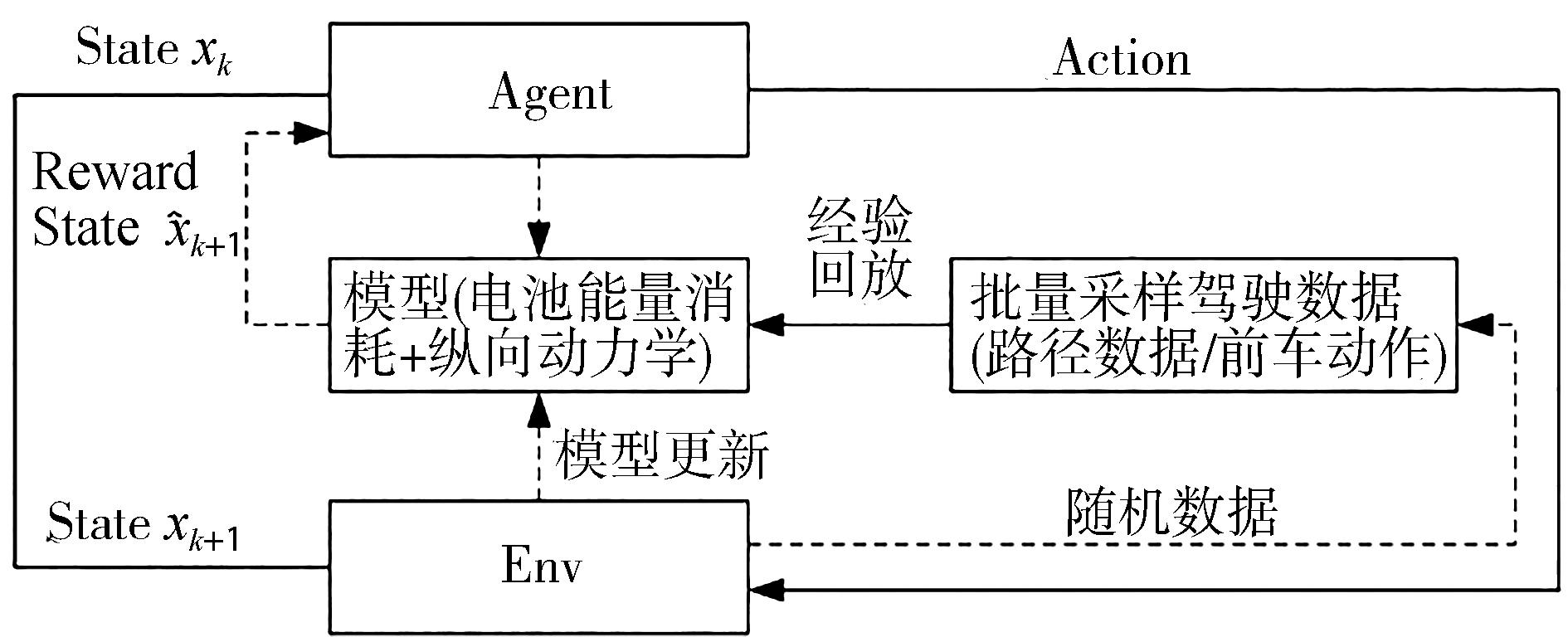
图2
POMDP决策应用框架[68]"
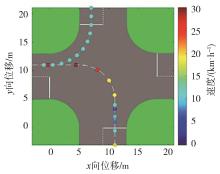
图3
基于关键点转向示意图"

表6
RL主要前沿方向"
| 算法 | 主要思想 | 常见算法 |
|---|---|---|
| IRL | 反向推理出Reward,Agent通过专家示范来学习如何决策复杂问题 | 最大规划[ |
| HRL | 采用逐步实现目标或多级控制这种分而治之思想,将复杂问题分解成若干子问题分而治之 | Option-Critic[ HIRO[ |
| Meta RL | 从过去的任务中获取历史经验,从而迅速适应新任务并得到相应最优策略 | Meta-RL[ Reptile[ |
| Offline RL | Agent不与环境交互的情况下,仅从获取的数据学习经验知识 | BEAR[ |
| MTDRL | 基于共享表示,把多个相关的任务放在一起学习 | PathNet[ |
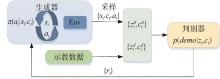
图4
GAIL结构图"
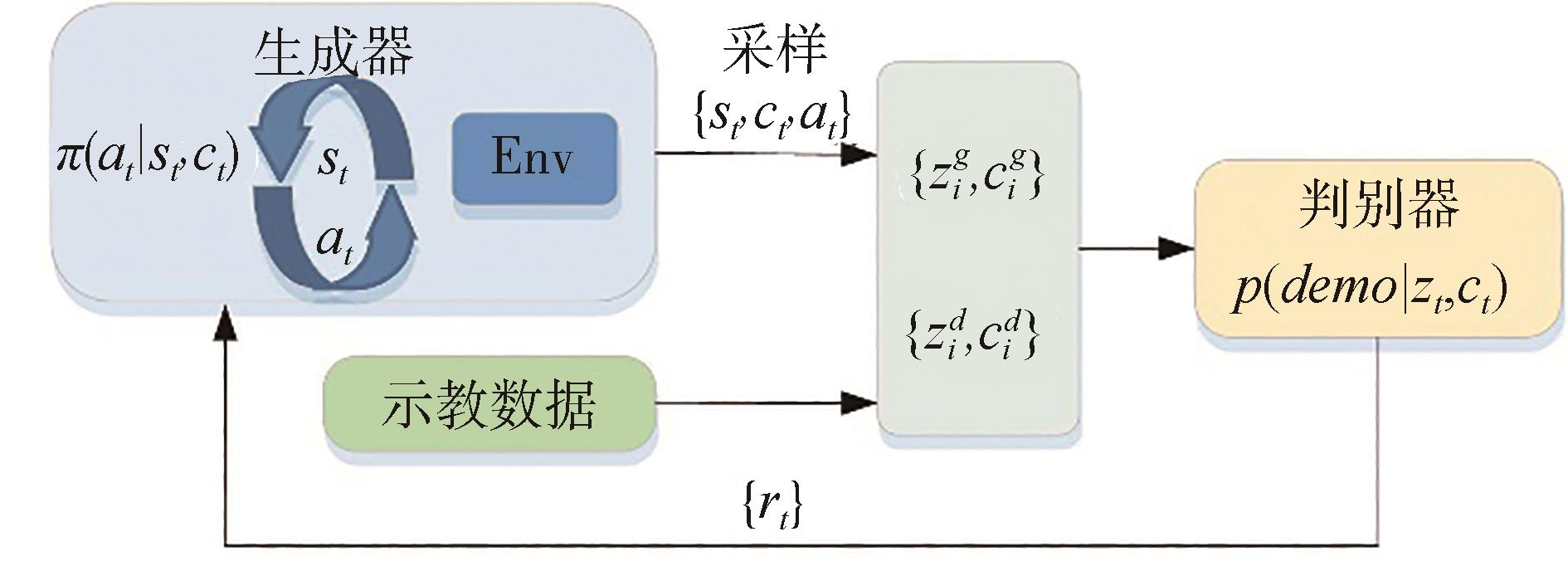

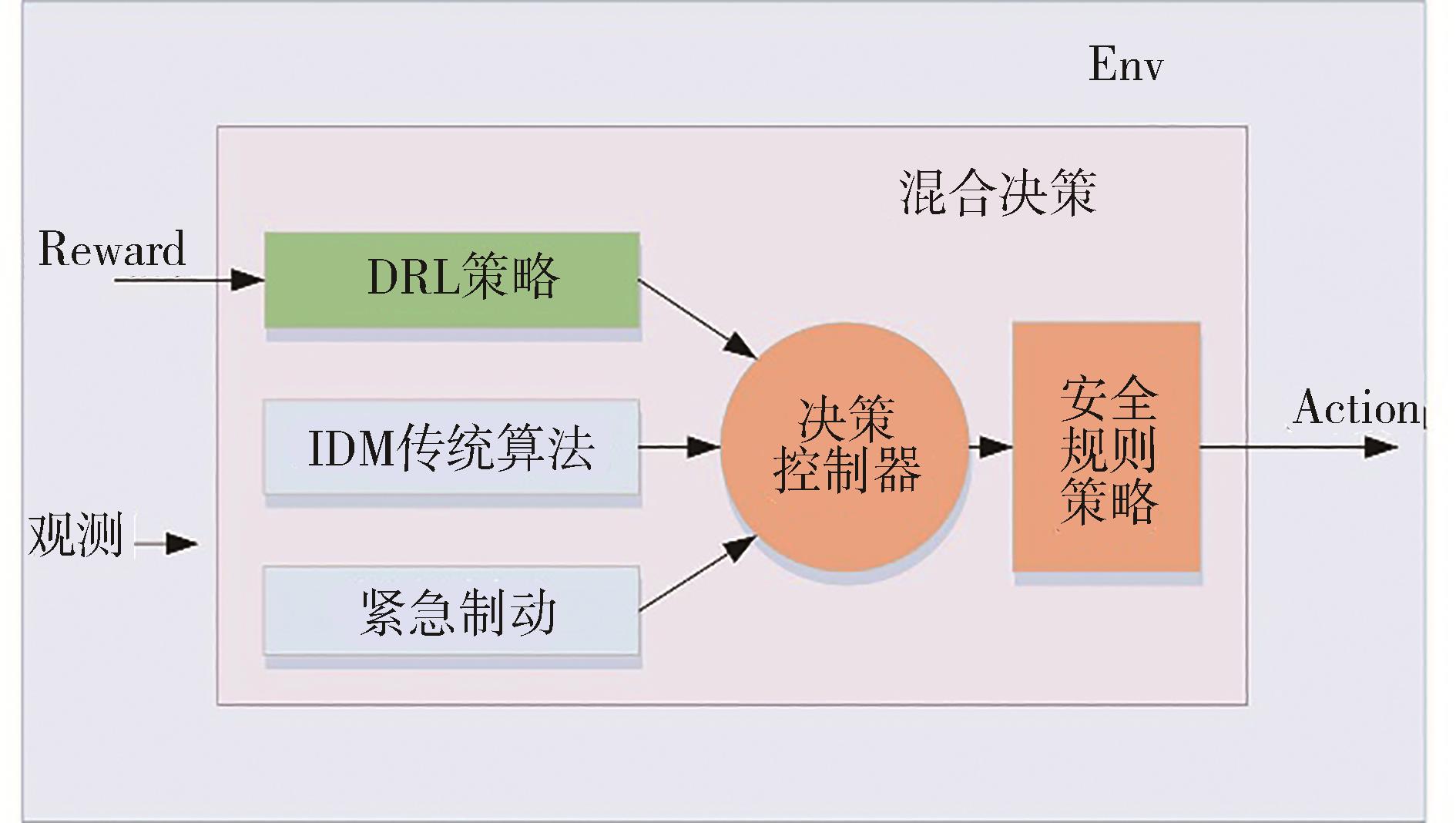
图5
基于规则和RL协作策略框架"
| 1 | RAHIM M A, RAHMAN M A, RAHMAN M M, et al. Evolution of IoT-enabled connectivity and applications in automotive industry: a review[J]. Vehicular Communications, 2021, 27: 100285. |
| 2 | MA Y, WANG Z, YANG H, et al. Artificial intelligence applications in the development of autonomous vehicles: a survey[J]. IEEE/CAA Journal of AutomaticaSinica, 2020, 7(2): 315-329. |
| 3 | 高振海, 闫相同, 高菲, 等. 仿驾驶员DDPG汽车纵向自动驾驶决策方法[J]. 汽车工程, 2021, 43(12): 1737-1744. |
| GAO Z H, YAN X T, GAO F, et al. A driver-like decision-making method for longitudinal autonomous driving based on DDPG[J]. Automotive Engineering, 2021, 43(12): 1737-1744. | |
| 4 | 杨殿阁, 黄晋, 江昆, 等. 汽车自动驾驶[M]. 北京: 清华大学出版社, 2022: 348-350. |
| YANG D G, HUANG J, JIANG K, et al. Automotive autonomous driving[M]. Beijing: Tsinghua University Press, 2022: 348-350. | |
| 5 | HUSSONNOIS M, JUN J Y. End-to-end autonomous driving using the Ape-X algorithm in Carla simulation environment[C]. 2022 Thirteenth International Conference on Ubiquitous and Future Networks (ICUFN), IEEE, 2022: 18-23. |
| 6 | CHOPRA R, ROY S S. End-to-end reinforcement learning for self-driving car[M]. Singapore: Advanced Computing and Intelligent Engineering, 2020: 53-61. |
| 7 | LI Q, PENG H, LI J, et al. A survey on text classification: from traditional to deep learning[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2022, 13(2): 1-41. |
| 8 | ZHU Z, ZHAO H. A survey of deep rl and il for autonomous driving policy learning[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(9): 14043-14065. |
| 9 | KAELBLING L P, LITTMAN M L, MOORE A W. Reinforcement learning: a survey[J]. Journal of Artificial Intelligence Research, 1996, 4: 237-285. |
| 10 | MINSKY M L. Theory of neural-analog reinforcement systems and its application to the brain-model problem[D]. New Jersey: Princeton University, 1954. |
| 11 | BELLMAN R E. Dynamic programming[M]. Princeton, Princeton University Press, 1957:86-122. |
| 12 | HOWARD R A. Dynamic programming and Markov process[M]. Cambridge: MIT Press, 1960: 32-42. |
| 13 | WALTZ W G, FU K S. A heuristic approach to reinforcement control systems[J]. IEEE Transactions on Automatic Control, 1965, 10(4): 390-398. |
| 14 | SUTTON R S. Learning to predict by the method of temporal difference[J]. Machine Learning, 1988, 3(1): 9-44. |
| 15 | WATKINS C J C H. Learning from delayed rewards[D]. Cambridge: University of Cambridge, 1989. |
| 16 | RUMMERY G A, NIRANJAN M. On-line q-learning using connectionist systems[R]. Department of Engineering, University of Cambridge, 1994. |
| 17 | BERTSEKAS D P, TSITSIKLIS J N. Neuro-dynamic programming: an overview[C]. Proceedings of 1995 34th IEEE Conference on Decision and Control. IEEE, 1995, 1: 560-564. |
| 18 | KOCSIS L, SZEPESVÁRI C. Bandit based monte-carlo planning[C]. European Conference on Machine Learning. Springer, Berlin, Heidelberg, 2006: 282-293. |
| 19 | KOCSIS L, SZEPESVÁRI C. Bandit based monte-carlo planning[C]. 2016 17th European Conference on Machine Learning, 2006: 282-293. |
| 20 | 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 北京: 人民邮电出版社, 2022: 348-350. |
| ZHANG W N, SHEN J, YU Y. Hands-on reinforcement learning[M]. Beijing: Posts & Telecom Press, 2022: 348-350. | |
| 21 | PYEATT L D, HOWE A E. Learning to race: experiments with a simulated race car[C]. FLAIRS Conference, 1998: 357-361. |
| 22 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. |
| 23 | WOLF P, HUBSCHNEIDER C, WEBER M, et al. Learning how to drive in a real world simulation with deep q-networks[C]. 2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017: 244-250. |
| 24 | GLÄSCHER J, DAW N, DAYAN P, et al. States versus rewards: dissociable neural prediction error signals underlying model-based and model-free reinforcement learning[J]. Neuron, 2010, 66(4): 585-595. |
| 25 | GUAN Y, LI S E, DUAN J, et al. Direct and indirect reinforcement learning[J]. International Journal of Intelligent Systems, 2021, 36(8): 4439-4467. |
| 26 | FARAZI N P, ZOU B, AHAMED T, et al. Deep reinforcement learning in transportation research: a review[J]. Transportation Research Interdisciplinary Perspectives, 2021, 11(12): 100425. |
| 27 | HASSELT H V, GUEZ A, SILVER D. Deep reinforcement learning with double q-learning[C]. Proceedings of the AAAI Conference on Artificial Intelligence, 2016: 2094-2100. |
| 28 | WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2016: 1995-2003. |
| 29 | SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay[J]. arXiv Preprint arXiv:, 2015. |
| 30 | OSBAND I, BLUNDELL C, PRITZEL A, et al. Deep exploration via bootstrapped DQN[C]. Advances in Neural Information Processing Systems29, 2016: 4026-4034. |
| 31 | BELLEMARE M G, DABNEY W, MUNOS R. A distributional perspective on reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2017: 449-458. |
| 32 | FORTUNATO M, AZAR M G, PIOT B, et al. Noisy networks for exploration[J]. arXiv Preprint arXiv:, 2017. |
| 33 | HESSEL M, MODAYIL J, VAN HASSELT H, et al. Rainbow: combining improvements in deep reinforcement learning[C]. Thirty-second AAAI Conference on Artificial Intelligence, 2018: 3215-3222. |
| 34 | WANG H, LIU N, ZHANG Y, et al. Deep reinforcement learning: a survey[J]. Frontiers of Information Technology & Electronic Engineering, 2020, 21(12): 1726-1744. |
| 35 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J]. arXiv Preprint arXiv:, 2015. |
| 36 | WITTEN I H. An adaptive optimal controller for discrete-time Markov environments[J]. Information and Control, 1977, 34(4): 286-295. |
| 37 | BARTO A G, SUTTON R S, ANDERSON C W. Neuronlike adaptive elements that can solve difficult learning control problems[J]. IEEE Transactions on Systems, Man and Cybernetics, 1983, (5): 834-846. |
| 38 | KONDA V, TSITSIKLIS J. Actor-critic algorithms[J]. Advances in Neural Information Processing Systems, 1999(12): 1008-1014. |
| 39 | SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization[C]. International Conference on Machine Learning. PMLR, 2015: 1889-1897. |
| 40 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2016: 1928-1937. |
| 41 | CHRISTIANO P F, LEIKE J, BROWN T B, et al. Deep reinforcement learning from human preferences[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 4302-4310. |
| 42 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J]. arXiv Preprint arXiv: , 2017. |
| 43 | FUJIMOTO S, HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[C]. International Conference on Machine Learning. PMLR, 2018: 1587-1596. |
| 44 | 唐蕾, 刘广钟. 改进TD3算法在四旋翼无人机避障中的应用[J]. 计算机工程与应用, 2021, 57(11): 254-259. |
| TANG L, LIU G Z. Application for improved TD3 algorithm in obstacle avoidance of quad-rotor UAV[J]. Computer Engineering and Applications, 2021, 57(11): 254-259. | |
| 45 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]. International Conference on Machine Learning. PMLR, 2018: 1861-1870. |
| 46 | 刘庆强, 刘鹏云. 基于优先级经验回放的SAC强化学习算法[J]. 吉林大学学报(信息科学版), 2021, 39(2): 192-199. |
| LIU Q Q, LIU P Y. Soft actor critic reinforcement learning with prioritized experience replay[J]. Journal of Jilin University (Information Science Edition), 2021, 39(2): 192-199. | |
| 47 | XIONG X, WANG J, ZHANG F, et al. Combining deep reinforcement learning and safety based control for autonomous driving[J]. arXiv Preprint arXiv: , 2016. |
| 48 | SALLAB A E, ABDOU M, PEROT E, et al. End-to-end deep reinforcement learning for lane keeping assist[J]. arXiv Preprint arXiv:, 2016. |
| 49 | SAXENA D M, BAE S, NAKHAEI A, et al. Driving in dense traffic with model-free reinforcement learning[C]. 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020: 5385-5392. |
| 50 | HUANG Z, ZHANG J, TIAN R, et al. End-to-end autonomous driving decision based on deep reinforcement learning[C]. 2019 5th International Conference on Control, Automation and Robotics (ICCAR). IEEE, 2019: 658-662. |
| 51 | 朱冰, 蒋渊德, 赵健, 等. 基于深度强化学习的车辆跟驰控制[J]. 中国公路学报, 2019, 32(6): 53-60. |
| ZHU B, JIANG Y D, ZHAO J, et al. A car-following control algorithm based on deep reinforcement learning[J]. China Journal of Highway and Transport, 2019, 32(6): 53-60. | |
| 52 | GAO Z H, SUN T J, XIAO H W, et al.Decision-making method for vehicle longitudinal automatic driving based on reinforcement Q-learning[J]. International Journal of Advanced Robotic Systems, 2019, 16(3): 1-13. |
| 53 | VECERIK M, HESTER T, SCHOLZ J, et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards[J]. arXiv Preprint arXiv: , 2017. |
| 54 | LIU H, HUANG Z, WU J, et al. Improved deep reinforcement learning with expert demonstrations for urban autonomous driving[C]. 2022 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2022: 921-928. |
| 55 | LI D, OKHRIN O. DDPG car-following model with real-world human driving experience in CARLA[J]. arXiv Preprint arXiv: , 2021. |
| 56 | TANG X, HUANG B, LIU T, et al. Highway decision-making and motion planning for autonomous driving via soft actor-critic[J]. IEEE Transactions on Vehicular Technology, 2022, 71(5): 4706-4717. |
| 57 | LIU X, LI H, WANG J, et al. Personalized automatic driving system based on reinforcement learning technology[C]. 2019 4th International Conference on Mechanical, Control and Computer Engineering (ICMCCE). IEEE, 2019: 373-3733. |
| 58 | LI G, YANG Y, LI S, et al. Decision making of autonomous vehicles in lane change scenarios: deep reinforcement learning approaches with risk awareness[J]. Transportation Research Part C: Emerging Technologies, 2022, 134: 103452. |
| 59 | WANG P, CHAN C Y. Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge[C]. 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2017: 1-6. |
| 60 | LIN Y, MCPHEE J, AZAD N L. Anti-jerk on-ramp merging using deep reinforcement learning[C]. 2020 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2020: 7-14. |
| 61 | LI G, LIN S, LI S, et al. Learning automated driving in complex intersection scenarios based on camera sensors: a deep reinforcement learning approach[J]. IEEE Sensors Journal, 2022, 22(5): 4687-4696. |
| 62 | KARGAR E, KYRKI V. Vision transformer for learning driving policies in complex and dynamic environments[C]. 2022 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2022: 1558-1564. |
| 63 | KAMRAN D, LOPEZ C F, LAUER M, et al. Risk-aware high-level decisions for automated driving at occluded intersections with reinforcement learning[C]. 2020 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2020: 1205-1212. |
| 64 | POLYDOROS A S, NALPANTIDIS L. Survey of model-based reinforcement learning: applications on robotics[J]. Journal of Intelligent & Robotic Systems, 2017, 86(2): 153-173. |
| 65 | SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search [J]. Nature, 2016, 529(7587): 484=489. |
| 66 | PUCCETTI L, YASSER A, RATHGEBER C, et al. Speed tracking control using model-based reinforcement learning in a real vehicle[C]. 2021 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2021: 1213-1219. |
| 67 | LEE H, KIM K, KIM N, et al. Energy efficient speed planning of electric vehicles for car-following scenario using model-based reinforcement learning[J]. Applied Energy, 2022, 313:118460. |
| 68 | ARADI S. Survey of deep reinforcement learning for motion planning of autonomous vehicles[J]. arXiv e-prints, 2020: arXiv: . |
| 69 | SEILER K M, KURNIAWATI H, SINGH S P N. An online and approximate solver for POMDPs with continuous action space[C]. 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015: 2290-2297. |
| 70 | BAI H, CAI S, YE N, et al. Intention-aware online POMDP planning for autonomous driving in a crowd[C]. 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015: 454-460. |
| 71 | HOEL C J, DRIGGS-CAMPBELL K, WOLFF K, et al. Combining planning and deep reinforcement learning in tactical decision making for autonomous driving[J]. IEEE Transactions on Intelligent Vehicles, 2019, 5(2): 294-305. |
| 72 | SHU K, YU H, CHEN X, et al. Autonomous driving at intersections: a behavior-oriented critical-turning-point approach for decision making[J]. IEEE/ASME Transactions on Mechatronics, 2021, 27(1): 234-244. |
| 73 | ARORA S, DOSHI P. A survey of inverse reinforcement learning: challenges, methods and progress[J]. Artificial Intelligence, 2021, 297: 103500. |
| 74 | BARTO A G, MAHADEVAN S. Recent advances in hierarchical reinforcement learning[J]. Discrete Event Dynamic Systems, 2003, 13(1): 41-77. |
| 75 | SCHWEIGHOFER N, DOYA K. Meta-learning in reinforcement learning[J]. Neural Networks, 2003, 16(1): 5-9. |
| 76 | LEVINE S, KUMAR A, TUCKER G, et al. Offline reinforcement learning: tutorial, review, and perspectives on open problems[J]. arXiv Preprint arXiv:, 2020. |
| 77 | WILSON A, FERN A, RAY S, et al. Multi-task reinforcement learning: a hierarchical bayesian approach[C]. Proceedings of the 24th International Conference on Machine Learning, 2007: 1015-1022. |
| 78 | GUAN Y, REN Y, MA H, et al. Learn collision-free self-driving skills at urban intersections with model-based reinforcement learning[C]. 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021: 3462-3469. |
| 79 | TAYLOR M E, STONE P. Transfer learning for reinforcement learning domains: a survey[J]. Journal of Machine Learning Research, 2009, 10(7): 1633-1685 |
| 80 | DONG D, CHEN C, LI H, et al. Quantum reinforcement learning[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2008, 38(5): 1207-1220. |
| 81 | BELLEMARE M G, DABNEY W, MUNOS R. A distributional perspective on reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2017: 449-458. |
| 82 | PARISOTTO E, SONG F, RAE J, et al. Stabilizing transformers for reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2020: 7487-7498. |
| 83 | AMODEI D, OLAH C, STEINHARDT J, et al. Concrete problems in AI safety[J]. arXiv Preprint arXiv:, 2016. |
| 84 | STRENS M. A Bayesian framework for reinforcement learning[C]. Proc. of the 17th Intl. Conf. on Machine Learning (ICML), 2000: 943-950. |
| 85 | PUIUTTA E, VEITH E. Explainable reinforcement learning: a survey[C]. International Cross-domain Conference for Machine Learning and Knowledge Extraction. Springer, Cham, 2020: 77-95. |
| 86 | RATLIFF N D, BAGNELL J A, ZINKEVICH M A. Maximum margin planning[C]. Proceedings of the 23rd International Conference on Machine Learning, 2006: 729-736. |
| 87 | ZIEBART B D, MAAS A L, BAGNELL J A, et al. Maximum entropy inverse reinforcement learning[C]. Aaai. 2008, 8: 1433-1438. |
| 88 | BOULARIAS A, KOBER J, PETERS J. Relative entropy inverse reinforcement learning[C]. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, 2011: 182-189. |
| 89 | HO J, ERMON S. Generative adversarial imitation learning[J]. arXiv Preprint arXiv:, 2016. |
| 90 | YUAN M, PUN M O, CHEN Y. Hybrid adversarial inverse reinforcement learning[J]. arXiv Preprint arXiv:, 2021. |
| 91 | BACON P L, HARB J, PRECUP D. The option-critic architecture[C]. Proceedings of the AAAI Conference on Artificial Intelligence, 2017:1726-1734. |
| 92 | KULKARNI T D, NARASIMHAN K R, SAEEDI A, et al. Hierarchical deep reinforcement learning: integrating temporal abstraction and intrinsic motivation[C]. Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016: 3682-3690. |
| 93 | TESSLER C, GIVONY S, ZAHAVY T, et al. A deep hierarchical approach to lifelong learning in minecraft[J]. arXiv Preprint arXiv:, 2016. |
| 94 | SHI H, SUN Y, LI G.Intemittent control with reinforcement leaning[C]. 2017 International Conference on Progress in Informatics and Computing (PIC). IEEE, 2017: 56-60. |
| 95 | VEZHNEVETS A S, OSINDERO S, SCHAUL T, et al. Feudal networks for hierarchical reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2017: 3540-3549. |
| 96 | ANDRYCHOWICZ M, WOLSKI F, RAY A, et al. Hindsight experience replay[J]. arXiv Preprint arXiv:, 2017. |
| 97 | NACHUM O, GU S, LEE H, et al. Data-efficient hierarchical reinforcement learning[C]. Proceedings of the 32nd International Conference on Neural Information Processing Systems, 2018: 3307-3317. |
| 98 | LEVY A, KONIDARIS G, PLATT R, et al. Learning multi-level hierarchies with hindsight[J]. arXiv Preprint arXiv:, 2017. |
| 99 | SUKHBAATAR S, DENTON E, SZLAM A, et al. Learning goal embeddings via self-play for hierarchical reinforcement learning[J]. arXiv Preprint arXiv:, 2018. |
| 100 | EYSENBACH B, GUPTA A, IBARZ J, et al. Diversity is all you need: learning skills without a reward function[J]. arXiv Preprint arXiv: , 2018. |
| 101 | SHARMA A, GU S, LEVINE S, et al. Dynamics-aware unsupervised discovery of skills[J]. arXiv Preprint arXiv:, 2019. |
| 102 | SCHWEIGHOFER N, DOYA K. Meta-learning in reinforcement learning[J]. Neural Networks, 2003, 16(1):5-9. |
| 103 | DUAN Y, SCHULMAN J, CHEN X, et al. Rl $^2$: fast reinforcement learning via slow reinforcement learning[J]. arXiv Preprint arXiv:, 2016. |
| 104 | MISHRA N, ROHANINEJAD M, CHEN X, et al. A simple neural attentive meta-learner[J]. arXiv Preprint arXiv: , 2017. |
| 105 | KIRSCH L, VAN STEENKISTE S, SCHMIDHUBER J. Improving generalization in meta reinforcement learning using learned objectives[J]. arXiv Preprint arXiv:, 2019. |
| 106 | OH J, HESSEL M, CZARNECKI W M, et al. Discovering reinforcement learning algorithms[J]. Advances in Neural Information Processing Systems, 2020, 33: 1060-1070. |
| 107 | FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks[C]. International Conference on Machine Learning. PMLR, 2017: 1126-1135. |
| 108 | NICHOL A, ACHIAM J, SCHULMAN J. On first-order meta-learning algorithms[J]. arXiv Preprint arXiv: , 2018. |
| 109 | HOUTHOOFT R, CHEN R Y, ISOLA P, et al. Evolved policy gradients[C]. Proceedings of the 32nd International Conference on Neural Information Processing Systems, 2018: 5405-5414. |
| 110 | RAKELLY K, ZHOU A, FINN C, et al. Efficient off-policy meta-reinforcement learning via probabilistic context variables[C]. International Conference on Machine Learning. PMLR, 2019: 5331-5340. |
| 111 | FAKOOR R, CHAUDHARI P, SOATTO S, et al. Meta-q-learning[J]. arXiv Preprint arXiv: , 2019. |
| 112 | KUMAR A, FU J, TUCKER G, et al. Stabilizing off-policy Q-learning via bootstrapping error reduction[C]. Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019: 11784-11794. |
| 113 | WU Y, TUCKER G, NACHUM O. Behavior regularized offline reinforcement learning[J]. arXiv Preprint arXiv:, 2019. |
| 114 | AGARWAL R, SCHUURMANS D, NOROUZI M. An optimistic perspective on offline reinforcement learning[C]. International Conference on Machine Learning. PMLR, 2020: 104-114. |
| 115 | KUMAR A, ZHOU A, TUCKER G, et al. Conservative q-learning for offline reinforcement learning[J]. Advances in Neural Information Processing Systems, 2020, 33: 1179-1191. |
| 116 | KOSTRIKOV I, NAIR A, LEVINE S. Offline reinforcement learning with implicit Q-learning[J]. arXiv Preprint arXiv:, 2021. |
| 117 | BRANDFONBRENER D, WHITNEY W, RANGANATH R, et al. Offline rl without off-policy evaluation[J]. Advances in Neural Information Processing Systems, 2021, 34: 4933-4946. |
| 118 | PENG X B, KUMAR A, ZHANG G, et al. Advantage-weighted regression: simple and scalable off-policy reinforcement learning[J]. arXiv Preprint arXiv:, 2019. |
| 119 | NAIR A, DALAL M, GUPTA A, et al. Accelerating online reinforcement learning with offline datasets[J]. arXiv Preprint arXiv:, 2020. |
| 120 | KUMAR A, FU J, TUCKER G, et al. Stabilizing off-policy Q-learning via bootstrapping error reduction[J]. arXiv e-prints, 2019: arXiv: . |
| 121 | KUMAR A, ZHOU A, TUCKER G, et al. Conservative q-learning for offline reinforcement learning[J].Advances in Neural Information Processing Systems, 2020, 33: 1179-1191. |
| 122 | FERNANDO C, BANARSE D,BLUNDELL C, et al. PathNet: evolution channels gradient descent in super neural networks[J]. arXiv Preprint arXiv: 1701.08734,2017. |
| 123 | TEH Y W, BAPST V, CZARNECKI W M, et al. Distral: robust multitask reinforcement learning[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 4499-4509. |
| 124 | HESSEL M, SOYER H, ESPEHOLT L, et al. Multi-task deep reinforcement learning with PopArt[C]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019: 3796-3803. |
| 125 | TEH Y W, BAPST V, CZARNECKI W M, et al. Distral: robust multitask reinforcement learning[J]. arXiv Preprint arXiv:, 2017. |
| 126 | ESPEHOLT L, SOYER H, MUNOS R, et al. Impala: scalable distributed deep-rl with importance weighted actor-learner architectures[C]. International Conference on Machine Learning. PMLR, 2018: 1407-1416. |
| 127 | MEREL J, TASSA Y, TB D, et al. Learning human behaviors from motion capture by adversarial imitation[J]. arXiv Preprint arXiv:, 2017. |
| 128 | KUEFLER A, MORTON J, WHEELER T, et al. Imitating driver behavior with generative adversarial networks[C]. 2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017: 204-211. |
| 129 | YOU C, LU J, FILEV D, et al. Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning[J]. Robotics and Autonomous Systems, 2019, 114: 1-18. |
| 130 | WANG P, LI H, CHAN C Y. Meta-adversarial inverse reinforcement learning for decision-making tasks[C]. 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021: 12632-12638. |
| 131 | LIU J, BOYLE L N, BANERJEE A G. An inverse reinforcement learning approach for customizing automated lane change systems[J]. IEEE Transactions on Vehicular Technology, 2022, 71(9): 9261-9271. |
| 132 | CHEN J, WANG Z, TOMIZUKA M. Deep hierarchical reinforcement learning for autonomous driving with distinct behaviors[C]. 2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018: 1239-1244. |
| 133 | CHEN Y, DONG C, PALANISAMY P, et al. Attention-based hierarchical deep reinforcement learning for lane change behaviors in autonomous driving [C]. RSJ International Conference on Intelligent Robots and Systems (IROS), 2019: 3697-3703. |
| 134 | DUAN J, EBEN LI S, GUAN Y, et al. Hierarchical reinforcement learning for self‐driving decision‐making without reliance on labelled driving data[J]. IET Intelligent Transport Systems, 2020, 14(5): 297-305. |
| 135 | 吕超, 鲁洪良, 于洋, 等. 基于分层强化学习和社会偏好的自主超车决策系统[J]. 中国公路学报, 2022, 35(3): 115-126. |
| LV C, LU H L, YU Y, et al. Autonomous overtaking decision making system based on hierarchical reinforcement learning and social preferences[J]. China Journal of Highway and Transport,2022, 35(3): 115-126. | |
| 136 | QIAO Z, TYREE Z, MUDALIGE P, et al. Hierarchical reinforcement learning method for autonomous vehicle behavior planning[C]. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020: 6084-6089. |
| 137 | LUBARS J, GUPTA H, CHINCHALI S, et al. Combining reinforcement learning with model predictive control for on-ramp merging[C].2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021: 942-947. |
| 138 | BAI Z, HAO P, SHANGGUAN W, et al. Hybrid reinforcement learning-based eco-driving strategy for connected and automated vehicles at signalized intersections[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(9): 15850-15863. |
| 139 | SHI T, WANG P, CHENG X, et al. Driving decision and control for autonomous lane change based on deep reinforcement learning[J]. arXiv Preprint arXiv: , 2019. |
| 140 | NAVEED K B, QIAO Z, DOLAN J M. Trajectory planning for autonomous vehicles using hierarchical reinforcement learning[C]. 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021: 601-606. |
| 141 | YAVAS U, KUMBASAR T, URE N K. Model-based reinforcement learning for advanced adaptive cruise control: a hybrid car following policy[C]. 2022 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2022: 1466-1472. |
| 142 | JIANG J, REN Y, GUAN Y, et al. Integrated decision and control at multi-lane intersections with mixed traffic flow[C]. Journal of Physics: Conference Series. IOP Publishing, 2022, 2234(1): 012015. |
| 143 | 李升波. 混合型强化学习及其高级别自动驾驶应用[R]. 北京:北京智源大会自动驾驶论, 2022. |
| LI S B. Mixed reinforcement learning and its application in autonomous vehicle[R]. Beijing:BAAI Conference,2022. | |
| 144 | 李克强, 常雪阳, 李家文,等. 智能网联汽车云控系统及其实现[J]. 汽车工程, 2020, 42(12): 1595-1605. |
| LI K Q, CHANG X Y, LI J W, et al. Cloud control system for intelligent and connected vehicles and its application[J]. Automotive Engineering, 2020, 42(12): 1595-1605. |
| [1] | 付新科,蔡英凤,陈龙,王海,刘擎超. 不确定性环境下的自动驾驶汽车行为决策方法[J]. 汽车工程, 2024, 46(2): 211-221. |
| [2] | 赵晓聪,房世玉,李子睿,孙剑. 社会性驾驶交互关键效用析取与应用[J]. 汽车工程, 2024, 46(2): 230-240. |
| [3] | 马艳丽, 秦钦, 董方琦, 娄艺苧. 基于风险场的不同认知次任务下接管风险评估模型[J]. 汽车工程, 2024, 46(1): 9-17. |
| [4] | 刘卫国,项志宇,刘伟平,齐道新,王子旭. 基于分布式强化学习的车辆控制算法研究[J]. 汽车工程, 2023, 45(9): 1637-1645. |
| [5] | 王明,唐小林,杨凯,李国法,胡晓松. 考虑预测风险的自动驾驶车辆运动规划方法[J]. 汽车工程, 2023, 45(8): 1362-1372. |
| [6] | 朱向雷,吴志新,张宇飞,赵帅,李克秋,孙博华. 基于场景降维及采样方法的场景库优化方法研究[J]. 汽车工程, 2023, 45(8): 1408-1416. |
| [7] | 吴新政,邢星宇,刘力豪,沈勇,陈君毅. 基于错误注入的决策规划系统抗扰性测试与分析[J]. 汽车工程, 2023, 45(8): 1428-1437. |
| [8] | 高锋,冯德福,胡秋霞. 面向NMPC运动规划系统的数值优化加速技术[J]. 汽车工程, 2023, 45(8): 1438-1447. |
| [9] | 芦涛,金馨,廖毅霏,黄圣杰,杨依琳,谢国涛,秦晓辉. 基于雅克比域零空间边缘化的视觉SLAM[J]. 汽车工程, 2023, 45(8): 1457-1467. |
| [10] | 伍文广,田双岳,张志勇,张斌. 非铺装道路凹凸不平特征语义分割方法研究[J]. 汽车工程, 2023, 45(8): 1468-1478. |
| [11] | 林程, 汪博文, 吕沛原, 宫新乐, 于潇. 面向变曲率道路的自动驾驶汽车换道博弈运动规划与协同控制研究[J]. 汽车工程, 2023, 45(7): 1099-1111. |
| [12] | 赵东宇, 赵树恩. 基于级联YOLOv7的自动驾驶三维目标检测[J]. 汽车工程, 2023, 45(7): 1112-1122. |
| [13] | 李军, 周伟, 唐爽. 基于自适应拟合的智能车换道避障轨迹规划[J]. 汽车工程, 2023, 45(7): 1174-1183. |
| [14] | 赵嘉豪,齐志权,齐智峰,王皓,何磊. 基于轮胎特征点的并行大型车辆朝向角计算[J]. 汽车工程, 2023, 45(6): 1031-1039. |
| [15] | 陈妍妍,王海,蔡英凤,陈龙,李祎承. 基于检测的高效自动驾驶实例分割方法[J]. 汽车工程, 2023, 45(4): 541-550. |
|